






 本文详细介绍了KMeans聚类算法的工作原理和应用,包括欧氏距离的计算和在文本聚类中使用TF-IDF的方式。通过实例解释了如何通过KMeans将数据分为不同的类别,并提到了如何选择最优的K值。最后,预告了将在后续内容中展示KMeans在Python中的实现。
本文详细介绍了KMeans聚类算法的工作原理和应用,包括欧氏距离的计算和在文本聚类中使用TF-IDF的方式。通过实例解释了如何通过KMeans将数据分为不同的类别,并提到了如何选择最优的K值。最后,预告了将在后续内容中展示KMeans在Python中的实现。
三、(1)Kmeans
Kmeans算法,即K均值聚类算法,一般指K均值聚类算法。
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
kmeans属于非监督学习中的一种,
我们通过几个简单的例子来加深一下Kmeans聚类的印象。

上图中有许多身份不同的人物,利用Kmeans聚类,我们或随机选取几个不同的人物,假设选取了一个红色和一个黄色两个人物类别,那么通过计算这两个人物和其他所有人物之间的距离,来确定最后形成的两个不同的小群里,理想情况就是所有工人可以分到一起,所有穿西装的可以分到一起。

我们可以自定义K值的选择来确定自己的数据需要被分成几类,在下一篇文章中。我们会通过类似于轮廓系数的评价指标来帮助我们选取最优的K值。下图简单的对Kmeans聚类的过程做了一个演示。
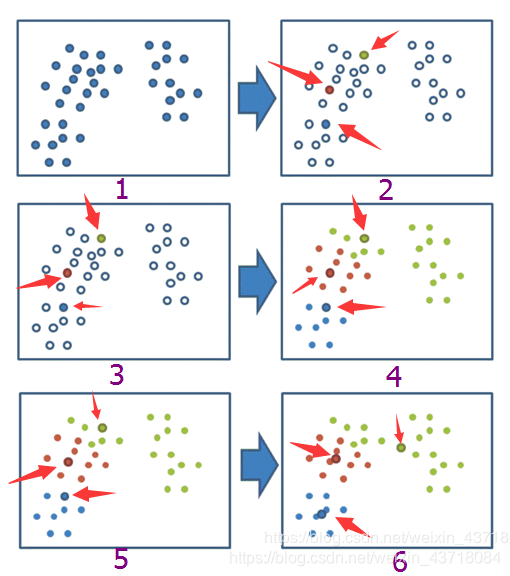
对于给出的一个数据,从图1开始聚类,我们选取的是K=3,在随机选取3个中心点后,图1中的数据被分成了图4中绿、红、蓝三个部分,此时的中心点还在变化,在图6时达到局部最优。
简单总结一下聚类步骤:
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别。
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
Kmeans应用欧氏距离
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。在二维和三维空间中的欧氏距离就是两点之间的实际距离。
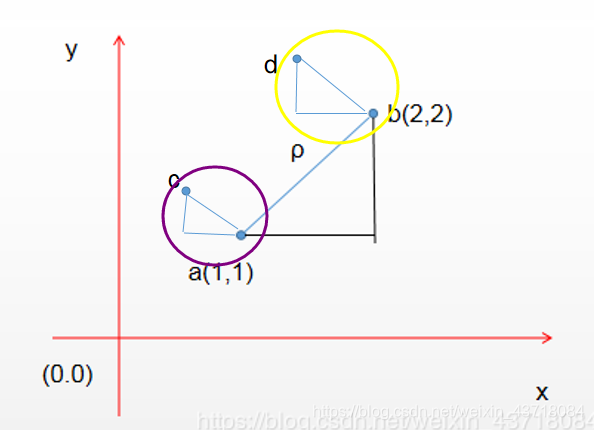
在二维空间中距离公式
a(x1,y1) b(x2,y2),假设a,b是随机生成的两个中心点,则c属于a,d属于b。

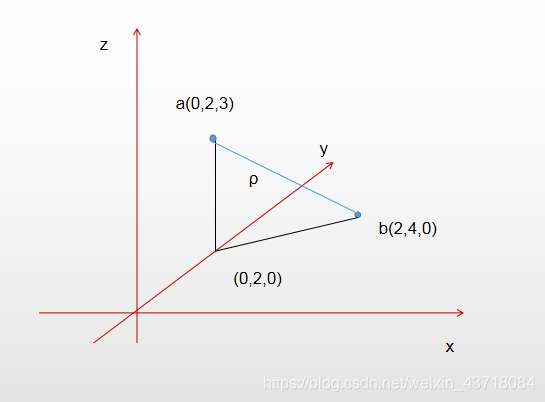
在三维空间中距离公式
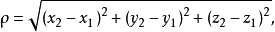
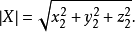
n维空间的公式
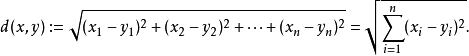
Kmeans应用tf-idf对文本聚类
词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到:
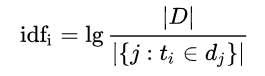
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
根据对多个文本的测试,tf-idf的有点就是可以去除文章中许多高频单作用不大的词,即一些常用词,可以有效地提高聚类效果。
这部分可以参考超链接里的几个例子理解。超链接例子
对于欧氏距离和tf-idf在Kmeans中的应用,将会在下文利用python实现。
搞定收工。
“☺☺☺ 若本篇文章对你有一丝丝帮助,请帮顶、评论点赞,谢谢。☺☺☺”
↓↓↓↓

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









