







1.给定100亿个整数,设计算法找到只出现一次的整数?
分析:100亿个整数大概占用40G内存空间
数据出现的次数分为3种:出现0次、出现1次、出现2次及以上
使用位图来解决问题,两个位表示一个整数:00、01、10

2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
方案一:将其中一个文件的整数映射到一个位图中,读取另外一个文件的整数,判断在不在位图中,在就是交集,消耗500M内存。
方案二:将其中一个文件的整数映射到一个位图中,将另外一个文件的整数映射到另外一个位图中,然后将两个位图中的整数按位与。与之后为1的位就是交集,消耗1G内存。
3.给定一个有100亿个整数的文件,1G内存,设计算法找到出现次数不超过2次的所有整数?
还是用位图解决,两个位表示一个数。出现0次 00表示,出现1次 01表示,出现2次 10表示,出现3次及以上的 11表示。
4.给两个文件,分别有100亿个query,只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
分析:query一般是sql查询语句或者网络请求的url等,一般是一个字符串
假设一个query 30–60字节,100亿个query大约占用300–600G内存
近似算法:将文件1中的query映射到一个布隆过滤器中,读取文件2中的query,判断在不在布隆过滤器中, 在就是交集。
缺陷:交集中有些数不准确,因为不同的字符串可能会映射到同一个位置。
精确算法:这两个文件都非常大,大概在300–600G之间,也没有合适的数据结构能直接精确的找出交集。文件很大都不能放到内存中,那么我们可以把文件切分成多个小文件,小文件的数据可以加载到内存中。一般切出来一个小文件的大小能放进内存中就可以。那么这里一个文件300–600G,切1000份,一个文件300–600M,这里有1G内存, 所以可以。
如果是平均切分,那么A0可以放到内存中存储到一个set中,B0–B999小文件中的数据都要和A0比较,以此类推,A1放到内存中后,也要和B0–B999小文件中的数据比较。可以看到这里的优势就是比较的过程放到内存中,但是这里要不断的互相比较。
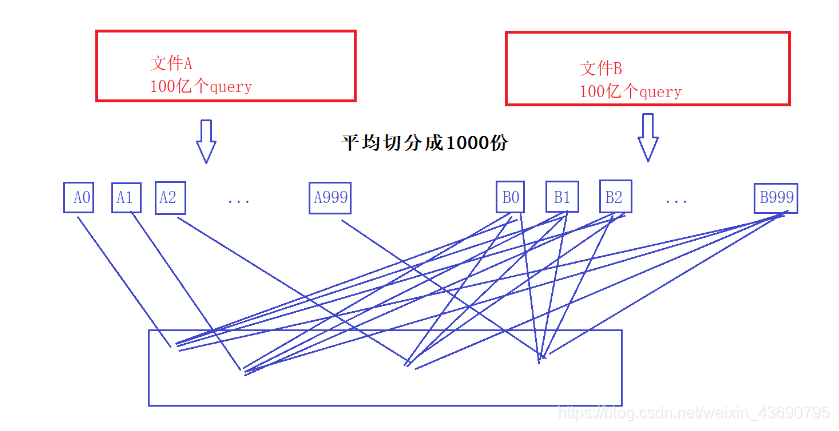
那么还有没有对上述方案改进优化的思路?
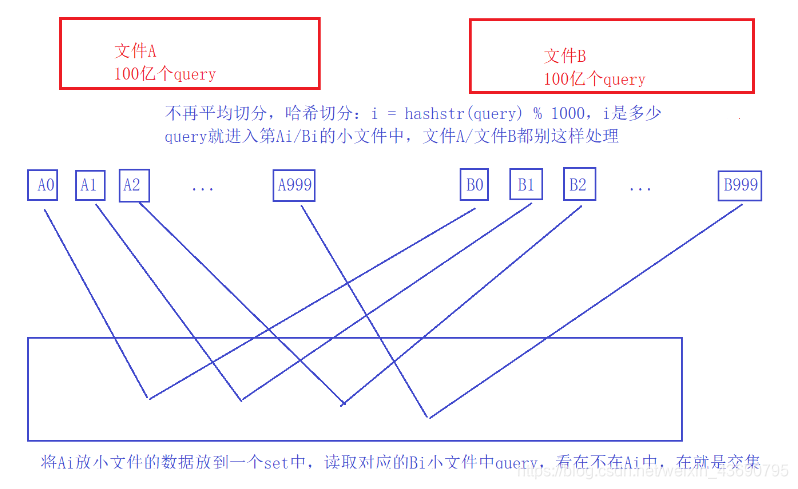
A和B中相同的query一定进入编号相同的Ai和Bi小文件,所以只需要编号相同找交集就可以。
5.如何扩展布隆过滤器使得它支持删除元素的操作?
因为不同的字符串可能会映射到相同的位,如果删除字符串更改位就会影响其它的字符串,因此可以把每个位标记成计数器。
那么到底用几个位来表示计数器呢?给的位如果少了,如果多个值映射到一个位置就会导致计数器溢出。比如1个byte最多计数到256,假设有260个值都映射到一个位置,就会出问题了。
但是如果使用更多的位去映射一个位置,空间消耗就会大。布隆过滤器特点就是节省空间。
6.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?
分析:首先这里要做的是统计次数,我们一般用kv模型的map解决,但是这里的问题是有100G数据,放不到内存中。

如果要找 topK,可以用一个堆来搞定。
7.一致性哈希?
首先我们来看一个案例:
一般情况下现在的一台电脑内存是4–8G,硬盘是500–1024G
假设我们要存储每个人的微信号和他的朋友圈信息,并且要方便快速查找。<微信号,朋友圈>
我们现在真正需要考虑的是服务器存储数据的问题,因为微信有大概10亿用户,假设平均一个用户的信息是100M,那么大概需要(10亿 * 100M)10wT的空间,也就是差不多需要10W台服务器来存储。
多机存储,还需要满足增删查改数据的需求。
分析:用户laoganma发朋友圈了,插入到哪台机器?浏览和删除朋友圈去哪台机器查找?
用户的朋友圈信息存储和机器建立一个映射关系,比如laoganma的信息存几号机器呢? i = hashstr(laoganma) % 10w,i是多少,laoganma的信息就存到第i号机器。实际中可以用一台额外机器存储机器编号和IP的映射关系,这样算出是第i号机器,就可以找到他的IP,也就可以访问服务器了。
上面方案的缺陷:假设随着大家发朋友圈越来越多,或者用户量继续增长,10w台机器不够了,我们需要增加机器到20w台,那么之前10w台机器上的数据映射关系就不对了,就需要重新计算位置迁移数据。
一致性哈希:

比如:计算10000–20000范围映射3号服务器,现在增加机器后,那么10000–15000范围映射到新增机器x,迁移3号服务器中映射在10000–15000范围的数据到新机器x即可。
总结:一致性哈希就是给一个特别大的除数,那么增加机器 也不需要整个数据重新计算迁移。它是一段范围值映射到一个一台机器<x1 - x2, ip>,那么增加机器只需要改变映射范围即可,且迁移极小部分的数据。
推荐文章:一致性哈希详解

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









