








 本文分享了一次因磁盘空间不足导致集群无法启动的经历,详细介绍了如何通过查找并清理大文件,尤其是Kafka日志文件,来解决此问题。同时,文章还提供了设置日志滚动的方法,以预防未来再次发生类似情况。
本文分享了一次因磁盘空间不足导致集群无法启动的经历,详细介绍了如何通过查找并清理大文件,尤其是Kafka日志文件,来解决此问题。同时,文章还提供了设置日志滚动的方法,以预防未来再次发生类似情况。
这里笔者分享自己的一次经历:
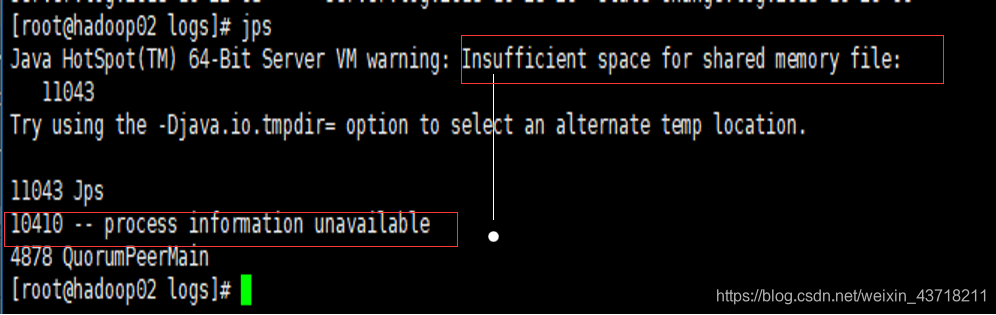
有一天发现自己的集群启动不起来,jps看了一下,发现是磁盘空间不足。
Insufficient space for shared memory file:共享内存文件空间不足
下面是我的解决方法:
命令:find / -type f -size +500M
查看/目录下大于500兆的文件
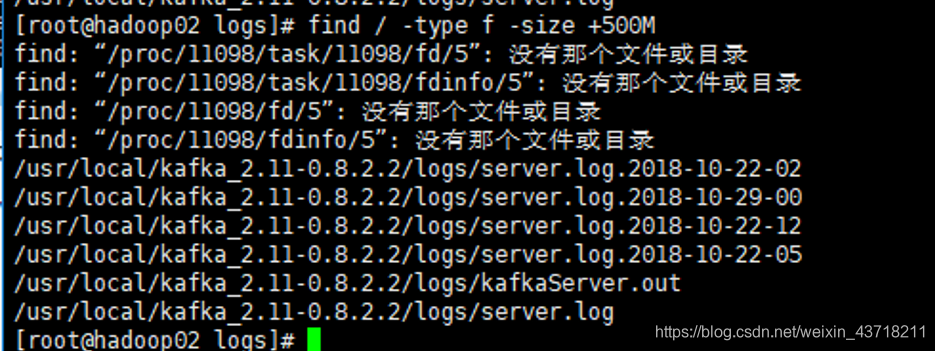
可以看到查询的结果大部分都是/usr/local/kafka/logs/下的
那我们肯定要去那个路径看一看:进去之后,
使用命令:du -h +被查看目录
-h以K,M,G为单位,提高信息的可读性
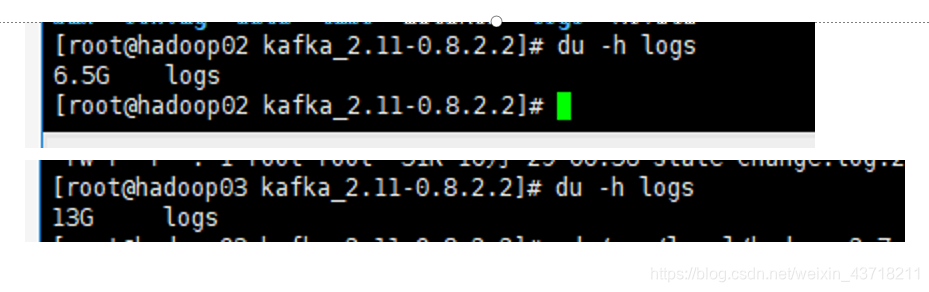
我们能够看到hadoop02的logs占了6.5个G,而hadoop03机器的logs占用磁盘高达13G,而笔者每台机器分的是20G。
既然找到原因我们只需要把logs清一下就ok了。当然我们也可以设置日志滚动,让它保存7天,超过7天删除掉。
另外磁盘不足导致集群非正常关闭,jps可能会出现
process information unavailable
给大家推荐一个博客:
Linux服务器jps报process information unavailable
https://www.cnblogs.com/freeweb/p/5748424.html
那些磁盘不足导致集群失败的事儿
最新推荐文章于 2025-04-02 14:36:05 发布


















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









