



3.2 决策树
决策树模型长什么样子呢?如下图,就是每次一个节点判断特征,例如是否有胡子?是否是圆脸?是否有猫耳朵等等,最终判断出这个图片是猫猫的图片。
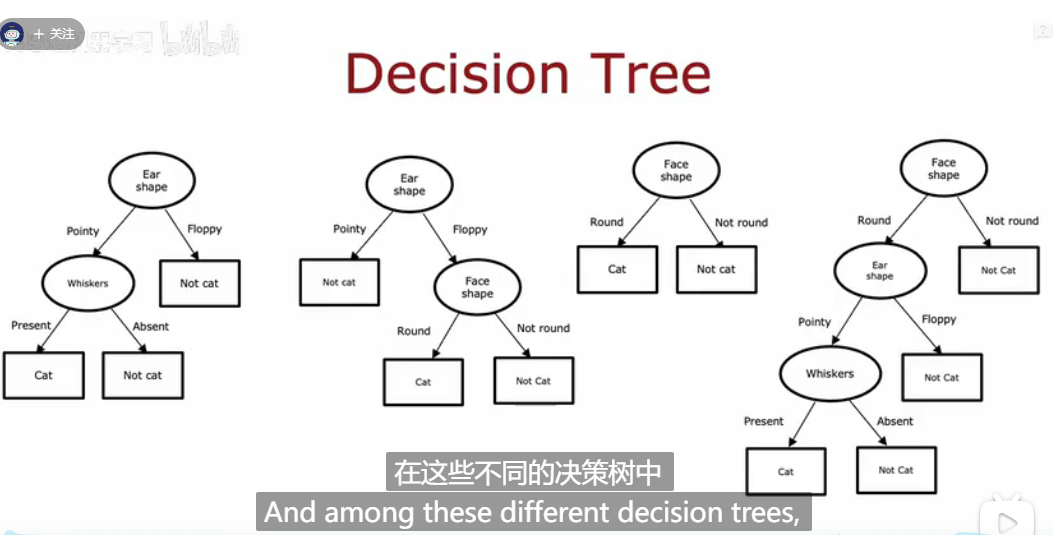
那如何构建一个决策树呢?
- 决定选择哪个特征作为区分的条件,这个要用最大纯度来判断,纯度就是指需要区分完两个子集要尽可能都是猫或者都是狗
- 什么时候停止生长?就是说决策树什么时候学习要停止,这个有多个方式选择。
停止学习的判断:
- 当这个子集全部是同一个类型,例如都是猫,就停止划分了
- 到达了这棵树最高的深度
- 这个子集的纯度已经足够低
- 这个子集里示例个数已经低于某个阈值
那如何判断一个集合的纯度呢?
纯度的话,就是指这个集合里目标的占比,例如下面猫的占比如下。计算完占比,我们可以用熵来判断这个纯度,例如3只猫,3只狗,它的纯度就最小,因为一半一半,所以他的熵最大,是1。

熵的计算函数如下:

信息增益判断这个节点需要选择哪个特征
用刚刚计算的熵,分别根据备选特征们划分完,之后各自计算他各自子集的熵,判断的标准是:熵越小越好,因为有多个熵,所以加权平均,得到一个新的信息增益,这个增益越大越好。

计算函数式:

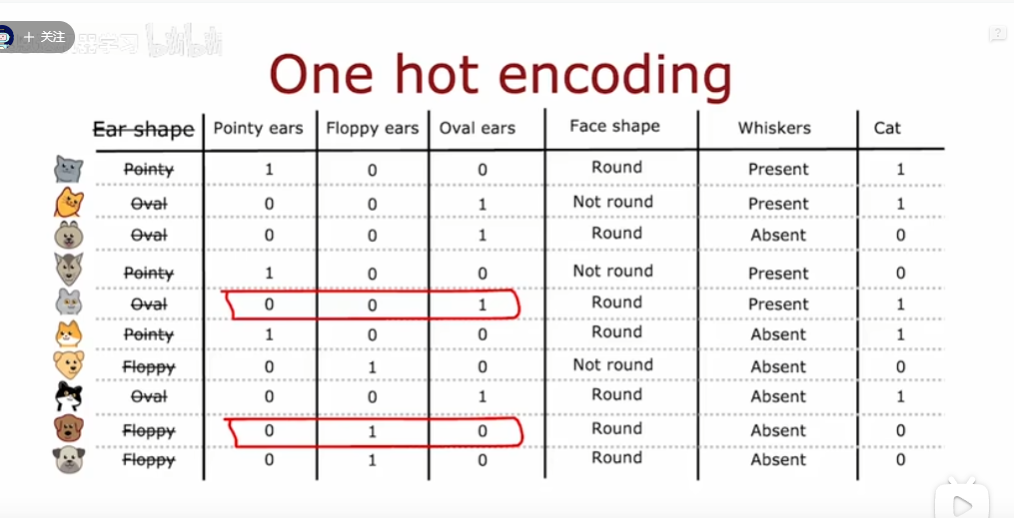
如果这个特征是有三类,可以用独热编码来处理
也就是将这三类作为三个特征,像下面耳朵三种形状,就变成三个是否是这个类型耳朵的特征即可
如果这个特征是连续值,要怎么处理呢?
可以像下面这样,选择不同的体重值,计算它的信息增益,选最大的那个就可以了

XGBoost实现


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









