




 文章介绍了如何按照不同的规则对CTB系列数据集(如CTB5、CTB7、CTB8、CTB9)进行训练集、验证集和测试集的划分,特别是何晗提出的CTB8&CTB9的拆分方案,旨在解决样本遗漏、不均衡和复杂性问题。HanLP提供的工具make_ctb用于制作NLP任务的标准数据集,包括词性标注和依存解析等任务。建议在Linux环境下运行此代码。
文章介绍了如何按照不同的规则对CTB系列数据集(如CTB5、CTB7、CTB8、CTB9)进行训练集、验证集和测试集的划分,特别是何晗提出的CTB8&CTB9的拆分方案,旨在解决样本遗漏、不均衡和复杂性问题。HanLP提供的工具make_ctb用于制作NLP任务的标准数据集,包括词性标注和依存解析等任务。建议在Linux环境下运行此代码。
ctb系列数据集划分训练集、验证集、测试集
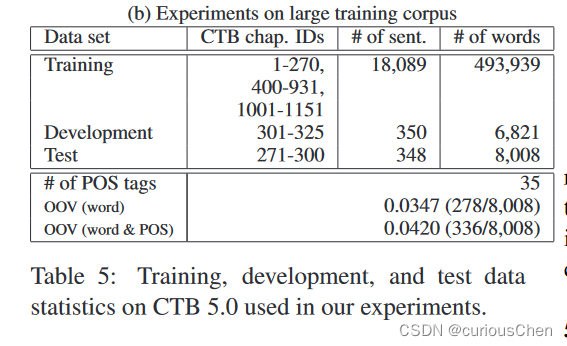
ctb5
- Kruengkrai, Canasai, Kiyotaka Uchimoto, Jun’ichi Kazama, Yiou Wang, Kentaro Torisawa和Hitoshi Isahara. 《An Error-Driven Word-Character Hybrid Model for Joint Chinese Word Segmentation and POS Tagging》. 收入 Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 513–21. Suntec, Singapore: Association for Computational Linguistics, 2009. https://aclanthology.org/P09-1058.
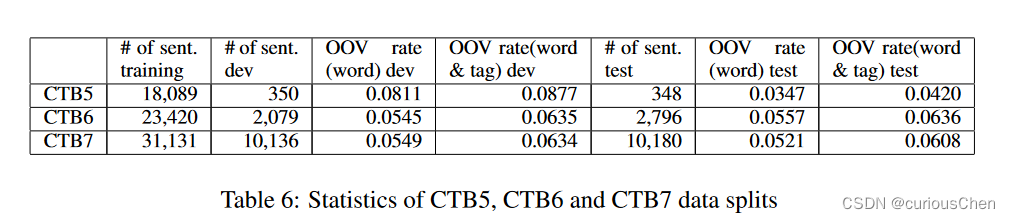
CTB7
-
Wang, Yiou, Jun Kazama, Yoshimasa Tsuruoka, Wenliang Chen, Yujie Zhang和Kentaro Torisawa. 《Improving Chinese Word Segmentation and POS Tagging with Semi-supervised Methods Using Large Auto-Analyzed Data》, 2011.
-

-

-
ctb8 & ctb9
- Shao, Yan, Christian Hardmeier, Jörg Tiedemann和Joakim Nivre. 《Character-based Joint Segmentation and POS Tagging for Chinese using Bidirectional RNN-CRF》. 收入 Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 173–83. Taipei, Taiwan: Asian Federation of Natural Language Processing, 2017. https://aclanthology.org/I17-1018.
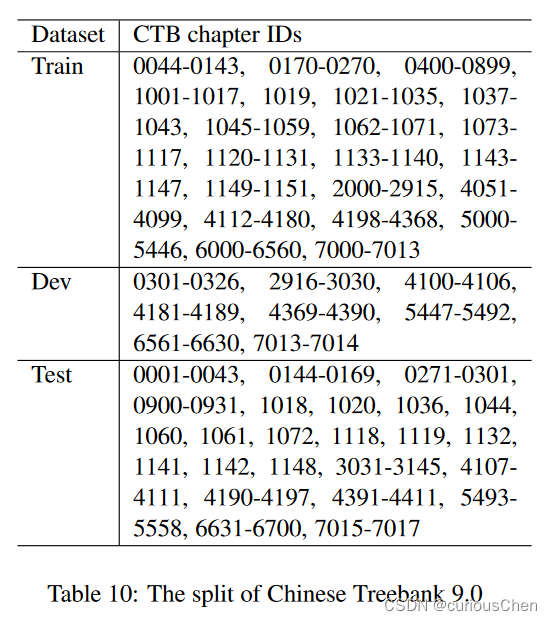
CTB8 & CTB9 (何晗大佬倡导)
-
https://bbs.hankcs.com/t/topic/3024
-
每个文件以8结尾的划入开发集,以9结尾的划入测试集,否则划入训练集
-
ctb9的拆分在学术界已有定论,根据IJCNLP 2017上Shao et. al的论文,ctb9拆分遗漏了51个文件,亦即
4000-4050这个区间。而且该拆分在各个领域(genre)上的分布比较不均匀。ctb9一共8个领域,分别为:- nw 新闻
- mz 杂志
- bn 广播新闻
- bc 广播访谈
- wb 博客
- df 论坛
- sc 短信
- cs 聊天
-
在这些领域上,学术界拆分导致的文件数统计如下:
-
Shao et. al (2017) 拆分统计
-
genre train dev test nw 604(79.47%) 25(3.29%) 131(17.24%) mz 117(90.00%) 0(0.00%) 13(10.00%) bn 965(79.95%) 122(10.11%) 120(9.94%) bc 69(80.23%) 9(10.47%) 8(9.30%) wb 171(79.91%) 22(10.28%) 21(9.81%) df 447(79.96%) 46(8.23%) 66(11.81%) sc 561(80.03%) 70(9.99%) 70(9.99%) cs 14(77.78%) 1(5.56%) 3(16.67%)
-
-
考虑到上述样本遗漏、样本不均衡以及拆分规则复杂的问题,HanLP提出如下拆分,推荐给工业界和开源界人士:
-
每个文件以8结尾的划入开发集,以9结尾的划入测试集,否则划入训练集。
-
这个简单直白的划分不仅操作简单,而且能够保证各个领域的均衡比例。该划分的统计信息如下
-
-
genre train dev test nw 655(80.76%) 78(9.62%)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









