






pytorch学习笔记(一)
1、进入pytorch的命令:conda activate pytorch
2、dir():打开看见 。如dir(pytorch.3.a)
help():说明书
3、维度诅咒:维度越高,所需要的数据量就越多,假设一维数据密度为10,则三维数据密度为1000,所以降维有了产生的必要。
4、Training Loss针对样本,MSE(Mean Square Error,即平均平方误差)针对训练集
5、visdom可视化工具
6、鞍点:进入鞍点之后无法进入迭代。
7、指数加权平均:采用指数加权平均使得曲线更加平滑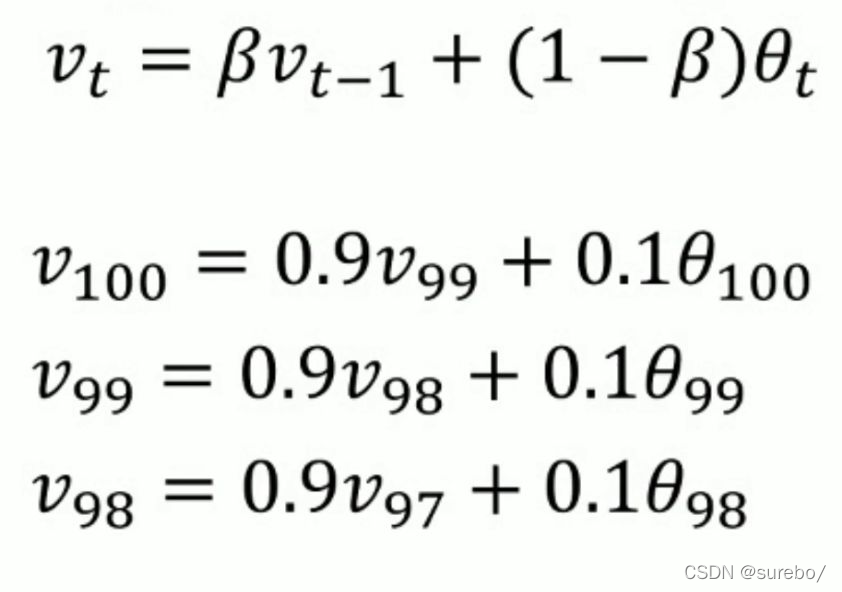 8、训练结果发散有可能是学习率取得太大,尝试把α降低。
8、训练结果发散有可能是学习率取得太大,尝试把α降低。
9、 梯度下降算法
随机梯度下降(stochastic gradient descent):随机选取单个样本的损失函数对w权重求导。
批量梯度下降(Mini-Batch):整体性能低,时间复杂度低;单个性能高,时间复杂度高。折中办法——采取Mini-Batch,将数据分成若干皮,按批来更新参数。
10、反向传播(Back Propagation):先前馈再反馈求出梯度。
Tensor在做运算时在构建运算图。
11、PyTorch Fashion:
① Prepare dataset
② Design model using Class:inherit from nn.Module
③ Construct loss and optimizer:using PyTorch API
④ Training cycle:forword,backward,update
12、Design model using Class
① 用类设计模型需要画出运算图。仿射模型——线性单元:z=w*x+b
// nn.Linear必须有__init__()和forward()
// nn.Linear有__call__()让类的实例能够像function一样使用
class LinearModel(torch.nn.Module)
def __init__(self):
super(LinearModel,self).__init__()
self.Linear = torch.nn.Linear(1,1) //第一个参数是权重,第二个是偏置
def forward(self,x):
y_pred = self.linear(x) //把输入x变成y-hat
return y_pred
model = LinearModel() //把模型实例化
② 函数中传递参数:
*args:把所传递的未确定名称的参数组成元组;
**kargs:把所传递的确定名称的参数组成字典。
def func(*args,**kargs)
print(args) //输出(1,2,3,4)
print(kargs) //输{'x':3,'y':5}
func(1,2,4,3,x=3,y=5)
13、Construct loss and optimizer
criterion = torch.nn.MSELoss(size_average=False)
//torch.nn.MSELoss(size_average=True,reduce=True) 第一个参数是否求均值,第二个是否降维
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
//第一个是找到模型里需要优化的参数,第二个是学习率
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss) //将loss自动转为字符串
optimizer.zero_grad() //梯度归零
loss.backward() //backward
optimizer.step() //update


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









