






 本文详细介绍了Spring Cloud Gateway的工作原理,包括路由、断言、过滤器的概念及其配置方法,探讨了如何实现动态路由、限流及自定义过滤器,适用于微服务架构下的API网关设计。
本文详细介绍了Spring Cloud Gateway的工作原理,包括路由、断言、过滤器的概念及其配置方法,探讨了如何实现动态路由、限流及自定义过滤器,适用于微服务架构下的API网关设计。
核心概念
- 路由(route):路由是网关最基础的部分,路由信息由一个ID,一个目的URL,一组断言工厂和一组Filter组成,如果断言为真,则说明请求URL和配置的路由匹配根据一定的请求路径规则,找到对应的微服务,进行请求转发
- 断言(predicates) Java8中的断言函数,SpringCloudGateway中的断言函数输入类型是Spring5.0框架中的ServerWebExchange,Spring Cloud Gateway中的断言函数允许开发者去定义匹配来自HttpRequest中的任何信息,比如请求头和参数等路由执行的条件
- 过滤器(filter) 一个标准的Spring webFilter ,SpringCloudGateway中的Filter分为两种类型,分别是Gateway Filter(针对路由的过滤器)和Global Filter(针对全局的过滤器) 过滤器Filter可以对请求和响应进行处理
路由配置
搭建环境
- 创建工程导入坐标
需要父工程引入springcloud的坐标
<dependencies>
<!--springcloudgateway的内部是通过netty+ webfliux实现的,webflux实现和springmvc存在冲突 所以spring-boot-starter-web这个依赖不可以存在于gateway这个工程下,也就是不能继承过来->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>
- 配置启动类
启动类就是正常的启动类,不需要额外添加注解
- 编写配置文件
server:
port: 8080
spring:
application:
name: api-gateway-server # 服务名称
#配置Spring Cloud Gateway的路由
cloud:
gateway:
routes:
#配置路由: 路由id,路由到微服务的uri,断言(判断条件)
- id: product-service # 保持唯一
uri: http://127.0.0.1:9001 # 目标微服务请求地址
predicates:
- path=/product/** # 路径匹配原则
#访问127.0.0.1/product/1会被转发到http://127.0.0.1:9001/product/1这个url上
#这个gateway其实也是需要注册到eureka上的,在这里写注册到eureka上的配置
- 启动 如果启动报错 springmvc冲突什么的错误,就需要查看当前gateway模块下是否由spring-boot-starter-web这个依赖了,需要把这个依赖排除出去
<exclusions>
<exclusion>
<!--被排除的依赖包坐标-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</exclusion>
</exclusions>
路由规则(断言/路由条件)
# 路由断言 xxx时间之后匹配
spring:
cloud:
gateway:
routes:
- id: after_route
uri: https://xxxx.com
#路由断言之后匹配 在该日期时间之后发生的请求都将被匹配。
predicates:
- After=2017-01-20T17:42:47.789-07:00[America/Denver]
# 路由断言 xxx时间之前匹配
spring:
cloud:
gateway:
routes:
- id: before_route
uri: https://xxxx.com
#路由断言之前匹配 在该日期时间之前发生的请求都将被匹配。
predicates:
- Before=2017-01-20T17:42:47.789-07:00[America/Denver]
# 路由断言 xxx时间与xxx时间之间匹配
spring:
cloud:
gateway:
routes:
- id: between_route
uri: https://xxxx.com
#路由断言之前匹配 在该日期时间之前发生的请求都将被匹配。
predicates:
# 两个时间中间用,分隔
- Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
# cookie路由断言
spring:
cloud:
gateway:
routes:
- id: cookie_route
uri: https://xxxx.com
#Cookie 路由断言有两个参数,cookie名称和正则表达式。请求包含次cookie名称且正则表达式为真的将会被匹配。
predicates:
# 两个时间中间用,分隔
- Cookie=chocolate, ch.p
# Header 路由断言
spring:
cloud:
gateway:
routes:
- id: header_route
uri: https://xxxx.com
#Header 路由断言 Factory有两个参数,header名称和正则表达式。请求包含次header名称且正则表达式为真的将会被匹配。
predicates:
# 两个时间中间用,分隔
- Header=X-Request-Id, \d+
# Host 路由断言
spring:
cloud:
gateway:
routes:
- id: host_route
uri: https://xxxx.com
#Host 路由断言 Factory包括一个参数:host name列表。使用Ant路径匹配规则, ,作为分隔符。
predicates:
# 两个时间中间用,分隔
- Host=**.somehost.org,**.anotherhost.org
# Method 路由断言
spring:
cloud:
gateway:
routes:
- id: method_route
uri: https://xxxx.com
#Method 路由断言 Factory只包含一个参数: 需要匹配的HTTP请求方式
predicates:
# 两个时间中间用,分隔
- Method=GET
# Path 路由断言
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://xxxx.com
#Method 路由断言 Factory只包含一个参数: 需要匹配的HTTP请求方式
predicates:
# Path 路由断言 Factory 有2个参数: 一个Spring PathMatcher表达式列表和可选matchOptionalTrailingSeparator标识 .
- Path=/foo/{segment},/bar/{segment}
# 例如: /foo/1 or /foo/bar or /bar/baz的请求都将被匹配 URI 模板变量 (如上例中的 segment ) 将以Map的方式保存于ServerWebExchange.getAttributes() key为ServerWebExchangeUtils.URI_TEMPLATE_VARIABLES_ATTRIBUTE. 这些值将在GatewayFilter Factories使用
# 可以在Filter中 使用以下方法来更方便地访问这些变量。
Map<String, String> uriVariables = ServerWebExchangeUtils.getPathPredicateVariables(exchange);
String segment = uriVariables.get("segment");
# Query 路由断言
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://xxxx.com
#Method 路由断言 Factory只包含一个参数: 需要匹配的HTTP请求方式
predicates:
# Query 路由断言 Factory 有2个参数: 必选项 param 和可选项 regexp.
- Query=baz
# 包含了请求参数 baz的都将被匹配。
- Query=foo, ba.
# 如果请求参数里包含foo参数,并且值匹配为ba. 正则表达式,则将会被路由,如:bar and baz
# RemoteAddr 路由断言
spring:
cloud:
gateway:
routes:
- id: path_route
uri: https://xxxx.com
#Method 路由断言 Factory只包含一个参数: 需要匹配的HTTP请求方式
predicates:
# RemoteAddr 路由断言 Factory的参数为 一个CIDR符号(IPv4或IPv6)字符串的列表,最小值为1,例如192.168.0.1/16(其中192.168.0.1是IP地址并且16是子网掩码)。
- RemoteAddr=192.168.1.1/24
# 如果请求的remote address 为 192.168.1.10则将被路由
# 如果上一层配置了nginx 可能会有一些变化,具体的百度一下 Gateway的修改远程地址的解析方式
动态路由配置(面向服务的路由)
- 引入Eureka相关依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
- 启动类添加服务发现注解
@EnableEurekaClient
- yml配置文件增加Eureka配置
# 注册中心的配置信息
eureka:
client:
service-url:
defaultZone: http://localhost:9000/eureka/
instance:
prefer-ip-address: true #使用ip地址注册
# 更改gateway配置
server:
port: 8080
spring:
application:
name: api-gateway-server # 服务名称
#配置Spring Cloud Gateway的路由
cloud:
gateway:
routes:
#配置路由: 路由id,路由到微服务的uri,断言(判断条件)
- id: product-service # 保持唯一
uri: lb://service-product(这个是微服务名称) # 根据微服务名称从注册中心中拉取服务请求路径
predicates:
- path=/product/** # 路径匹配原则
重写转发路径
需要配置一个路由过滤器器
server:
port: 8080
spring:
application:
name: api-gateway-server # 服务名称
#配置Spring Cloud Gateway的路由
cloud:
gateway:
routes:
#配置路由: 路由id,路由到微服务的uri,断言(判断条件)
- id: product-service # 保持唯一
uri: lb://service-product(这个是微服务名称) # 根据微服务名称从注册中心中拉取服务请求路径
predicates:
- path=/product/** # 路径匹配原则
filters: # 配置路由过滤器 http://localhost:8080/product-service/product/1 --> http://127.0.0.1:9001/product/1
在yml中 $ 写成$\
- RewritePath=/product-service/(?<segment>.*),/$\{segment}
微服务名称转发
可以配置自动的根据微服务名称进行路由转发
server:
port: 8080
spring:
application:
name: api-gateway-server # 服务名称
#配置Spring Cloud Gateway的路由
cloud:
gateway:
routes:
#配置路由: 路由id,路由到微服务的uri,断言(判断条件)
- id: product-service # 保持唯一
#uri: lb://service-product(这个是微服务名称) # 根据微服务名称从注册中心中拉取服务请求路径
#predicates:
#- path=/product/** # 路径匹配原则
#filters: # 配置路由过滤器 http://localhost:8080/product-service/product/1 --> http://127.0.0.1:9001/product/1
#在yml中 $ 写成$\
#- RewritePath/product-service/(?<segment>.*),/$\{segmemt}
# 配置自动根据微服务名称进行路由转发 http://localhost:8080/{微服务id}/product/1
discovery:
locator:
enable: true #开启根据服务名称自动转发
lower-case-service-id: true # 微服务名称已小写形式出现
过滤器
过滤器基础
- 过滤器的生命周期
SpringCloud Gateway的Filter的生命周期不像Zuul的那么丰富,它只有两个: “pre"和"post”
- pre: 这种过滤器在请求被路由之前调用,我们可利用这种过滤器实现 身份验证,在集群中选择请求的微服务 , 记录调试信息 等
- post: 这种过滤器在路由到微服务以后执行,这种过滤器可以用来为响应 添加标准的HTTP Header,收集统计信息和指标,将响应从微服务发送给客户端等
- 过滤器类型
- GatewayFilter: 应用到单个路由或者一个分组的路由上
- GlobalFilter: 应用到所有路由上
局部过滤器
局部过滤器,是针对单个路由的过滤器,可以对访问的URL过滤,进行切面处理,在SpringCloudGateway中通过GatewayFilter的形式内置了很多不同类型的局部过滤器,
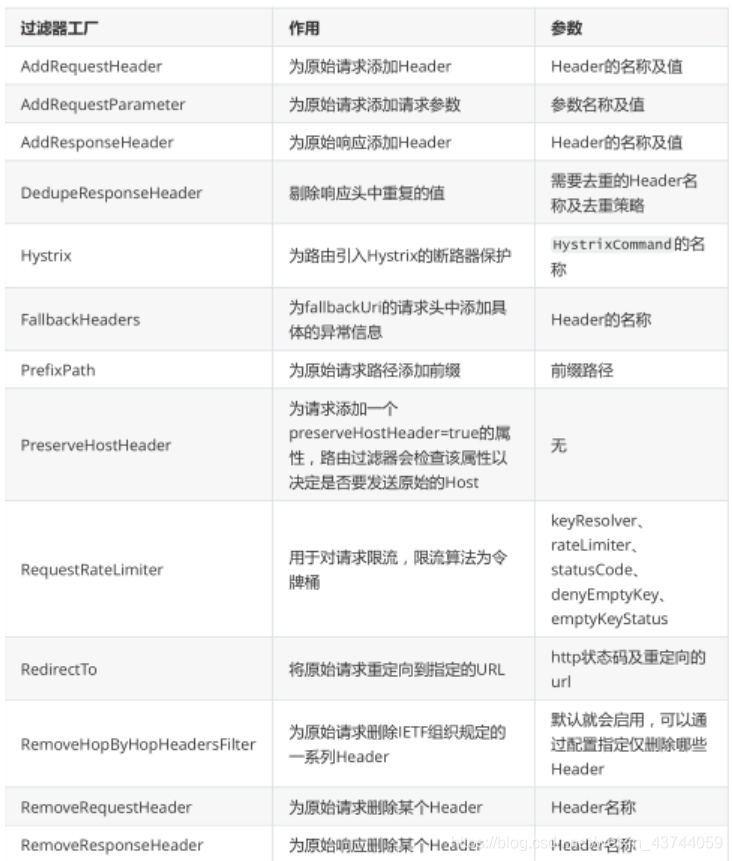
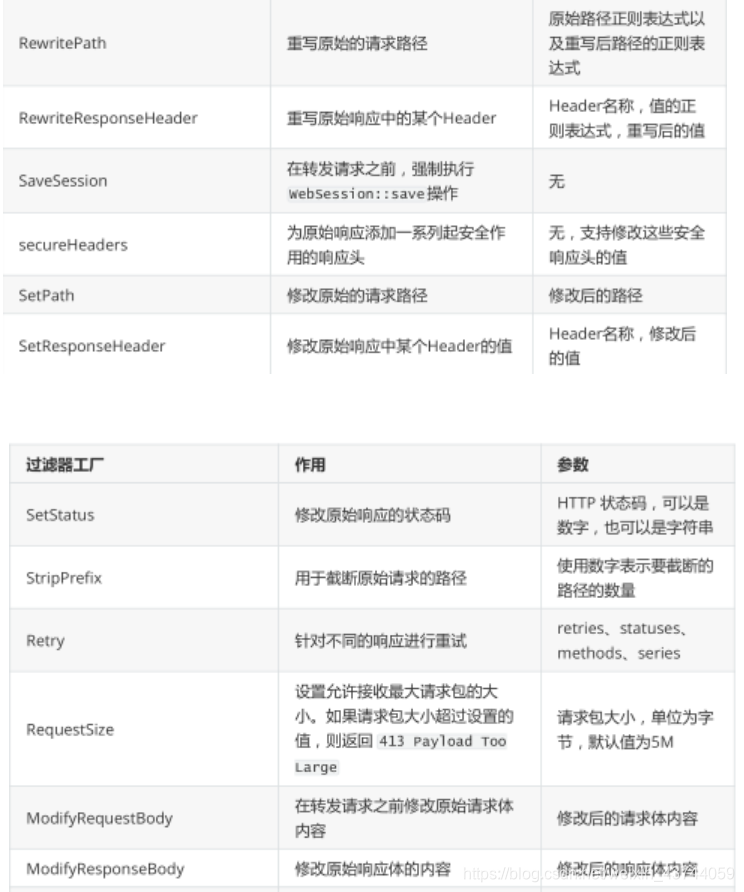
每个过滤器工厂都对应一个实现类,并且这些类的名称必须以 GatewayFilterFactory 结尾,这是
Spring Cloud Gateway的一个约定,例如 AddRequestHeader 对应的实现类为
AddRequestHeaderGatewayFilterFactory 。对于这些过滤器的使用方式可以参考官方文档
全局过滤器
全局过滤器(GlobalFilter)作用于所有路由,Spring Cloud Gateway 定义了Global Filter接口,用户
可以自定义实现自己的Global Filter。通过全局过滤器可以实现对权限的统一校验,安全性验证等功
能,并且全局过滤器也是程序员使用比较多的过滤器。
Spring Cloud Gateway内部也是通过一系列的内置全局过滤器对整个路由转发进行处理如下:
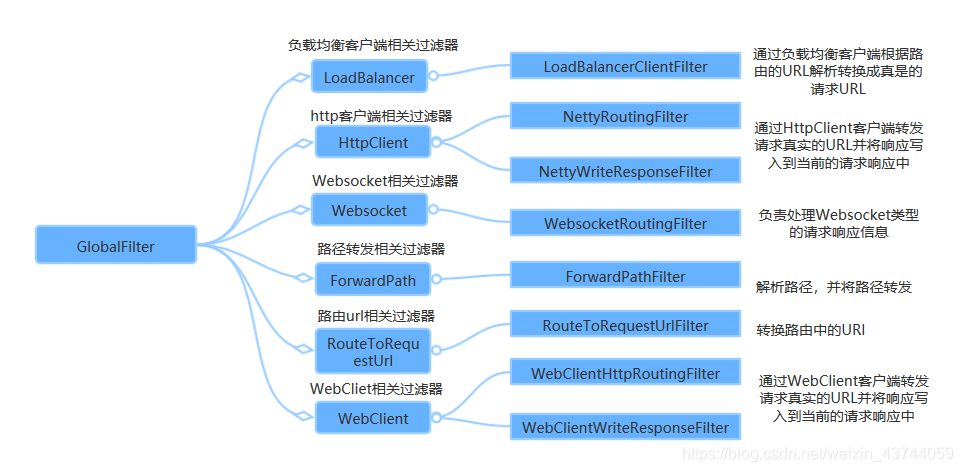
自定义全局过滤器(这个类需要加上注解@Component),需要实现GlobalFilter和Ordered接口并实现他们的方法
filter方法执行过滤器中的业务逻辑
getOrder方法指定过滤器的执行顺序,返回值越小,执行的优先级越高

统一鉴权
内置的过滤器已经可以完成大部分的功能,但是对于企业开发的一些业务功能处理,还是需要我们自己
编写过滤器来实现的,那么我们一起通过代码的形式自定义一个过滤器,去完成统一的权限校验。
开发中的鉴权逻辑
- 当客户端第一次请求服务时,服务端对用户进行信息认证(登录)
- 认证通过,将用户信息进行加密形成 token,返回给客户端,作为登录凭证
- 以后每次请求,客户端都携带认证的 token
- 服务端对 token进行解密,判断是否有效
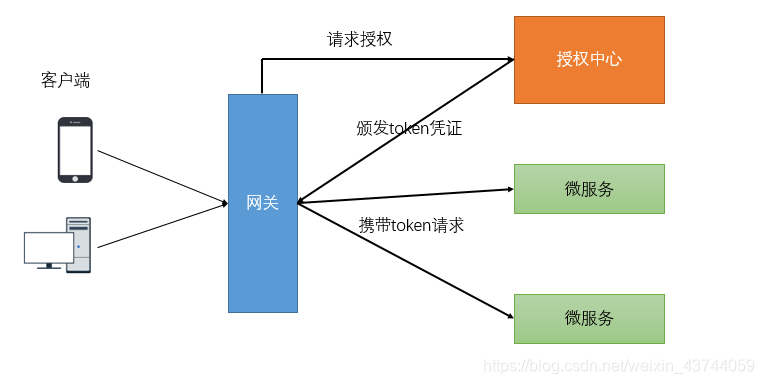
如上图,对于验证用户是否已经登录鉴权的过程可以在网关层统一检验。检验的标准就是请求中是否携
带token凭证以及token的正确性。
/**
* 自定义一个全局过滤器
* 实现 globalfilter , ordered接口
*/
@Component
public class LoginFilter implements GlobalFilter,Ordered {
/**
* 执行过滤器中的业务逻辑
* 对请求参数中的access-token进行判断
* 如果存在此参数:代表已经认证成功
* 如果不存在此参数 : 认证失败.
* ServerWebExchange : 相当于请求和响应的上下文(zuul中的RequestContext)
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
System.out.println("执行了自定义的全局过滤器");
//1.获取请求参数access-token
String token = exchange.getRequest().getQueryParams().getFirst("access-token");
//2.判断是否存在
if(token == null) {
//3.如果不存在 : 认证失败
System.out.println("没有登录");
//设置响应码为未认证
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
return exchange.getResponse().setComplete(); //请求结束,不往下走了
}
//4.如果存在,继续执行
return chain.filter(exchange); //继续向下执行
}
/**
* 指定过滤器的执行顺序 , 返回值越小,执行优先级越高
*/
@Override
public int getOrder() {
return 0;
}
}
网关限流
常见限流算法
- 计数器
计数器限流算法是最简单的一种限流实现方式,其本质是通过维护一个单位时间内的计数器,每次请求计数器加1,当单位时间内计数器累加大于设定的阙值,之后的所有请求都被拒绝,知道单位时间已经过去,再将计数器重置为0
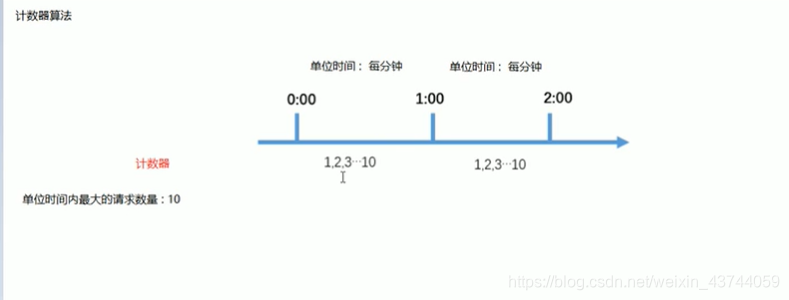
缺点: 对流量限制不是平滑的过程,如果刚开始很大一部分请求过来了,后面的时间内全都拦截住不让其向后请求了比如第10秒时已经达到阙值了,后面的50秒就什么都做不了了 - 漏桶算法
漏桶算法可以很好的 限制容量池的大小,从而防止流量暴增,漏桶可以看做是一个带有常量服务时间的单服务器队列,如果漏桶溢出,那么数据包会被丢弃,在网络中,漏桶算法可以控制端口的流量输出速率,平滑网络上的突发流量,实现流量整形,从而为网络提供一个稳定的流量
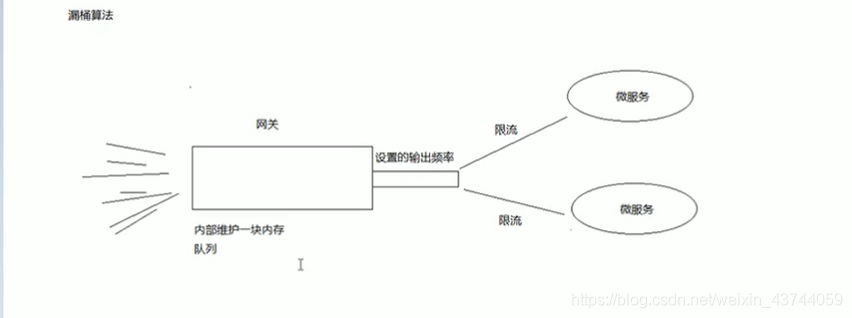
为了更好的控制流量,漏桶算法需要通过两个变量进行控制: 一个是桶的大小,支持流量突发增多时可以存多少水,另一个是水桶漏洞的大小 - 令牌桶算法
令牌桶算法是对漏桶算法的一种改进,桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用的平均速率的同时还允许一定程度的突发调用,在令牌桶算法中,存在一个桶,用来存放固定数量的令牌.算法中存在一种机制,以一定的速率往桶中放令牌.每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌,或者直接拒绝.放令牌这个动作是持续不断的进行,如果桶中令牌数量达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行,比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,这时服务还没偶完全启动好,等启动完成对外提供服务时,该限流器可以抵挡瞬间的100个请求,所以,只有桶中没有令牌是,请求才会进行等待,最后相当于以一定的速率执行
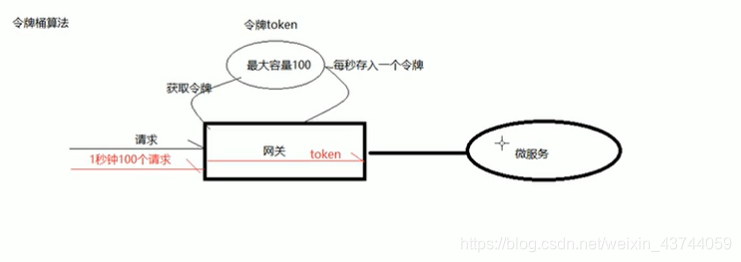
在网关中限流,使用的就是令牌桶算法
基于Filter的限流
SpringCloudGateway官方提供了基于令牌桶的限流支持,基于其内置的过滤器工厂RequestRateLimiterGatewayFilterFactory实现,在过滤器工厂中是通过Redis和lua脚本结合的方式进行流量控制
- 准备工作 Redis 在工程中引入Redis相关依赖:基于reactive的redis依赖
<!--监控依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
- 修改网关中的application.yml配置文件
# 添加redis配置文件
server:
port: 8080
spring:
application:
name: api-gateway-server # 服务名称
redis:
host: localhost
pool: 6379
database: 0
#配置Spring Cloud Gateway的路由
cloud:
gateway:
routes:
#配置路由: 路由id,路由到微服务的uri,断言(判断条件)
- id: product-service # 保持唯一
uri: lb://service-product(这个是微服务名称) # 根据微服务名称从注册中心中拉取服务请求路径
predicates:
- path=/product-service/** # 路径匹配原则
filters: # 配置限流过滤器
- name: RequestRateLimiter
args:
#使用SpEL从容器中获取对象
key-resolver: '#{@pathKeyResolver}'
#令牌桶每秒填充平均速率
redis-rate-limiter.replenishRate: 1
#令牌桶的上限
redis-rate-limiter.burstCapacity: 3
-RewritePath=/product-service/(?<segment>.*),/$\{segment}
# RequestRateLimiter : 使用限流过滤器,是springcloudgateway提供的
# 参数去 RequestRateLimiter GatewayFilterFactory.class中找
# replenishRate:向令牌桶中填充的速率
# burstCapacity:令牌桶的容量
- 配置一个Redis中Key的解析器 KeySesolverConfiguration
@Configuration
public class KeyResolverConfiguration{
/**
* 编写基于请求路径的限流规则 //abc
* 基于请求ip 127.0.0.1
* 基于参数的
*/
@Bean
public KeyResolver pathKeyResolver(){
return new keyResolver(){
//ServletWebExchange就是上下文参数,可以得到根据什么进行限流
public Mono<String> resolve(SserverWebExchange exchange){
//根据路径进行限流
return Mono.just(exchange.getRequest().getPath().toString());
}
};
}
//基于请求参数的限流,简单写法.请求abc?userId=1 对参数的限流 请求userId=1的时候只能每秒请求3次,多于3次请求不到(根据令牌桶大小和每秒放入桶内数据个数而定)
@Bean
public KeyResolver userKeyResolver(){
return exchange -> Mono.just(exchange.getRequest().getQueryParams().getFirst("userId"));
}
}
//基于请求ip的限流
@Bean
public KeyResolver ipKeyResolver(){
return exchange -> Mono.just(exchange.getRequest().getHeaders().getFirst("X-Forwarded-For"));
}
}
基于Sentinel的限流
网关的高可用
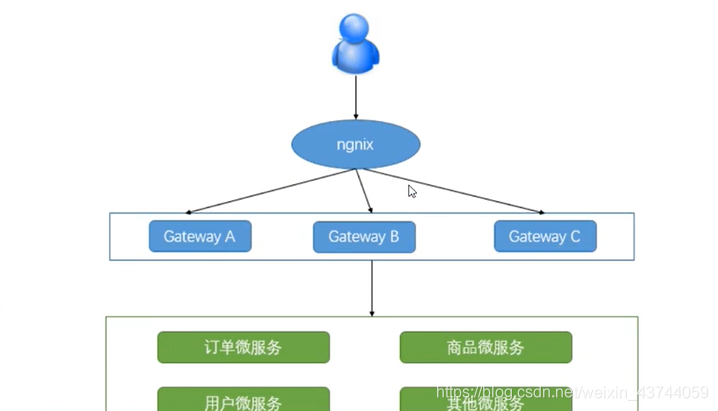
upstream gateway{
server 127.0.0.1:8081;
server 127.0.0.1:8080;
}
server{
listen 80;
server_name localhost;
}
location / {
proxy_pass http://gateway;
}

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









