






MapJoin
Map Join
作用
▁▁▁和▁▁▁关联查询时,提升性能,避免数据倾斜。
触发条件
-- 1、开启MapJoin set hive.auto.convert.join=true; -- 2、设置阈值,不要超出自己的硬件配置,否则内存溢出 set hive.auto.convert.join.noconditionaltask.size=512000000
Bucket-Map Join
作用
▁▁▁和▁▁▁关联(小表的数据大小超出阈值)时,使用Map端Join优化。
触发条件
1) 开启配置:set hive.optimize.bucketmapjoin = true; 2) 一个表的bucket数是另一个表bucket数的整数倍 3) bucket列 == join列 4) 满足map join条件
SMB Join
作用
当▁▁▁和▁▁▁关联(关联的两个表数据都很大)时使用。
触发条件
-
开启SMB配置
set hive.optimize.bucketmapjoin = true; set hive.auto.convert.sortmerge.join=true; set hive.optimize.bucketmapjoin.sortedmerge = true; set hive.auto.convert.sortmerge.join.noconditionaltask=true;
-
bucket列 == join列,且要Sort此列
-
创建表时,sorted by (列);
-
插入数据时:
-
cluster by (列);
-
hive.enforce.sorting 设置为 true
-
-
-
两个表的bucket数必须相等
-
满足BucketMapJoin的条件
DWB
基础数据层,降维冗余,形成宽表,作用:▁▁▁▁▁▁。
订单明细宽表
建表
合并表,形成宽表:▁▁▁▁▁▁▁▁▁▁▁▁减少join、作为中间数据、提升性能
重复的字段、无用的字段,可以舍弃;
DROP TABLE if EXISTS yp_dwb.dwb_order_detail;
CREATE TABLE yp_dwb.dwb_order_detail(
order_id string COMMENT '根据一定规则生成的订单编号',
order_num string COMMENT '订单序号',
buyer_id string COMMENT '买家userId',
store_id string COMMENT '店铺的id',
order_from string COMMENT '渠道类型:android、ios、miniapp、pcweb、other',
order_state int COMMENT '订单状态:1.已下单\; 2.已付款, 3. 已确认 \;4.配送\; 5.已完成\; 6.退款\;7.已取消',
create_date string COMMENT '下单时间',
finnshed_time timestamp COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价',
is_settlement tinyint COMMENT '是否结算\;0.待结算订单\; 1.已结算订单\;',
is_delete tinyint COMMENT '订单评价的状态:0.未删除\; 1.已删除\;(默认0)',
evaluation_state tinyint COMMENT '订单评价的状态:0.未评价\; 1.已评价\;(默认0)',
way string COMMENT '取货方式:SELF自提\;SHOP店铺负责配送',
is_stock_up int COMMENT '是否需要备货 0:不需要 1:需要 2:平台确认备货 3:已完成备货 4平台已经将货物送至店铺 ',
-- 订单副表
order_amount decimal(36,2) COMMENT '订单总金额:购买总金额-优惠金额',
discount_amount decimal(36,2) COMMENT '优惠金额',
goods_amount decimal(36,2) COMMENT '用户购买的商品的总金额+运费',
is_delivery string COMMENT '0.自提;1.配送',
buyer_notes string COMMENT '买家备注留言',
pay_time string,
receive_time string,
delivery_begin_time string,
arrive_store_time string,
arrive_time string COMMENT '订单完成时间,当配送员点击确认送达时,进行更新订单完成时间,后期需要根据订单完成时间,进行自动收货以及自动评价',
create_user string,
create_time string,
update_user string,
update_time string,
is_valid tinyint COMMENT '是否有效 0: false\; 1: true\; 订单是否有效的标志',
-- 订单组
group_id string COMMENT '订单分组id',
is_pay tinyint COMMENT '订单组是否已支付,0未支付,1已支付',
-- 订单组支付
group_pay_amount decimal(36,2) COMMENT '订单总金额\;',
-- 退款单
refund_id string COMMENT '退款单号',
apply_date string COMMENT '用户申请退款的时间',
refund_reason string COMMENT '买家退款原因',
refund_amount decimal(36,2) COMMENT '订单退款的金额',
refund_state tinyint COMMENT '1.申请退款\;2.拒绝退款\; 3.同意退款,配送员配送\; 4:商家同意退款,用户亲自送货 \;5.退款完成',
-- 结算单
settle_id string COMMENT '结算单号',
settlement_amount decimal(36,2) COMMENT '如果发生退款,则结算的金额 = 订单的总金额 - 退款的金额',
dispatcher_user_id string COMMENT '配送员id',
dispatcher_money decimal(36,2) COMMENT '配送员的配送费(配送员的运费(如果退货方式为1:则买家支付配送费))',
circle_master_user_id string COMMENT '圈主id',
circle_master_money decimal(36,2) COMMENT '圈主分润的金额',
plat_fee decimal(36,2) COMMENT '平台应得的分润',
store_money decimal(36,2) COMMENT '商家应得的订单金额',
status tinyint COMMENT '0.待结算;1.待审核 \; 2.完成结算;3.拒绝结算',
settle_time string COMMENT ' 结算时间',
-- 订单评价
evaluation_id string,
evaluation_user_id string COMMENT '评论人id',
geval_scores int COMMENT '综合评分',
geval_scores_speed int COMMENT '送货速度评分0-5分(配送评分)',
geval_scores_service int COMMENT '服务评分0-5分',
geval_isanony tinyint COMMENT '0-匿名评价,1-非匿名',
evaluation_time string,
-- 订单配送
delievery_id string COMMENT '主键id',
dispatcher_order_state tinyint COMMENT '配送订单状态:0.待接单.1.已接单,2.已到店.3.配送中 4.商家普通提货码完成订单.5.商家万能提货码完成订单。6,买家完成订单',
delivery_fee decimal(36,2) COMMENT '配送员的运费',
distance int COMMENT '配送距离',
dispatcher_code string COMMENT '收货码',
receiver_name string COMMENT '收货人姓名',
receiver_phone string COMMENT '收货人电话',
sender_name string COMMENT '发货人姓名',
sender_phone string COMMENT '发货人电话',
delievery_create_time string,
-- 商品快照
order_goods_id string COMMENT '-- 商品快照id',
goods_id string COMMENT '购买商品的id',
buy_num int COMMENT '购买商品的数量',
goods_price decimal(36,2) COMMENT '购买商品的价格',
total_price decimal(36,2) COMMENT '购买商品的价格 = 商品的数量 * 商品的单价 ',
goods_name string COMMENT '商品的名称',
goods_specification string COMMENT '商品规格',
goods_type string COMMENT '商品分类 ytgj:进口商品 ytsc:普通商品 hots爆品',
goods_brokerage decimal(36,2) COMMENT '商家设置的商品分润的金额',
is_goods_refund tinyint COMMENT '0.不退款\; 1.退款'
)
COMMENT '订单明细表'
PARTITIONED BY(dt STRING)
row format delimited fields terminated by '\t'
stored as orc
tblproperties ('orc.compress' = 'SNAPPY');
实现
插入数据时,动态分区越多,性能越▁▁▁慢。
-- 开启mapjoin
set hive.auto.convert.join=true;
-- 写入数据强制分桶
set hive.enforce.bucketing=true;
-- 写入数据强制排序
set hive.enforce.sorting=true;
-- 开启bucketmapjoin
set hive.optimize.bucketmapjoin = true;
-- 开启SMB Join
set hive.optimize.bucketmapjoin.sortedmerge=true;
set hive.auto.convert.sortmerge.join=true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
insert into yp_dwb.dwb_order_detail partition (dt)
select
o.id as order_id,
o.order_num,
o.buyer_id,
o.store_id,
o.order_from,
o.order_state,
o.create_date,
o.finnshed_time,
o.is_settlement,
o.is_delete,
o.evaluation_state,
o.way,
o.is_stock_up,
od.order_amount,
od.discount_amount,
od.goods_amount,
od.is_delivery,
od.buyer_notes,
od.pay_time,
od.receive_time,
od.delivery_begin_time,
od.arrive_store_time,
od.arrive_time,
od.create_user,
od.create_time,
od.update_user,
od.update_time,
od.is_valid,
og.group_id,
og.is_pay,
op.order_pay_amount as group_pay_amount,
refund.id as refund_id,
refund.apply_date,
refund.refund_reason,
refund.refund_amount,
refund.refund_state,
os.id as settle_id,
os.settlement_amount,
os.dispatcher_user_id,
os.dispatcher_money,
os.circle_master_user_id,
os.circle_master_money,
os.plat_fee,
os.store_money,
os.status,
os.settle_time,
e.id,
e.user_id,
e.geval_scores,
e.geval_scores_speed,
e.geval_scores_service,
e.geval_isanony,
e.create_time,
d.id,
d.dispatcher_order_state,
d.delivery_fee,
d.distance,
d.dispatcher_code,
d.receiver_name,
d.receiver_phone,
d.sender_name,
d.sender_phone,
d.create_time,
ogoods.id as order_goods_id,
ogoods.goods_id,
ogoods.buy_num,
ogoods.goods_price,
ogoods.total_price,
ogoods.goods_name,
ogoods.goods_specification,
ogoods.goods_type,
ogoods.goods_brokerage,
ogoods.is_refund as is_goods_refund,
SUBSTRING(o.create_date,1,10) as dt
-- 订单表
from yp_dwd.fact_shop_order o
-- 订单副表
left join yp_dwd.fact_shop_order_address_detail od on o.id = od.id and od.end_date='9999-99-99'
-- 订单组表
left join yp_dwd.fact_shop_order_group og on o.id = og.order_id and og.end_date='9999-99-99'
-- 订单组支付表
left join yp_dwd.fact_order_pay op on og.group_id = op.group_id
-- 退款单表
left join yp_dwd.fact_refund_order refund on refund.order_id=o.id and refund.end_date='9999-99-99'
-- 结算单表
left join yp_dwd.fact_order_settle os on os.order_id=o.id and os.end_date='9999-99-99'
-- 订单商品快照
left join yp_dwd.fact_shop_order_goods_details ogoods on ogoods.order_id=o.id and ogoods.end_date='9999-99-99'
-- 订单评价表
left join yp_dwd.fact_goods_evaluation e on e.order_id=o.id and e.is_valid=1
-- 订单配送表
left join yp_dwd.fact_order_delievery_item d on d.shop_order_id=o.id and d.dispatcher_order_type=1 and d.is_valid=1 and d.end_date='9999-99-99'
where o.end_date='9999-99-99'
-- and og.group_id='dd2019022817332967452f41f'
-- and o.id='dd19040334655236d5'
;
循环执行
确定业务更新周期后,只需要将更新周期内的数据覆盖插入即可。
通过▁▁▁限制数据范围,通过▁▁▁走分区提高性能。
insert overwrite ...
...
-- 只会更新30天之内的数据
AND o.start_date >= date_add('${Last_DATE}', -30)
;
店铺明细宽表
建表
合并表,形成宽表:▁▁▁▁▁▁▁▁▁▁▁▁
DROP TABLE if EXISTS yp_dwb.dwb_shop_detail;
CREATE TABLE yp_dwb.dwb_shop_detail(
-- 店铺
id string,
address_info string COMMENT '店铺详细地址',
store_name string COMMENT '店铺名称',
is_pay_bond tinyint COMMENT '是否有交过保证金 1:是0:否',
trade_area_id string COMMENT '归属商圈ID',
delivery_method tinyint COMMENT '配送方式 1 :自提 ;3 :自提加配送均可\; 2 : 商家配送',
store_type int COMMENT '店铺类型 22天街网店 23实体店 24直营店铺 33会员专区店',
is_primary tinyint COMMENT '是否是总店 1: 是 2: 不是',
parent_store_id string COMMENT '父级店铺的id,只有当is_primary类型为2时有效',
-- 商圈
trade_area_name string COMMENT '商圈名称',
-- 区域-店铺
province_id string COMMENT '店铺所在省份ID',
city_id string COMMENT '店铺所在城市ID',
area_id string COMMENT '店铺所在县ID',
province_name string COMMENT '省份名称',
city_name string COMMENT '城市名称',
area_name string COMMENT '县名称'
)
COMMENT '店铺明细表'
--PARTITIONED BY(dt STRING)
row format delimited fields terminated by '\t'
stored as orc
tblproperties ('orc.compress' = 'SNAPPY');
实现
自关联查询:pid(通过与id关联,找到自己的上级)
--=======店铺宽表=======
insert into yp_dwb.dwb_shop_detail partition (dt)
select
s.id,
s.address_info,
s.name as store_name,
s.is_pay_bond,
s.trade_area_id,
s.delivery_method,
s.store_type,
s.is_primary,
s.parent_store_id,
ta.name as trade_area_name,
pro.id province_id,
city.id city_id,
area.id area_id,
pro.name province_name,
city.name city_name,
area.name area_name,
SUBSTRING(s.create_time,1,10) dt
--店铺
from yp_dwd.dim_store s
--商圈
left join yp_dwd.dim_trade_area ta on s.trade_area_id=ta.id and ta.end_date='9999-99-99'
-- 地区
left join yp_dwd.dim_location lo on lo.type=2 and lo.correlation_id=s.id and lo.end_date='9999-99-99'
left join yp_dwd.dim_district area on area.code=lo.adcode
left join yp_dwd.dim_district city on area.pid=city.id
left join yp_dwd.dim_district pro on city.pid=pro.id
where s.end_date='9999-99-99'
;
循环执行
确定业务更新周期后,只需要将更新周期内的数据覆盖插入即可。
通过▁▁▁限制数据范围,通过▁▁▁走分区提高性能。
insert overwrite ...
...
and SUBSTRING(s.create_time,1,10) >= '${Last_Month_DATE}' and s.start_date >= '${Last_Month_DATE}'
;
商品明细宽表
建表
合并表,形成宽表:▁▁▁▁▁▁▁▁▁▁▁▁
实现
1、遇到不确定的关联字段,或者不确定值的字段,可以通过sql测试,最终要和需求方确认。
2、分类表自关联,不是从最小级别开始,级别不固定:
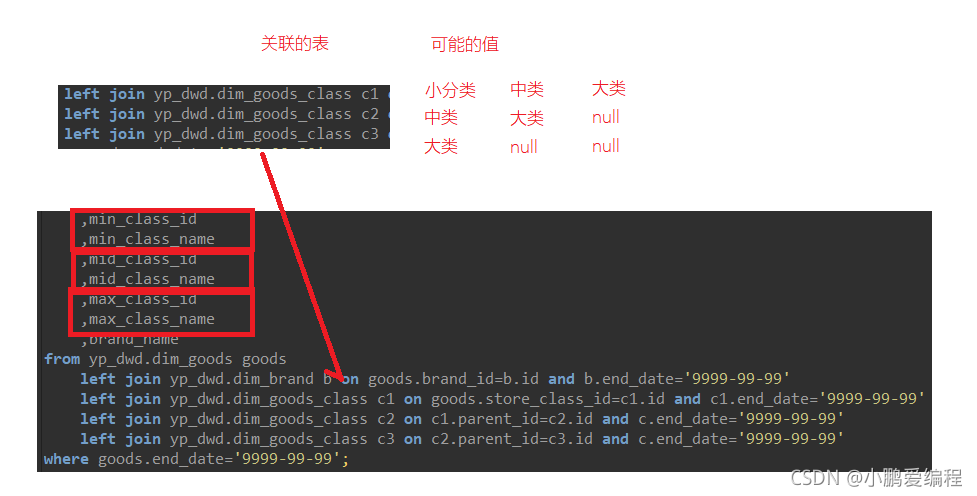
判断小分类时,要使用c1、c2、c3;
判断中类时,要使用c2、c3;
判断大类时,要使用c3。
--=======商品宽表======= INSERT into yp_dwb.dwb_goods_detail partition (dt) SELECT goods.id, goods.store_id, goods.class_id, goods.store_class_id, goods.brand_id, goods.goods_name, goods.goods_specification, goods.search_name, goods.goods_sort, goods.goods_market_price, goods.goods_price, goods.goods_promotion_price, goods.goods_storage, goods.goods_limit_num, goods.goods_unit, goods.goods_state, goods.goods_verify, goods.activity_type, goods.discount, goods.seckill_begin_time, goods.seckill_end_time, goods.seckill_total_pay_num, goods.seckill_total_num, goods.seckill_price, goods.top_it, goods.create_user, goods.create_time, goods.update_user, goods.update_time, goods.is_valid, CASE class1.level WHEN 3 THEN class1.id ELSE NULL END as min_class_id, CASE class1.level WHEN 3 THEN class1.name ELSE NULL END as min_class_name, CASE WHEN class1.level=2 THEN class1.id WHEN class2.level=2 THEN class2.id ELSE NULL END as mid_class_id, CASE WHEN class1.level=2 THEN class1.name WHEN class2.level=2 THEN class2.name ELSE NULL END as mid_class_name, CASE WHEN class1.level=1 THEN class1.id WHEN class2.level=1 THEN class2.id WHEN class3.level=1 THEN class3.id ELSE NULL END as max_class_id, CASE WHEN class1.level=1 THEN class1.name WHEN class2.level=1 THEN class2.name WHEN class3.level=1 THEN class3.name ELSE NULL END as max_class_name, brand.brand_name, SUBSTRING(goods.create_time,1,10) dt --SKU FROM yp_dwd.dim_goods goods --商品分类 left join yp_dwd.dim_goods_class class1 on goods.store_class_id = class1.id AND class1.end_date='9999-99-99' left join yp_dwd.dim_goods_class class2 on class1.parent_id = class2.id AND class2.end_date='9999-99-99' left join yp_dwd.dim_goods_class class3 on class2.parent_id = class3.id AND class3.end_date='9999-99-99' --品牌 left join yp_dwd.dim_brand brand on goods.brand_id=brand.id AND brand.end_date='9999-99-99' WHERE goods.end_date='9999-99-99' ;
循环执行
确定业务更新周期后,只需要将更新周期内的数据覆盖插入即可。
通过▁▁▁限制数据范围,通过▁▁▁走分区提高性能。
insert overwrite ...
...
and SUBSTRING(s.create_time,1,10) >= '${Last_Month_DATE}' and s.start_date >= '${Last_Month_DATE}'
;
Hive索引
Hive原始索引
需要手动重建索引,不推荐,在hive3.0中已经被废弃。
开启方式
hive.optimize.index.filter
Row Group Index
作用
作用于数值类型的条件查询<、>、=。
开启方式
-
hive.optimize.index.filter
-
创建表时开启索引
CREATE TABLE lxw1234_orc2 (id int, pcid int) stored AS ORC TBLPROPERTIES ( 'orc.compress'='SNAPPY', -- 开启行组索引 'orc.create.index'='true' ) -
插入数据时,按照索引字段排序
insert into lxw1234_orc2 SELECT CAST(siteid AS INT) AS id, pcid FROM lxw1234_text -- 插入的数据保持排序 cluster by id; -- DISTRIBUTE BY id sort BY id;
使用索引查询:
set hive.optimize.index.filter=true; SELECT COUNT(1) FROM lxw1234_orc1 -- 对数值类型字段进行条件查询 WHERE id >= 1382 AND id <= 1399;
Bloom Filter Index
作用
作用于等值条件查询(不限类型)。
开启方式
创建表时,指定索引字段。
CREATE TABLE lxw1234_orc2 stored AS ORC
TBLPROPERTIES
(
'orc.compress'='SNAPPY',
'orc.create.index'='true',
-- pcid字段开启BloomFilter索引
"orc.bloom.filter.columns"="pcid"
)
AS
SELECT CAST(siteid AS INT) AS id,
pcid
FROM lxw1234_text
DISTRIBUTE BY id sort BY id;
使用索引查询:
SET hive.optimize.index.filter=true;
SELECT COUNT(1) FROM lxw1234_orc1 WHERE id >= 0 AND id <= 1000
-- 使用等值条件查询
AND pcid IN ('0005E26F0DCCDB56F9041C','A');

















 2808
2808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









