







 本文介绍了字符串模式匹配的经典算法——KMP算法。通过分析模式串和主串的关系,提出了KMP算法的基本思想和next数组的构建原理,讨论了如何通过next数组优化模式串的移动,从而提高匹配效率。KMP算法的时间复杂度为O(m*n),适用于解决模式串在主串中匹配的问题。
本文介绍了字符串模式匹配的经典算法——KMP算法。通过分析模式串和主串的关系,提出了KMP算法的基本思想和next数组的构建原理,讨论了如何通过next数组优化模式串的移动,从而提高匹配效率。KMP算法的时间复杂度为O(m*n),适用于解决模式串在主串中匹配的问题。
引子
今天主要想总结一下字符串中的一个经常出现于教材的一个经典算法,算法的要求很简单,就是给出两个字符串,判断一个字符串是否是另一个字符串的子串.子串的定位操作通常也叫做模式匹配.在算法教材中,我们通常把这两个字符串分别叫做模式串和主串,模式串是较短的那个字符串,而主串就是较长的那个,所以问题的核心就是判断模式串是否是主串的子串.
比如说,给一个主串"abcdcbaa"和模式串"cdcba",那么凭借肉眼的比较,可以得知这个模式串"cdcba"就是主串"abcdcbaa"的一个子串,专业术语也叫做模式串在主串中匹配成功.这个问题非常的简单易懂,举个例子就能让很多人明白.那么接下来就是对于这样一个问题探讨如何通过编程实现.
分析
我们将这个问题抽象化,这里存在两个对象,一个是主串,一个是模式串,一般而言,主串是比模式串要长的,当然,长度相等也可以,但不可能出现主串短于模式串的情况.设主串为s,因为它是由若干个字符组成的,不妨写作
‘ ‘ s 1 s 2 . . . s m " ``s_{1}s_{2}...s_{m}" ‘‘s1s2...sm",
模式串一般记为p,不妨写作
‘ ‘ p 1 p 2 . . . p n " ``p_{1}p_{2}...p_{n}" ‘‘p1p2...pn"
并且
m ⩾ n m\geqslant n m⩾n
现在要判断p是否是s的子串,只要把p中元素跟s中元素逐个比较即可.为了方便,一定是按照从左到右的顺序,具体的过程可以简述如下:
首先拿p1跟s1对齐,判断是否相等,若相等,继续比较p2跟s2,判断是否相等,若相等,继续向下比较,否则,p模式串右移一位,跟s2对齐并继续比较.这里将s和p分别具体化,我做了一个图,读者可以从中体会p移位比较的过程(s不动)
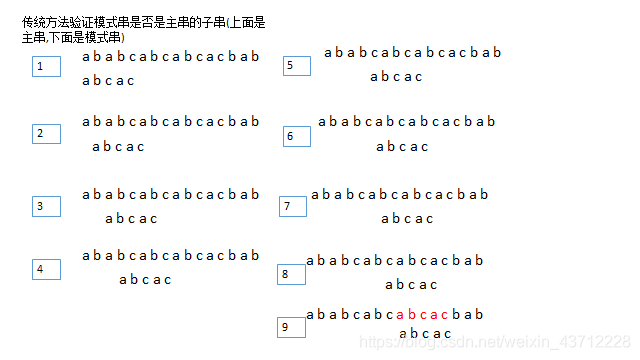
假设主串是"ababcabcabcacbab",模式串是"abcac",固定主串,移动模式串,首先让模式串的第一个字符跟主串的第一个字符对齐并比较,若相等,再比较两者的下一个字符,通过1可以看出模式串的第三个字符c和主串的第三个字符a不匹配,因此将模式串向右移动一位,也就是2这样的情况.由于2中p的第一个字符a跟它对齐的s的字符b不匹配,因而继续右移.因为主串s的长度是有限的,所以,如果模式串p右移到末尾字符与主串的末尾字符对齐时,应是理论上的最后一次比较,如果这一次比较过程中模式串的某一位跟它对齐的主串的那一位不匹配(不相等)的话,就说明这个模式串不是主串的子串,因为模式串已经走到底了,但并没有出现完全匹配的情况.何谓完全匹配?就是说模式串在某个时刻,某个位置,从头到尾跟主串的对应的字符子串完全相同,正如这里第9步,我们可以看到模式串在这个时刻,跟它对齐的主串的相应字符串和它是完全相同的.也就是我标红的部分.这个时候因为找到了完全匹配的情况,就不用再右移模式串了.而要确定模式串不是主串的子串,则要使模式串一直移动到末尾与主串对齐的时刻.这就是我们第这个算法的一个基本分析.
KMP算法
刚才的这种朴素思想的确可以用来解决判断串的模式匹配算法问题.假设主串s长m,模式串p长n,这个思想的算法可以大致写成这样:
def isSubString(s, p):
slen = len(s)
plen = len(p)
#i标记比较的主串的下标,j标记比较的模式串的下标,k标记模式串右移的位数
i = 0
j = 0
k = 0
while i < len(s) and j < len(p):
if s[i] == p[j]:
i += 1
j += 1
else:
j = 0
k += 1
i = k
#如果i=len(s)-len(p),这是最后一次比较,如果完全匹配,if语句不执行,否则说明这最后一次比较有
#不匹配的情况发生,这个时候不用再右移模式串了,因为那会使得模式串的尾部超过主串的尾部,这样做
#可以节省一点工作,同时也为了保证打印出来的k(右移次数)不会超过len(s)-len(p)
if i > len(s) - len(p):
k -= 1
break
if j >= len(p):
print("模式串p是主串s的子串,此时模式串移动的位数为", k)
else:
print("模式串p不是主串s的子串,此时模式串移动的位数为", k)
if __name__ == "__main__":
s = "ababcabcacbab"
p = "abcac"
isSubString(s, p)
p = "abcad"
isSubString(s, p)
代码1
这里用k来记录模式串移动的位数,可以想象,要想确定模式串不是主串的子串,那么模式串一定是右移了len(s)-len§位,这个时候是最后一次比较,这个k也可以看作是模式串跟主串完全匹配时模式串的第一个字符对应的主串的索引.
最坏的情况下,需要遍历到i==len(s),至于每一次比较,其比较次数不会超过n,所以这个算法的时间复杂度为O(m*n)
这种朴素的思想有很大的改进空间,在朴素的思想看来,一旦出现模式串的某个字符跟主串的某个字符不匹配,那么将模式串向右移动一位,这未免过于缓慢,如果可以让模式串移动更多位,同时不必担心会有什么可能导致模式串与主串完全匹配的的情况被遗漏,那么这样的改进无疑会大大减少算法的时间复杂度.我们把模式串的某个字符因为与主串的某个字符不匹配,而将模式串右移,此时应该与那个原来不匹配的主串的那个字符所对应的模式串的字符在模式串的位置(索引)记录下来,整理成一个next数组.
比如说 n e x t [ j ] = k next[j] = k next[j]=k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









