







RNN原理
-
循环神经网络:处理序列模型,权值共享。
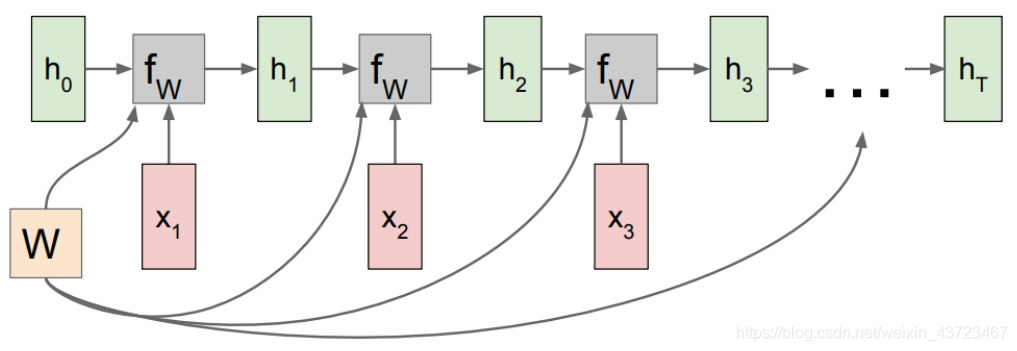
h[t] = fw(h[t-1], x[t]) #fw is some function with parameters W h[t] = tanh(W[h,h]*h[t-1] + W[x,h]*x[t]) #to be specific y[t] = W[h,y]*h[t] -
Sequence to Sequence 模型示意图
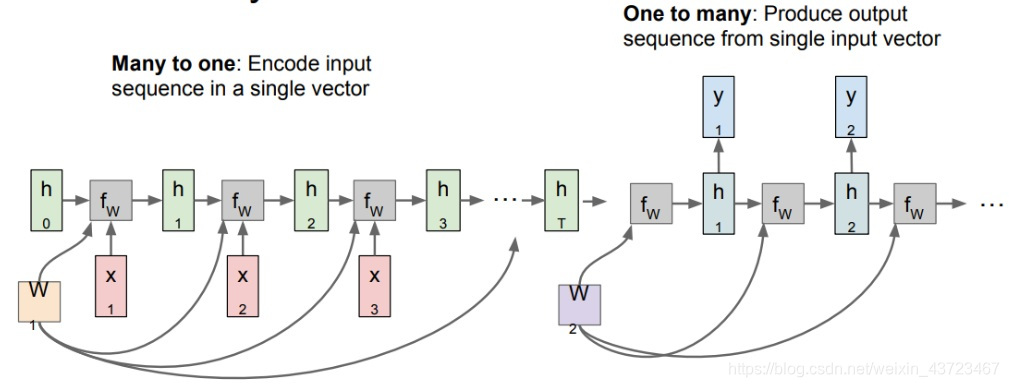
-
语言模型示意图
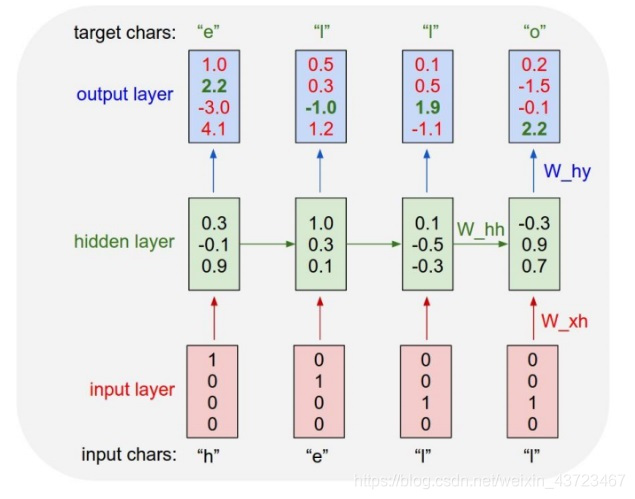
RNN实战
-
3个句子,一个句子10个单词,一个单词100维
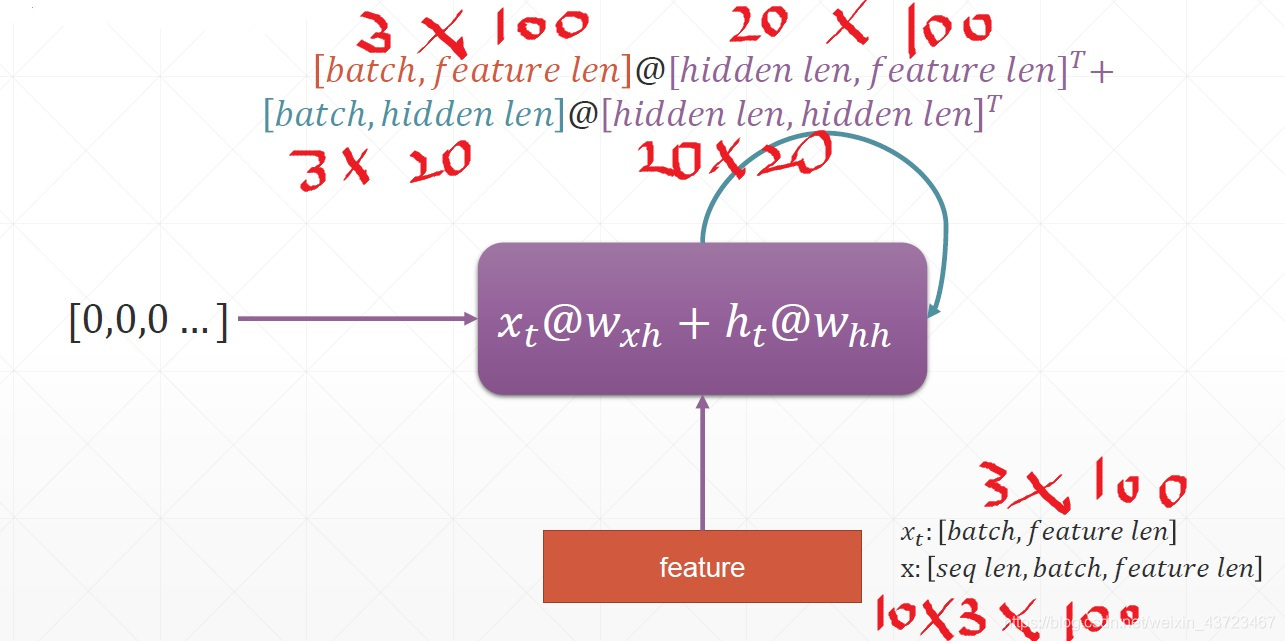
-
基础用法
rnn = nn.RNN(100,10) #input_size(feature_len)=100,hidden_len = 10 rnn._parameters.keys() #how many tensor(4个l0层的w和b) nn.RNN(input_size,hidden_size, num_layers = 1) #h0 : [layer, batchsz, hidden] x : [seq, batchsz, input ] #ht : [layer, batchsz, hidden] out: [seq, batchsz, hidden] out, ht = forward(x, h0) #对于多层rnn,out不变(所有时间最后mem状态),ht变为[2,~,~](所有层最后时间状态) cell = nn.RNNcell() #参数与nn.RNN()相同,但是每个时间戳都要输入xt for xt in x: h1 = cell(xt,h1) #如果你想在输入x时按这个格式:[batchsz, seq_len, input] #需要在nn.RNN()中加参数: batch_first = True -
建一个非常简单的RNN模型(以一个简单时间序列预测为例)
class Net(nn.Module): def __init__(self,input_size,hidden_size): super(net, self).__init__() self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, num_layers=1, batch_first=True, ) for p in self.rnn.parameters():#正态分布的权值初始化 nn.init.normal_(p, mean=0.0, std=0.001) self.linear = nn.Linear(hidden_size, output_size) def forward(self,x,h0): out, ht = self.rnn(x, h0) #out:[batch_sz,seq,hidden_sz] out = out.view(-1, hidden_size)#out:[seq,hidden_size](b=1) out = self.linear(out) #out:[seq,output_size] out = out.unsqueeze(dim=0) #out:[1,seq,output_size] return out, ht -
由于我们在对RNN进行反向传播求梯度的时候,最后的求导项里面有一个 W h h k W_{hh}^{k} Whhk,会导致梯度爆炸或梯度消失。
# 解决梯度爆炸 for p in net.parameters(): torch.nn.utils.clip_grad_norm_(p, 10) # 保证梯度的绝对值小于10 # 解决梯度离散:LSTM -
LSTM:Long Short-Term Memory(结构如下图)
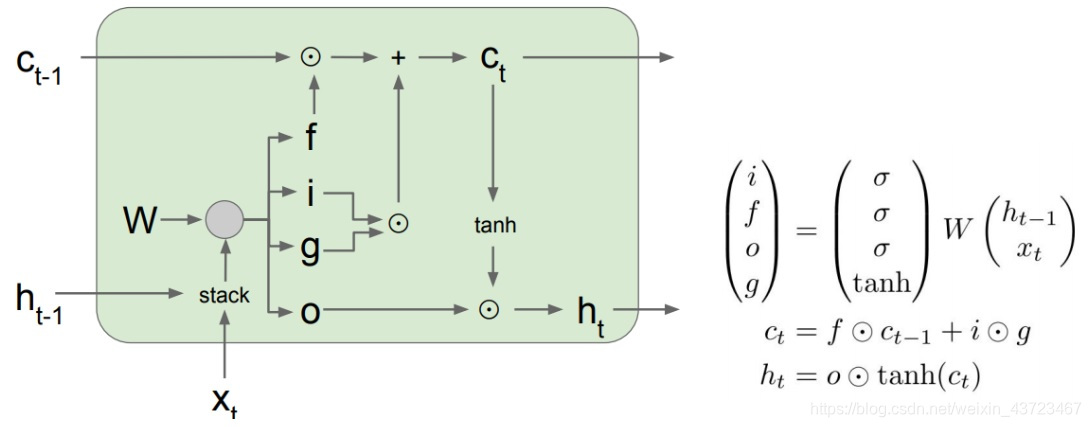
有三个门:分别是遗忘门— f f f,输入门— i i i,输出门— o o o。对于输入输出变量: c t − 1 c_{t-1} ct−1</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









