




 本文介绍如何使用Flume监听本地文件并将其数据发送到Kafka主题,包括配置Flume的source、sink和channel,以及启动Flume agent进行数据传输的过程。
本文介绍如何使用Flume监听本地文件并将其数据发送到Kafka主题,包括配置Flume的source、sink和channel,以及启动Flume agent进行数据传输的过程。
创建一个消费者,开启消费:(消费的是test02的数据,可更改自行创建)

开启水管flume,(监听temData.tsv)

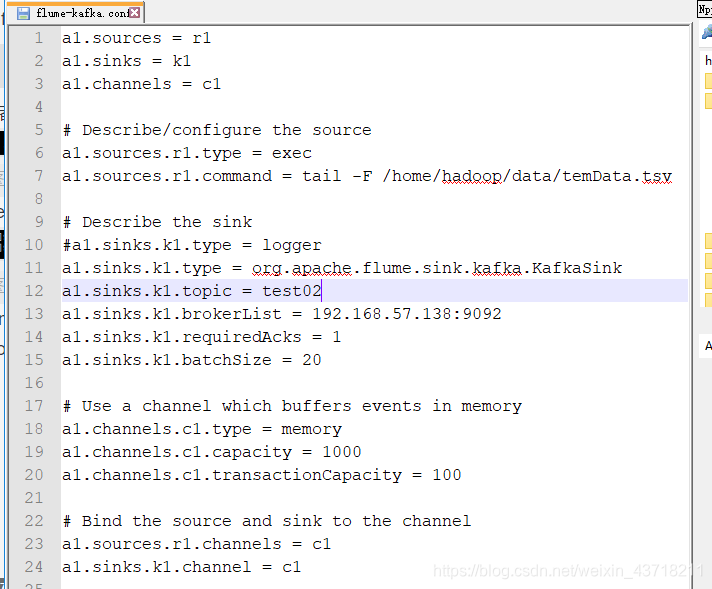
这里有一个flume的配置文件(job是我创建在flume目录下的文件夹,job下有flume-kafka.conf的文件)
向temData.tsv中写入数据(这里写了个jar包,不停向temData.tsv写入数据)

在这里插入代码片
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data/temData.tsv
# Describe the sink
#a1.sinks.k1.type = logger
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = test02
a1.sinks.k1.brokerList = 192.168.57.138:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









