







 本文详细介绍了如何使用Scrapy爬虫抓取智联招聘网站的数据,包括安装配置、项目创建及使用shell调试工具解决403防爬问题,通过设置User-Agent使Scrapy伪装成浏览器,并利用XPath提取具体信息。
本文详细介绍了如何使用Scrapy爬虫抓取智联招聘网站的数据,包括安装配置、项目创建及使用shell调试工具解决403防爬问题,通过设置User-Agent使Scrapy伪装成浏览器,并利用XPath提取具体信息。
爬虫的安装:
pip install scrapy
创建项目:
scrapy startproject ZhipinSpider
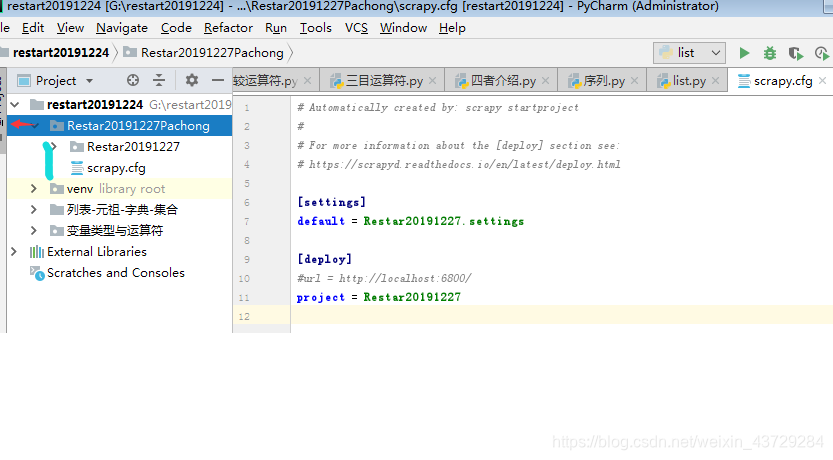
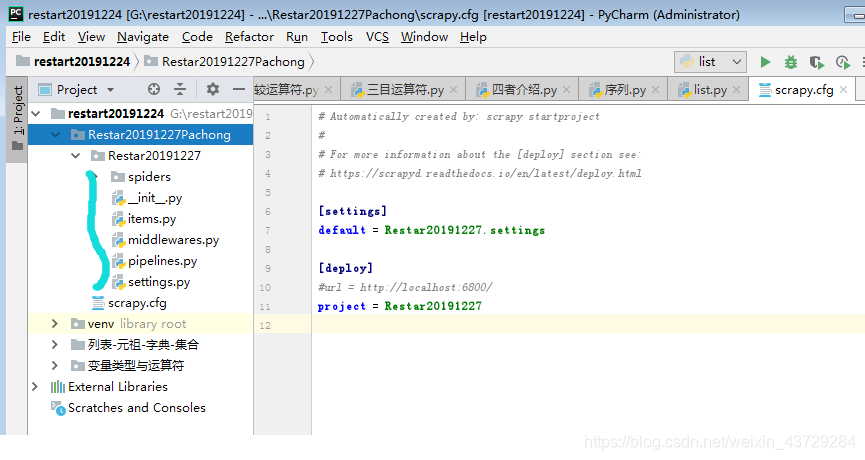
Scrapy 提供的 shell 调试工具来抓取该页面中的信息。使用如下命令来开启 shell 调试:
scrapy shell https://www.zhipin.com/c101280100/h_101280100/
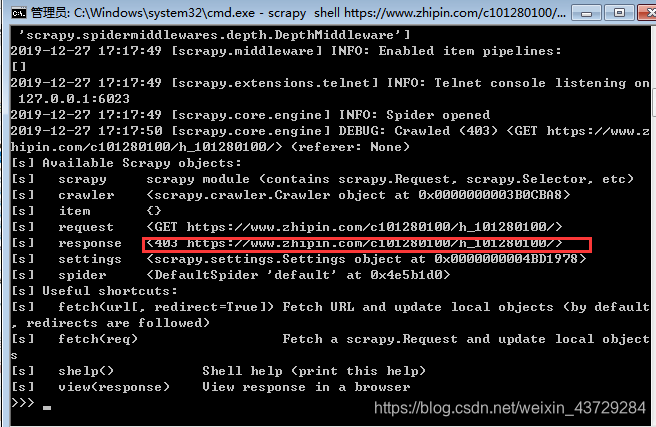
将会看到 Scrapy 并未抓取到页面数据,页面返回了 403 错误,这表明目标网站开启了“防爬虫”,不允许使用 Scrapy“爬取”数据。为了解决这个问题,我们需要让 Scrapy 伪装成浏览器。
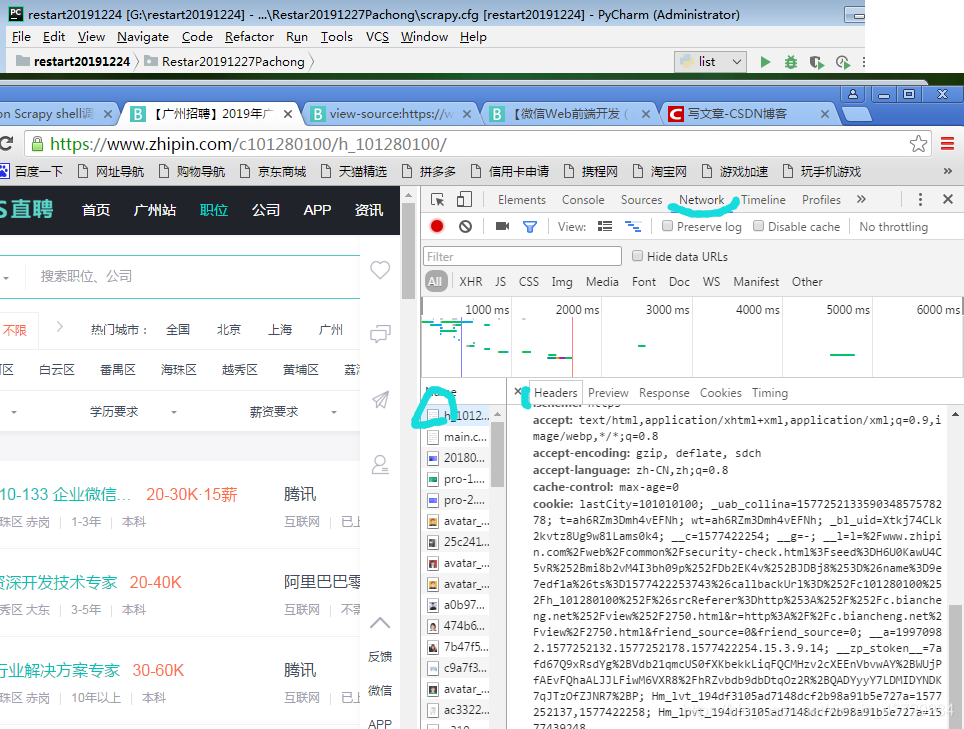
scrapy shell -s USER_AGENT=‘Mozilla/5.0’ https://www.zhipin.com/c101280100/h_101280100

以使用 XPath 或 css 选择器来提取我们想要的数据:
表 5 XPath 最实用的简化写法
表达式 作用
nodename 匹配此节点的所有内容
/ 匹配根节点
// 匹配任意位置的节点
. 匹配当前节点
… 匹配父节点
@ 匹配属性
节点后增加一个方括号,在方括号内放一个限制表达式对该节点进行限制
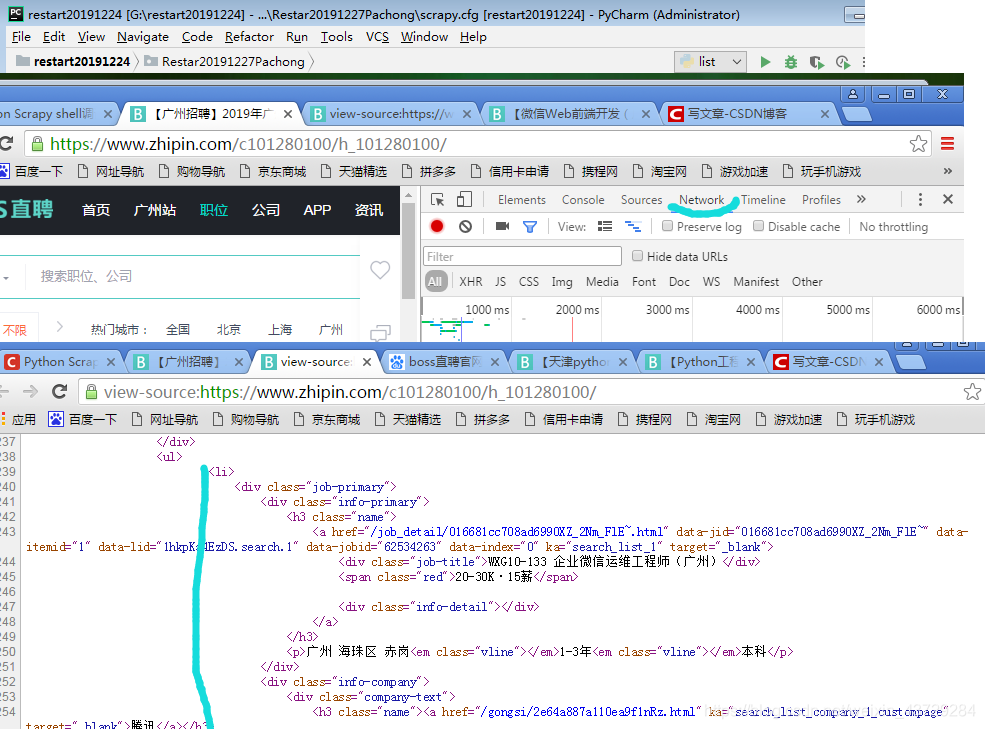
,想获取上面页面中的第一条工作信息的工作名称
//div[@class = “job-primary”]/div/h3/a/div/text()
即可在 Scrapy 的 shell 控制台调用 response 的 xpath() 方法来获取 XPath 匹配的节点。执行如下命令:
response.xpath (’//div[@class=“job-primary”]/div/h3/a/div/text()’).extract()
上面的 extract() 方法用于提取节点的内容
问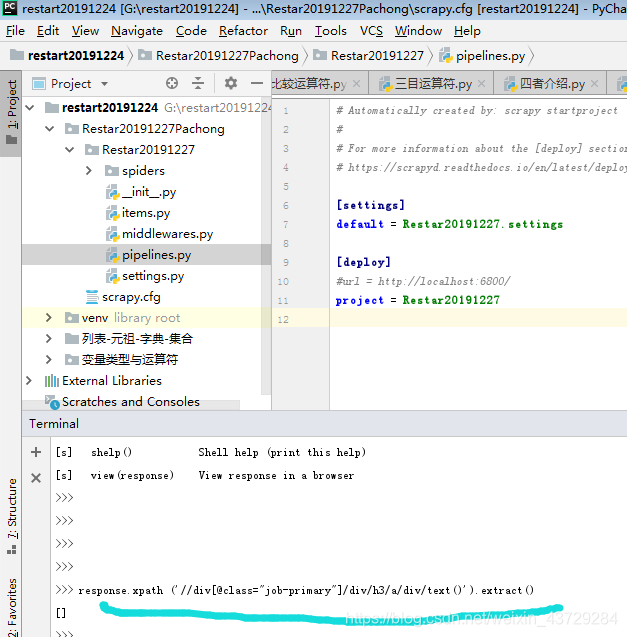
页面加载了,但是想要的信息没有获取出来,待续

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









