






 文章详细分析了安居客登录过程中的密码加密机制,包括使用RSA加密和时间戳结合的方式。同时,提到了token和finger2的处理,其中finger2是浏览器指纹,相对固定。还讨论了反爬虫的report请求,涉及AES加密的浏览器信息采集和UUID的生成与存储。最后,文章介绍了如何通过Fiddler拦截和替换文件来调试和模拟这些过程。
文章详细分析了安居客登录过程中的密码加密机制,包括使用RSA加密和时间戳结合的方式。同时,提到了token和finger2的处理,其中finger2是浏览器指纹,相对固定。还讨论了反爬虫的report请求,涉及AES加密的浏览器信息采集和UUID的生成与存储。最后,文章介绍了如何通过Fiddler拦截和替换文件来调试和模拟这些过程。
安居客登录参数分析
选择账号密码登录,抓波登录包
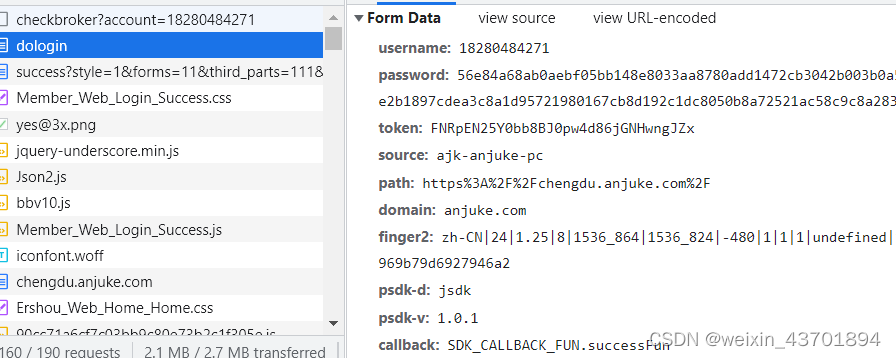
可以看到,参数比较多,我们逐个击破
password
直接全局搜password,只有一个结果,下断点,发现并没有断下来。
搜password的时候,如果细心一点,可以发现CryptoJS这个关键字
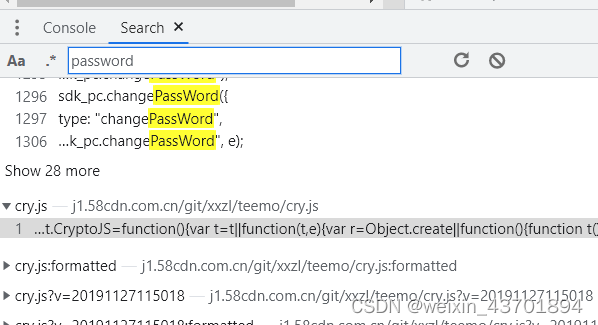
那么我们可以搜CryptoJS这个关键字,好多处可以找到,然后下断点,发现确实断下来了,但是并不是password参数加密的地方
这个时候可以尝试以下三个办法:
- 观察加密结果,猜测是否是常用的加密算法,如RSA、AES等
- 搜类似encrypt、sign等关键字
- 查看调用堆栈(这个请求好像看不到)
在这里的话,前两种方法其实都可以,我们搜encrypt,结果如下,可以看到RSA和encrypt字眼,直接下断点,最后,password加密位置在这里
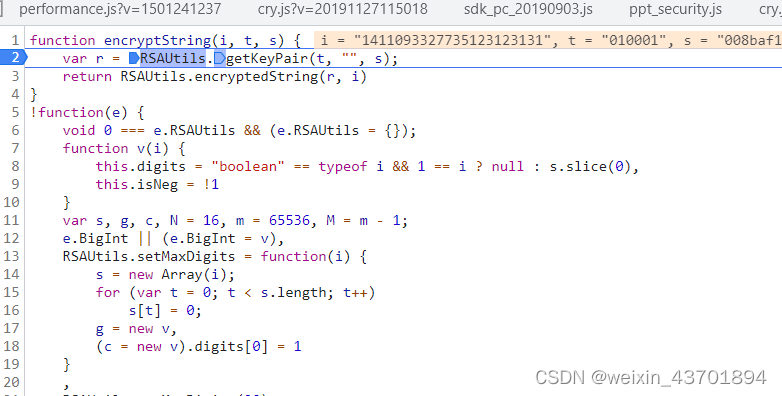
返回上一层调用栈发现会在密码加一段时间戳的计算结果在做RSA加密,然后公钥的话基本是写死的,直接全局搜也能发现确实是写死的。
到这里password就解决了,然后就扣代码了,我是把密码前的时间戳写死的
module.exports = function encryptString(pwd) {
/* rsaModule省略 */
var r = RSAUtils.getKeyPair("010001", "", "rsaModule");
return RSAUtils.encryptedString(r, "1411093327735" + pwd)
}
token
直接搜token关键字,结果太多,不好操作。
直接搜token的值,发现只有一处结果
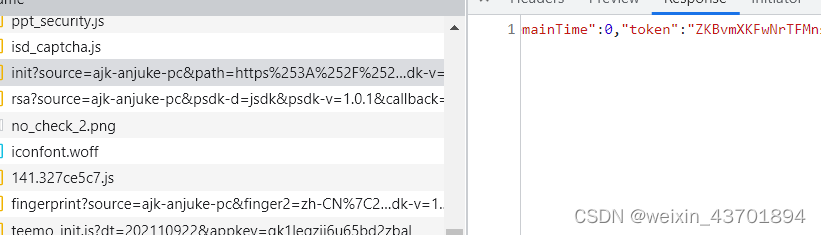
还顺带发现了rsa参数的请求
finger2
顾名思义,指纹,对于固定的浏览器,应该是个定值。
多次测试,确实是个定值
其实到这里已经可以登录成功了

但是其实网站还有其他加密的地方,但是为什么我们没有模拟直接就能登录,我也不太清楚。
浏览器指纹加密
report请求,url中带有antispider字样,明显的反爬虫,请求体也巨长,可以尝试把他模拟出来。
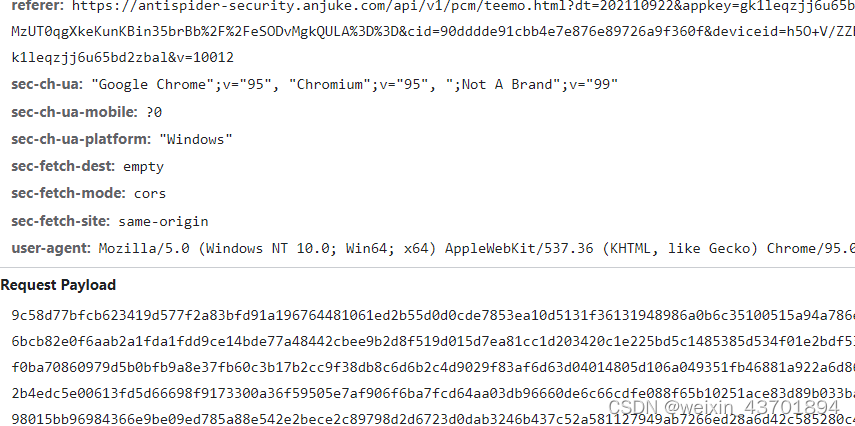
好在这个请求能看到调用堆栈,直接点进去可以看到一段AES加密代码,下断点
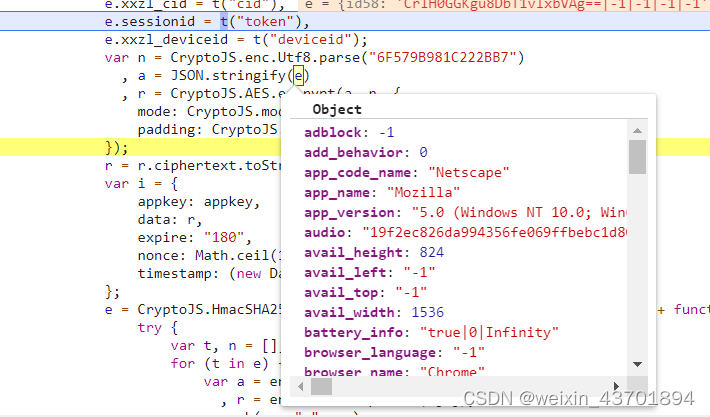
可以看到,对e进行了加密,然后结果巨长,这个e是什么,到浏览器控制台打印一下
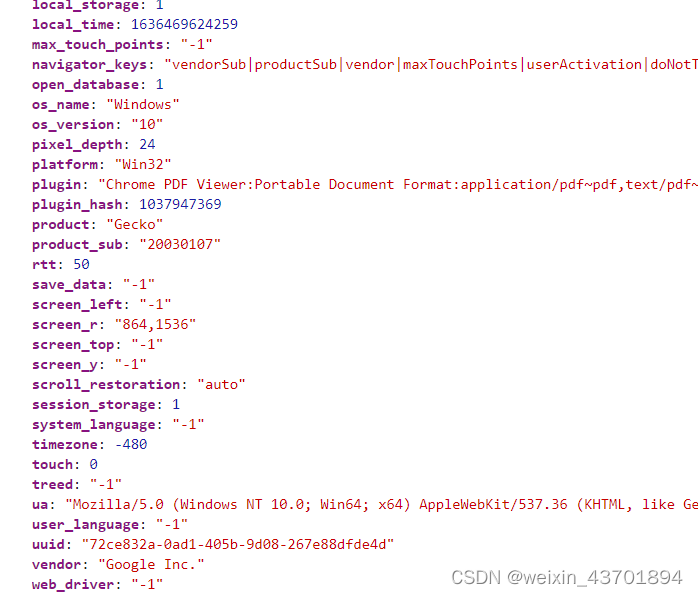
可以看到浏览器的信息被采集了个遍,还有web_driver。
把这个对象复制到IDE,一个个检查,最后总结发现能变得是以下几个,其他的对于固定的机器和浏览器都是不变的。
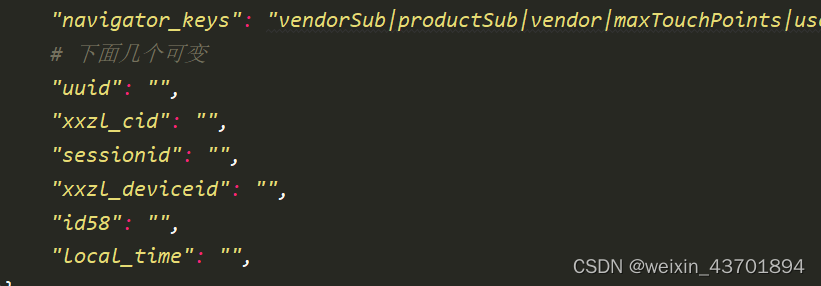
这几个参数来源与前面一个请求密不可分:https://antispider-security.anjuke.com/api/v1/pcm/gettoken
这个请求,参数是加密的,返回结果也是加密的
好在直接也可以查看调用堆栈,然后直接找到加密位置和解密位置
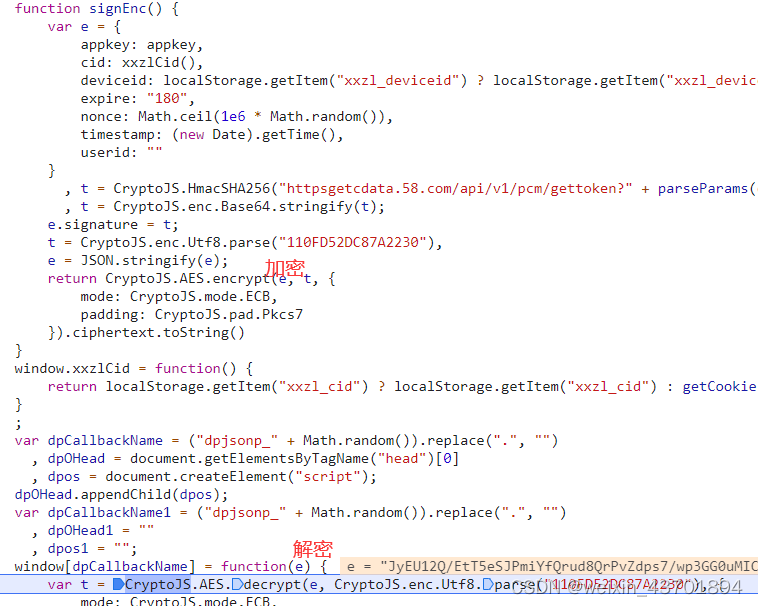
综合上面两个请求,逐步调试分析可以发现每个参数的来源
- uuid:请求gettoken时不携带此参数,report请求返回的结果会返回服务端产生的一个uuid,客户端收到后,保存到浏览器cookie、localStoage、sessionStorage中,三者互相定时查找对方获取值。所以当时调试时,发现怎么都删不干净这几个参数,花费了较多时间。最后用fiddler拦截,替换掉了互相获取值的定时函数,才发现这几个参数的生成规律。替换的JS文件是teemo_core.js中的pollEvent和monit,具体可查看相关文件。
- 其他几个参数都是gettoken解密后的结果中获取,如下
res = session.get("https://antispider-security.anjuke.com/api/v1/pcm/gettoken", params=params, headers=headers) enc_data = re.search(r"\('(.*?)'\)", res.text).group(1) data = session.post("http://127.0.0.1:8000/decrypt", data={"data": enc_data}).json()['data'] cid, deviceid, token, _ = data.split('') from browser import browser_feature browser_feature['xxzl_cid'] = cid browser_feature['sessionid'] = token browser_feature['xxzl_deviceid'] = deviceid browser_feature['id58'] = session.cookies.get("id58") + "|-1|-1|-1|-1" browser_feature["local_time"] = str(int(time.time() * 1000000))
然后对浏览器指纹进行加密后就可以发起report请求了,然回结果中包含uuid,也是cookie中的xzuid
总结
这次逆向有两点新的东西
- 浏览器的本地存储,还可以操作浏览器的数据库,对于调试工具中的Application板块有了解
- fiddler中间拦截,并替换文件
代码:Github

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









