






 脚本帮助划分VOC数据集,保证训练和测试集分布均匀,并提供可视化功能。
脚本帮助划分VOC数据集,保证训练和测试集分布均匀,并提供可视化功能。
脚本使用须知
本脚本是将划分voc数据集并且可视化训练集和测试集的数据分布。采用了分层划分数据集,使得划分的训练集和测试集的数据分布均匀。
使用前提:
将文件夹改为如下格式
dataset---|---Annotations(这个文件夹下放xml)
|---ImageSets---|---Main(空文件夹)
|---JPEGImages(这个文件夹下放图片)
使用示例:python voc.py --devkit_dir 你的数据集路径 --train_percent 划分数据集的比例
例如:python voc.py --devkit_dir E:\new-learning\Dataset\rubbish_pink_v1 --train_percent 0.8
通过命令行就能调用的脚本,简单易用
脚本如下:
voc.py
import os
import os.path as osp
import re
import xml.etree.ElementTree as ET
import matplotlib.pyplot as plt
from collections import defaultdict
from collections import defaultdict
import random
import argparse
years = ['2007', '2012']
def get_dir(devkit_dir, type):
return osp.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets\Main')
annotation_dir = get_dir(devkit_dir, 'Annotations')
img_dir = get_dir(devkit_dir, 'JPEGImages')
trainval_list = []
test_list = []
added = set()
for _, _, files in os.walk(filelist_dir):
for fname in files:
img_ann_list = []
if re.match('train\.txt', fname):
img_ann_list = trainval_list
elif re.match('val\.txt', fname):
img_ann_list = test_list
else:
continue
fpath = osp.join(filelist_dir, fname)
for line in open(fpath):
name_prefix = line.strip().split()[0]
if name_prefix in added:
continue
added.add(name_prefix)
ann_path = osp.join(annotation_dir, name_prefix + '.xml')
img_path = osp.join(img_dir, name_prefix + '.jpg')
assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
assert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))
return trainval_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
test_list = []
trainval, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
test_list.extend(test)
random.shuffle(trainval_list)
with open(osp.join(output_dir, 'train.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(osp.join(output_dir, 'val.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
def generate_train_val_txt(devkit_dir, output_dir, train_percent):
xml_dir = os.path.join(devkit_dir, 'Annotations')
total_xml = os.listdir(xml_dir)
# 为每个类别创建一个字典来存储样本
class_samples = defaultdict(list)
for xml_file in total_xml:
xml_path = os.path.join(xml_dir, xml_file)
labels = load_annotations(xml_path)
# 将样本按照标签分配到对应的类别中
for label in labels:
class_samples[label].append(xml_file)
train_samples = []
val_samples = []
for label, samples in class_samples.items():
num_samples = len(samples)
num_train = int(num_samples * train_percent)
# 打乱顺序
random.shuffle(samples)
train_samples.extend(samples[:num_train])
val_samples.extend(samples[num_train:])
# 将划分结果写入train.txt和val.txt
with open(os.path.join(output_dir, 'train.txt'), "w") as ftrain:
for sample in train_samples:
ftrain.write(sample[:-4] + "\n")
with open(os.path.join(output_dir, 'val.txt'), "w") as fval:
for sample in val_samples:
fval.write(sample[:-4] + "\n")
def load_paths_from_txt(txt_path):
with open(txt_path, 'r') as file:
lines = file.readlines()
# 移除每行末尾的换行符
return [line.strip() for line in lines]
def load_annotations(xml_path):
tree = ET.parse(xml_path)
root = tree.getroot()
# 从 object 标签中提取标签
labels = [obj.find('name').text for obj in root.findall('object')]
return labels
def visualize_label_distribution(txt_path, xml_dir, title):
image_paths = load_paths_from_txt(txt_path)
label_counts = defaultdict(int)
for image_path in image_paths:
# 将图像路径拆分为 JPEG 和 XML 路径
jpeg_path, _ = os.path.splitext(image_path)
xml_path = os.path.join(xml_dir, f"{os.path.basename(jpeg_path)}.xml")
labels = load_annotations(xml_path)
for label in labels:
label_counts[label] += 1
labels, counts = zip(*label_counts.items())
plt.figure(figsize=(10, 5))
plt.bar(labels, counts, color='blue')
plt.xlabel('label')
plt.ylabel('count')
plt.title(title)
plt.show()
def main(args):
# 设置路径
train_percent = args.train_percent #划分数据集比例
devkit_dir = args.devkit_dir #数据集路径
output_dir = get_dir(devkit_dir, "ImageSets\Main")
train_txt_path = get_dir(devkit_dir, "train.txt")
val_txt_path = get_dir(devkit_dir, "val.txt")
xml_dir = get_dir(devkit_dir, "Annotations")
# 生成train.txt和val.txt
generate_train_val_txt(devkit_dir, output_dir, train_percent)
prepare_filelist(devkit_dir, devkit_dir)
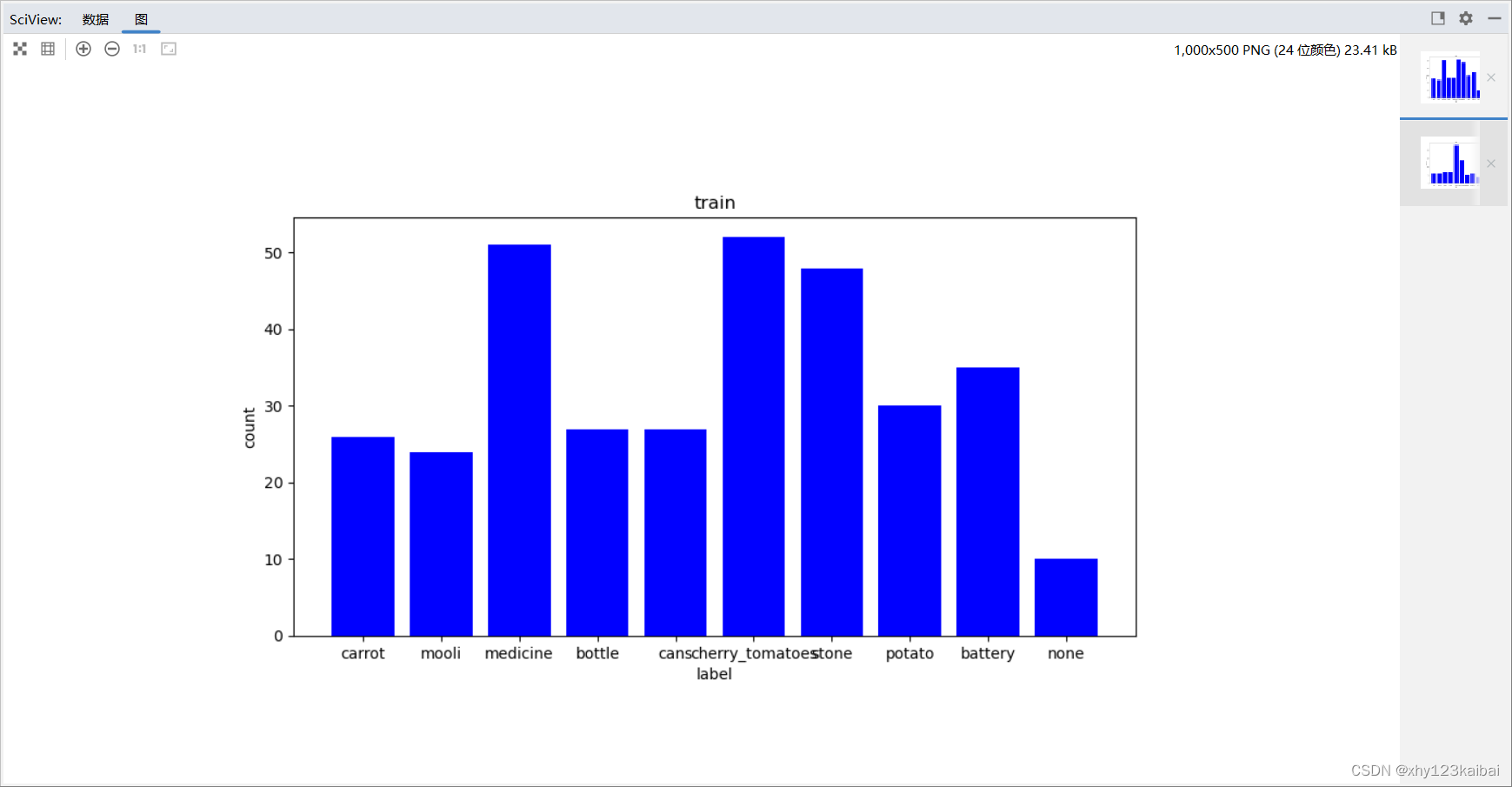
visualize_label_distribution(train_txt_path, xml_dir, 'train')
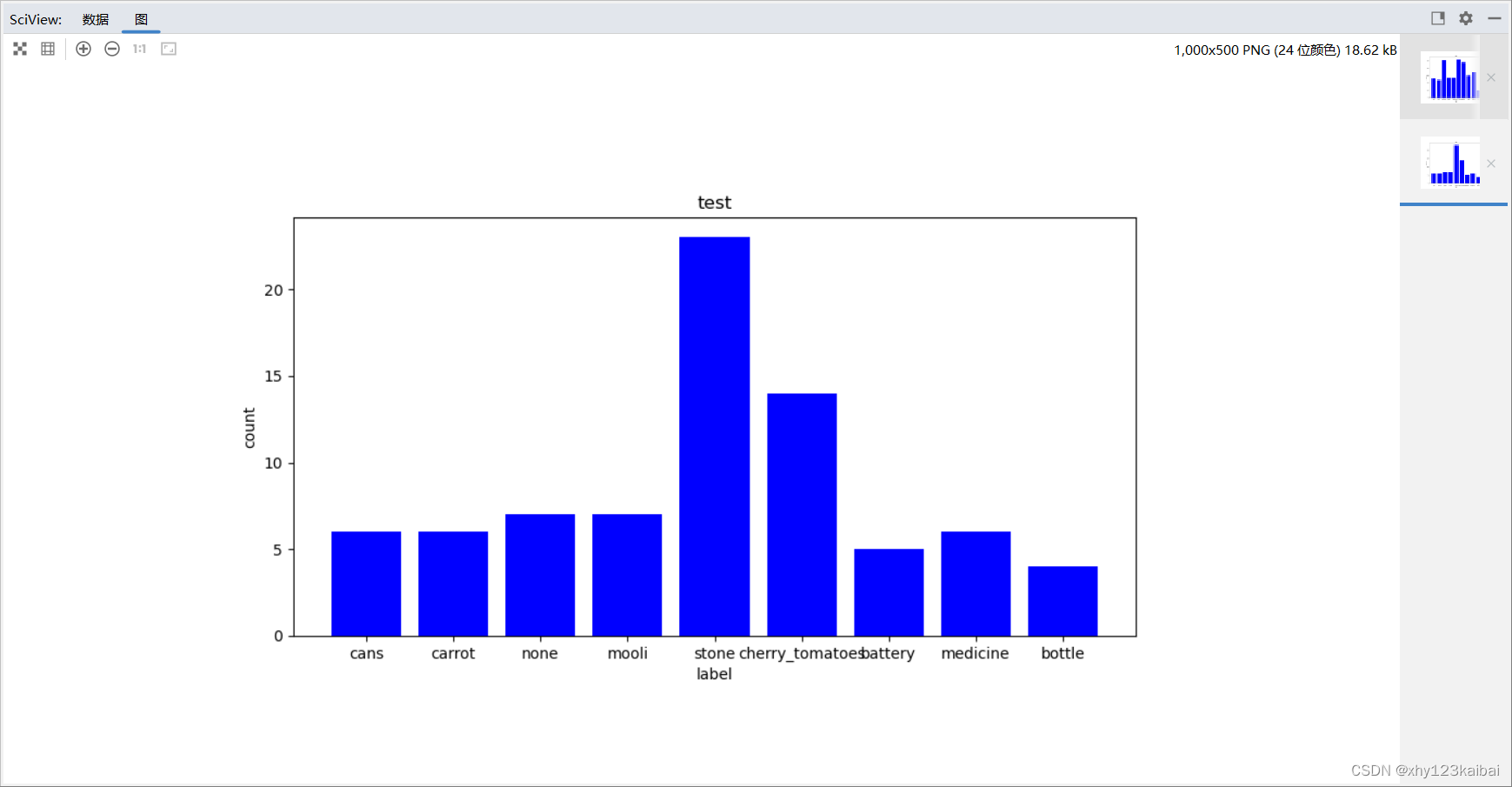
visualize_label_distribution(val_txt_path, xml_dir, 'test')
if __name__ == '__main__':
# 创建 ArgumentParser 对象
parser = argparse.ArgumentParser(description='Script for data preparation and visualization.')
# 添加命令行参数
parser.add_argument('--devkit_dir', type=str, help='数据集路径')
parser.add_argument('--train_percent', type=float, help='划分数据集比例')
# 解析命令行参数
args = parser.parse_args()
# 调用主函数并传递解析后的参数
main(args)
只需要调用命令就行。命令在开头使用说明中给出。
可视化展示:(随便拿的数据集测试的,数据集本身的各类数据就不均匀,导致可视化中数据并不均匀)


















 3875
3875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









