






 文章详细讨论了电商项目中订单模块的复杂设计与优化,涉及订单分表、防重复下单策略、使用布隆过滤器判断订单是否存在、库存控制的ABA问题、分库分表与读写分离的实施,以及分布式ID和分布式事务的选择。同时强调了缓存技术如Redis在高并发场景中的应用。
文章详细讨论了电商项目中订单模块的复杂设计与优化,涉及订单分表、防重复下单策略、使用布隆过滤器判断订单是否存在、库存控制的ABA问题、分库分表与读写分离的实施,以及分布式ID和分布式事务的选择。同时强调了缓存技术如Redis在高并发场景中的应用。
在电商项目中,我们针对一些核心业务,比较复杂的业务需要做一些设计以及优化的过程
首先我们针对于订单的模块拆分了2个子模块
1.order-curr实时下单业务
2.order-his 做一些历史的订单归档
我们的订单业务
>商品添加至购物车
>购物车结算--> 订单确认页
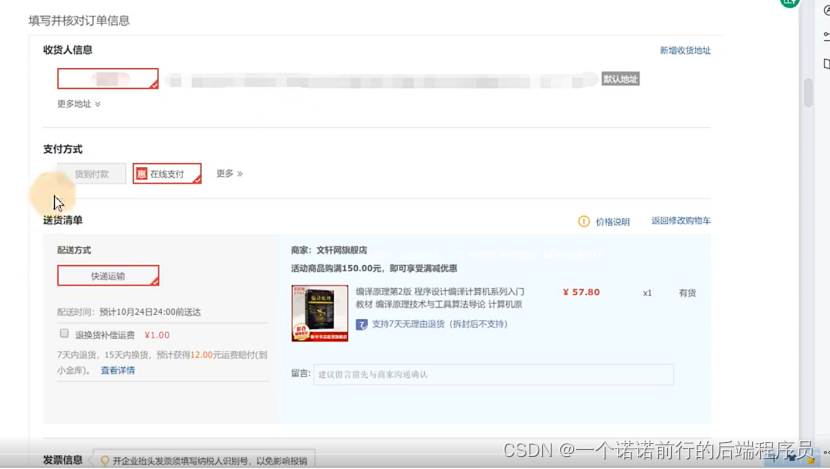
>填写信息 提交订单--》订单支付页
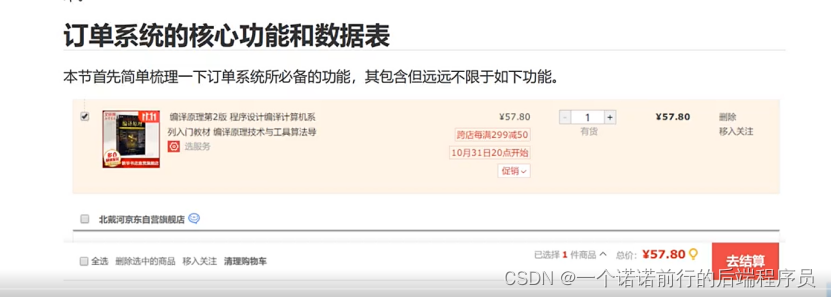
购物车结算页
填写信息 提交订单
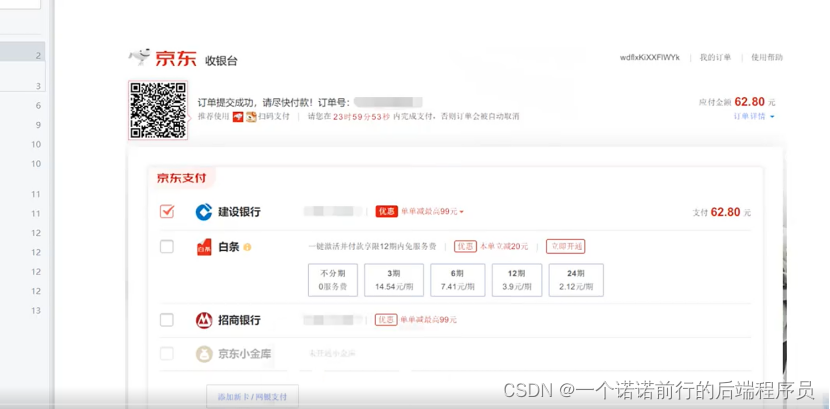
支付 这就是我们整个订单的详情,这种业务在高并发情况下该怎么做优化呢
1.> 我们在做设计的时候,针对于订单表做分表处理 我们可以考虑数据量做分表操作
在整个下单业务会出现什么过程呢
1> 重复下单 基于一个商品下2个单, 这种就会容易产生重复下单的问题 基于这种问题,会加一些Js的控制
比如说 点击一次结算,将按钮置灰
但是,在前端控制的时候他安全性不高,比如说黑客可以直接跳过前端发送请求到后端,这种情况下前端控制的就会安全性不高
怎么防止重复下单
用户F5刷新进入页面的时候 先生成这个id 保存在页面中, 当提交订单的时候,订单号随着业务数据一起传输到后端进行传输
这样的话 即便点击多次提交订单,每一次提交的订单号都是一样的 我在后端根据这个订单号就可以判断有没有下单
也就是我后端提供这2个接口就可以了
前端传了这个订单id 我们怎么来判断这个id 有没有下过单 insert的时候就会报错
或者我拿这个订单我去db 中去查询一下
=================>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
不查数据库有什么方法来判断这个订单是否重复 布隆过滤器,我可以基于布隆过滤器来判断这个orderId有没有下过单
布隆过滤器可以借助于redis分布式缓存来做
还有下单的时候会查询库存,如果超卖的时候该怎么办 ABA 问题
我们可以增加个版本号来控制
我们可以增加一个版本号来判断 我们增加一个vision 字段 来做版本控制
对于分库分表的处理 能不分就不分,因为随着数据库的分库分表,会有很多问题的要考虑
我们此时要考虑分库分表
1> 提高我的数据存储性能,我数据量过大 我单表存不下
2> 也要考虑我服务器查询承载的情况 ,比如说数据在一个库中的化,查询慢,很多查询集中在一个库中此时压力会变大
--------------------------->>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>.
分库分表的一方面是提高数据的承载量
另一方面是提高他的查询性能 这也是我们要设计分库分表要考虑的东西'=
提高查询性能 我们可以考虑读写分离的方案
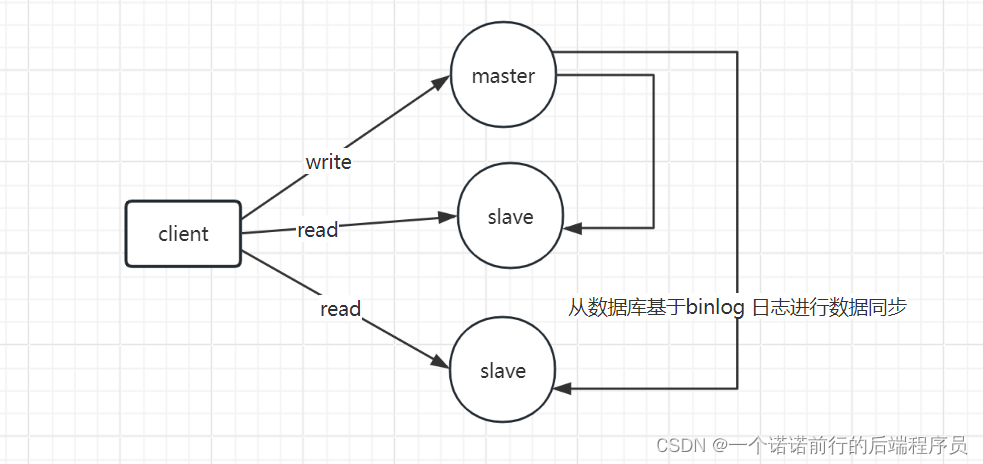
读写分离,原本我的数据部署在一个库中
我做读写分离 首先需要 针对于每一个数据库搭建一个从数据库,从数据库基于mysql的binlog 的主从同步机制去做数据的同步
服务器将select的请求路由到slave上,将insert请求路由到master上, 这样就形成了一个读写分离的方案
我原本数据库要承载很多数据的请求,包括 write和read
现在做了读写分离,主库只负责写入,这部分占比是比较低的
对于读多写少的场景,读写分离式很合适的,另外读请求分配到从库中, 从库也可以做水平扩展
有更多的从库就可以进一步分读数据的请求了
在高并发场景下 我们主库都会搭建一个从库 目的就是为了体现读写分离的 思想
读写分离可以解决数据读取压力大的问题 ,但是他不能解决单表数据量大的问题
我们还需要进行分库分表处理 我们该怎么落库一个分库分表的项目
1> 我需要对我的数据进行一个预估,预估我数据量有多大,也就是说我要拆分多少个表,根据业务量来预估我们要拆分多少个表 我们要对数据的预估,以及数据的增量进行一个预估
我们根据当前实际情况预估32个表
确定好规模之后 我们的指定一个策略, 我们到底怎么分库分表
有很多方案去选择,既要考虑数据分布的均匀 也要考虑很多场景
最简单的方式 就是基于orderId进行取模 比如说1放在第一个表中,这就是最简单的分片操作
--------------------------------->>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
分片键该怎么去选择,选择区分度比较高的数据orderId(唯一独立) 如果分片键仅仅是orderId这个字段的化,
呢么此时根据memberId是没有办法确定那个分片的
我们基于memberId来查询的时候 就只能全路由分片
所以我们要考虑分片键的化,还得依托于我们的需求
如果未来有memberId的化, 在生成分片键的时候,我们可以将用户id和orderId综合来考虑
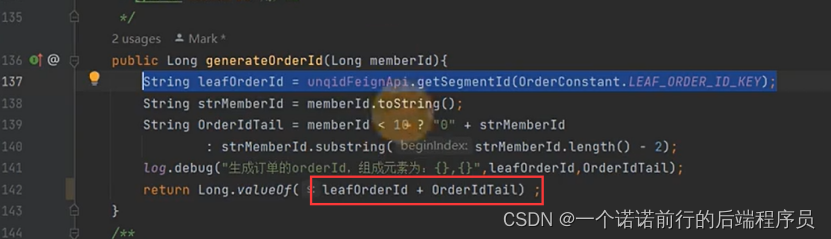
这样不管是用orderId 还是memberId 都可以查到那在那个表中了
我再进行取模的时候 orderId的后2位置就是memberid 的后2位
这样就可以兼容 基于订单id和用户Id来查我也能确定用户再那个分片
主键生成策略 弊端就是只能支持2个字段,未来如果加上其他字段 比如说商户 就不能够支持了
orderId +memberId 这种只能够兼容2个字段 这种方式 如果有多个字段 我们这种方案就不适合了
我们选择了 订单id+userid这种分片键之后 接下来我们要实现分片算法
我们为了兼容订单Id 和用户id 2中方式
我的数据插入数据库是怎么插入到每个表的, 我查询的时候就该怎么去查询
1.我们做分库分表 第一基于业务来做数据量预估 以及数据增量的预估 来确定我们 拆分 成多少个表
2.我们指定一个策略 数据分片策略 纪要考虑数据的均匀分片也要考虑场景
1.%取模 数据比较均匀 以后扩容难度大
2.按照年份分 数据不均匀
电商项目中分布式id服务端实战 分布式id是一个所有服务都要有的基础底层服务
简单场景下,数据库的自增就是最好的解决方案
但是此时我们的订单已经做了分库分表了,分表的场景下就不适合使用数据库的自增id了
呢我在分布式场景下该怎么考量分布式id呢 需要从几个方面下考量
>1.全局唯一性
>2.趋势递增 在业务上有一个比较明显的体现
>3.信息安全 可以连续,但是规律不能够太明显 比方说我的竞争者今天下订单订单号为001 明天下订单 订单号为100 呢么他就会知道 我今天下了多少个订单了
同时我们还希望我们的分布式id 服务可以做到高可用(能抗住高并发流量)
呢么基于这些方案 我们可以考虑的是
uuid
雪花算法
美团的leaf
如果递增的化 我们还可以使用redis 的incr 或者zk来做这个分布式唯一Id
读写分离在我们项目中的实现,我们电商项目面临很多的第三方服务
比方说MySQL 但是mysql 他的数据存储的性能以及读写请求这种处理并发的能力 又是最容易成为整个电商项目的瓶颈的
所以需要对mysql 做很多优化 在我们的项目中 我们增加了redis集群以及本地缓存
也就是说对mysql做了一层流量的保护, 我们将一些数据放进redis中,先从redis中去读 这样的话 就减少了
针对于Mysql的请求,对于读多写少的场景 不容易改变的数据我们可以使用redis 来进行存储 比如说首页数据
类似于我的订单这种 情况下不适合用redis 因为i每个人看到的和每个人不一样
读写分离 是mysql 提升并发的首要方案
读写分离的第一步就是将这个节点配置一个备份节点SLAVE 备份master的数据
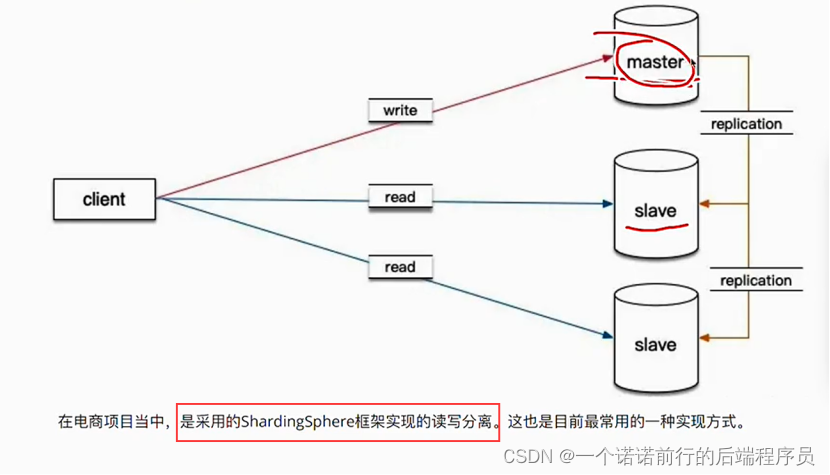
然后 我在应用层做一些设计 将我一些写数据的请求发送到master上,将一些读数据的请求发送到slave上
这就是读写分离的方案 比如说像查询订单这种数据都是读多写少的情况
采用这种读写分离的方案后 针对于写的压力可以放在原来的数据库中
对于读的请求,我可以路由到从节点上,我们在读写分离的架构中 我还可以水平扩展多个slave 也就是说我备份一个slave不够 我还可以多加几个备份 用这些备份来共同承担客户端的请求 我们可以增加多个备份来提升他的读的性能
读写分离整体分为2步
1> 在数据库层面 要形成这种主从备份的机制 搭建一种主节点 从节点这种备份机制
一旦master节点改动 这些改动都要同步到slave从节点上
另一个就是应用层面,应用层面中要对不同的sql,发到不同的数据库中去
(将select 请求路由到从库中 将insert路由到写库中)
一个是数据库要形成这种主从备份的机制
另一个是应用层面形成这种sql的路由机制
数据库层面 mysql 他的数据库同步方案 在master节点要打开binlog日志
需要我们更改配置文件来开启这个binlog
在从节点上 第一个监听binlog日志 如果master的binlog发生改变 就会写进自己的relaylog中
然后启动另外一个线程 在自己的数据库中执行relaylog,通过这种方式就可以达到主从数据一致性
也就是说master节点的数据就会同步到从节点slave中
我们的项目搭建了主从
针对于核心业务服务 做一些设计和优化
1. 订单服务拆分了2个 一个 实时下单的业务 一个是对历史业务做的一些归档
2. 订单业务的流程
3. 在这个流程过程中出现什么问题 以及怎么处理和解决
1> 重复提交 订单id提前生成在页面中 然后发起生成订单的时候
将对应的业务数据和订单id 提交到后台 这个时候后台就知道是否重复提交了
2> 针对于订单表 我们要做分库分表
3. 出现ABA 问题我们可以使用版本号来进行Update
4. 基于分库分表 我们能不分就不分 因为分库分表会出现很多问题 分布式事务
1. 提高数据存储
2. 提高查询性能 分库分表后 数据散落在多个表中 就可以提高我查询性能
提高查询性能我们也可以采用数据库的读写分离的方案
1. master搭建一个从库slave, 从库基于Mysql的binlog日志读取数据 https://www.cnblogs.com/interface-/p/17160886.html
2. select请求路由到slave上,insert 请求路由到master上,基于shardingjdbc做数据路由
这样就形成了一个读写分离的方案
= 读写分离解决数据读取压力大的问题,但是他不能解决单表数据量大的问题
我们还要考虑分库分表 怎么落地
1>对数据的估算 以及数据的增长量来估算 拆成多少个表
2>分片策略 1.取模 2. 按照时间来做 (优缺点)
3. 分布式id 底层服务
分布式id 怎么考量
1.>全局唯一
2.>趋势递增
3.>信息安全
4.>高可用
1.如果是单机的情况 可以采用mysql的自增id
分布式id
1. uuid
2.雪花算法
3.美团的leaf
4.redis的incr或者zk来做 如果递增的话
---------------------------------------->>>>>>>>
redis 缓存来降低对Mysql的压力(读多写少的情况下 首页数据)
读写分离
2023 12.31
--------
2024 01 03
我们的项目搭建了主从,我们在主节点上做的任何数据变动就会同步到从节点中,比如说主节点有任何的数据变动,从节点都会跟踪到这些变化,然后更新到自己的环境中 这是第一步就是在db层面上形成这种主从备份的机制,
然后在应用层面 我们还要按照sql 语句去划分
比如说select 我就路由到从库,insert 请求路由到我主库中
我们使用shardingsphere 来实现这种路由机制 mycat 也可以这样做
我们项目中使用shardingsphere 来帮我们做读写分离
关于读写分离的配置 核心在于配置
通过读写分离 数据库支撑的并发量就会上来 所以性能会变得大一些
所以读写分离是我们在使用Mysql中首要考虑的一点 扩展方案
----------------》》》》》》》》》》》》》》》》》
读写分离也是有一些问题的,读写分离数据不一致 因为我数据写进master ,我从Master同步到slave的时候是需要跨网络的 他是有性能损耗的
master 配置的slave不能太多,如果太多的化 数据同步就会更长 也就是说你数据不一致问题就会变得更加严重一些
怎么解决数据不一致
不管你框架怎么优化,数据同步是需要时间的,很难说从技术上保证强一致性 所谓的强一致性就是说 我不管任何时刻
我在集群中读取到的数据都是一致的
mysql 这种跨网络情况是没有办法保证强一致性的
所以大部分情况下 我需要通过一段时间来查询 通过这种手段来保证我最终一致性
我们在电商场景下还要做一个日志的备份 我们会将mysql 的数据定期的移动到Mondb
备份数据我们也是采用主从同步的方式 使用cancl 做数据的同步备份
分库分表在电商设计中的设计和实现
上一节讲的是读写分离,既然我们要谈分库分表 我们为什么要分库分表
我们数据量上来了,请求更加频繁了,mysql撑不下来了,所以此时要做分库分表来处理
既然Mysql 撑不下去了 为什么不用一些大数据产品呢 比如说es hbase clickhouse之类的
这些产品支持一些大数据产品,并且查询性能都不错
因为mysql oracle 这种关系型数据库 他们的事务是完整的
我们的下单业务场景,涉及到数据库的联动,库存扣减,写入订单表 事务是一致的
这些在一些数据库是不好体现的,比如说es 这种 ,很难保证多个索引是一致的
所以在做数据存储的时候,针对于这些不太会产生变动的业务数据,比方说订单 这种 历史数据我们会存储在大数据产品中
对于这种刚下单的数据,一方面写的时候要保证对应的事务,因为他会产生变动
下订单后我可能还要修改状态,回滚数据之类的数据变动
所以我们会考虑mysql,只不过我们mysql 的数据存储一段时间就会变大了,再将它存储在大数据中
我们为什么要做分库分表 我们的数据量变大了 我们就要做分库分表
基于阿里手册 我们考虑2个标准 一个是数据的行数 一个是数据文件的大小
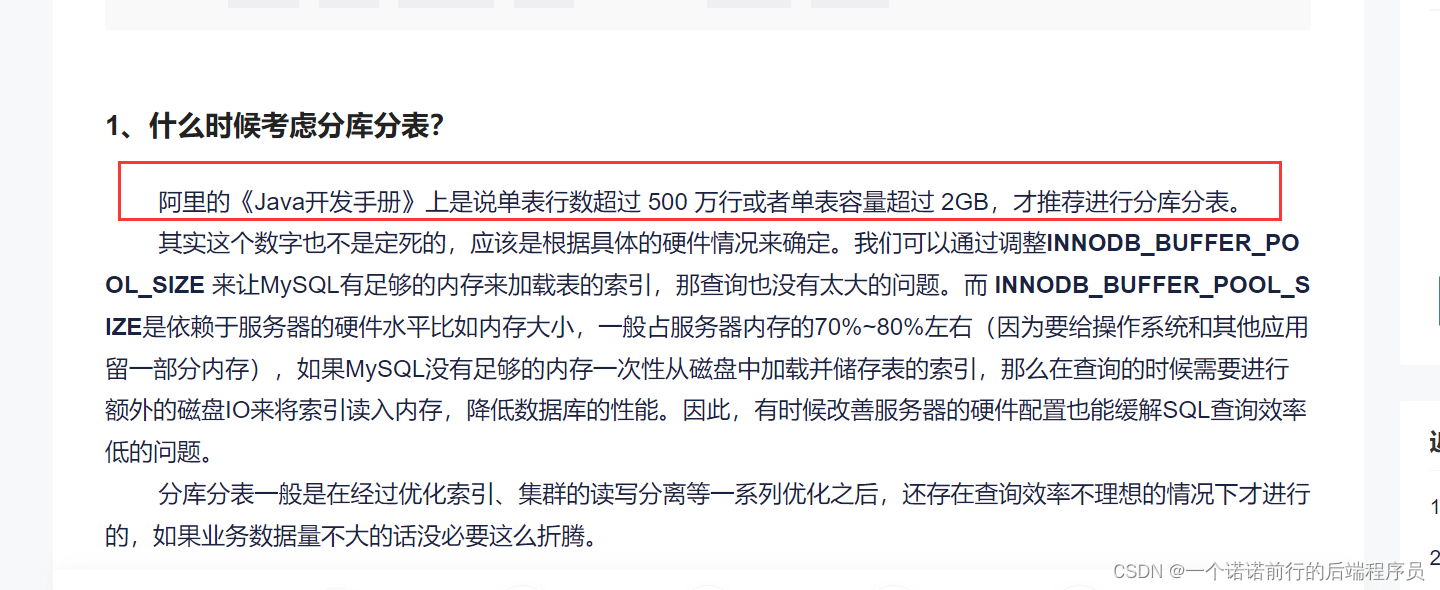
也就是我们考虑分库分表第一步就是对数据的预估以及数据增量的预估 基于业务以及对数据量的预估做表的拆分
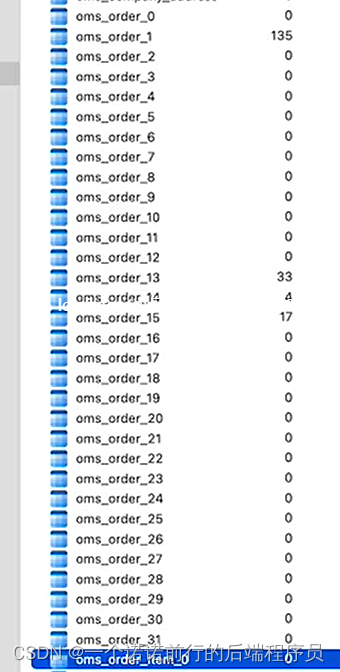
我们第一步是分32个表 第二步需要落实这些方案
确定分片规则,就是我的表是按照什么字段来拆分,怎么选择分片键
订单id%32 这就是个简单的分表策略
我们当前项目中还有一个场景就是按照用户id来查询
如果我们只是按照id%32 呢我用户此时来查 因为我的数据是按照id来分片的,所以此时如果按照用户来查询的化
就是全量表扫描
我们可以这样 id+memberid的后2位
订单id 3306
用户id 0054
我们的订单id 330654
在生成订单的时候就给他制定好规则
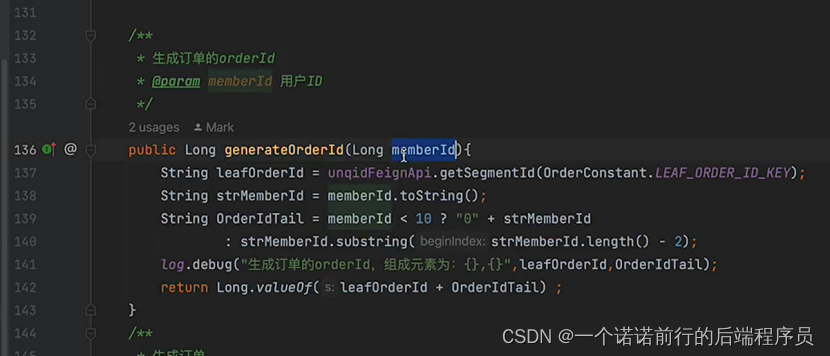
我们通过这种方式将memberId整合到orderId上了,作为orderId的一部分
然后在进行具体分片算法实现的时候 将orderId 取模进行拆分到不同的表
这个就达到一个效果 我根据memberid就可以查到我的订单, 我根据用户id也可以查到我的订单
这就是我们分片键的处理,
----------------------------------------------------------------------------------------->
我们会定期将一些数据定期的迁移到mondb去做备份
我们之前在订单系统中做过很多分享 其实我们之前设计的核心问题就是在高流量高并发场景下 我的订单数据
可以快速查询,快速入库 并且可以支持实时业务的一些简单的查询
我们需要对这种实时业务数据迁移到大数据产品中来做历史数据的归档
我们的电商项目 针对于历史的订单数据 怎么去做归档的设计,还有实现过程中需要注意那些问题
数据归档的目的就是为了提高我查询性能 数据量越大 数据库查询就会越慢,这也就是我们之前要做数据库分库分表的设计的原因
mysql单表存储数据的量很多,但是我们还是要做数据的分库分表,其目的就是减少mysql单表的数据量,这样有助于提升单表查询性能
所以分库分表只能解决实时问题,针对于海量数据的历史数据,还是不可能存储在mysql中 我们的核心就是考虑对数据查询的性能
mysql 采用b+树的数据结构
我们分库分表是优先支持这种实时订单的查询
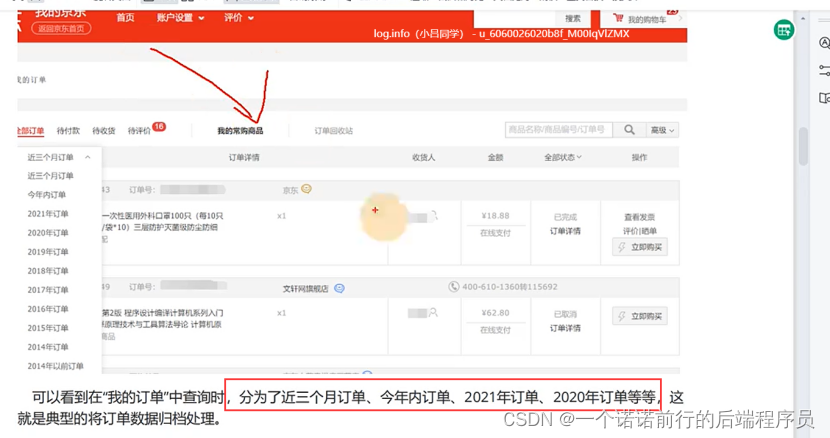
但是我们如果对这种历史订单数据的归档查询, 我们就需要用es之类的大数据产品来做了
我们将数据从mysql迁移到mongodb中做数据的历史归档
es hbase clickhouse这些都是一些可选择方案 只不过我们目前采用的是mongodb做数据归档
我们从mysql到mongdb做迁移,我们要设计一些接口 的功能
1.数据的迁移从mysql--->mongdb完成数据从mysql到mongodb做迁移
2.停止迁移
3.恢复迁移
我们在设计的时候要考虑这个任务,我可以随时停止和恢复,因为我在做海量数据迁移的时候 大量数据转移一定会影响你数据库的性能 影响到你实时业务的性能要求
此时针对一些实时业务,就会容易产生一些影响,所以此时要考虑我后端做数据迁移的时候 尽量的不影响我实时业务,所以此时可能需要对任务进行终止,比如说我迁移任务执行过程中来一个秒杀活动,此时就得停止迁移的任务,保证我实时业务的正常进行(优先支持秒杀服务) 等秒杀高峰期过了 再来做数据迁移
从mysql中查询数据,然后迁移至mongodb 然后再把mysql的数据删除了,既然我数据已经迁移至mongodb了,呢么我在mysql中就不需要了,这样才会减少mysql 的数据量
还有我们在做数据迁移的时候 一定不能对这种海量数据直接全量迁移,我们可以按照批次来全量迁移
每次查数据只查这一批数据,我们可以进行压测 看看整个迁移服务采用多大的批次对你业务的影响是可以接受的
这样我们可以规避迁移过程中对服务器性能的影响, 让影响变得可以接受,因为数据迁移会影响你实时业务,比如说下单
我们可以采用xxjob 来做任务的调度,比如说我可以设置晚上12点对任务进行调度 到了早上6点 我就要停止迁移
我们可以使用xxjob 进行任务的调度
这个就是我数据归档的过程和思路 通过整个归档的过程就可以定时的将订单数据从mysql迁移到mongodb当中 我历史数据查询就可以从mongodb 中来查询
我们已经讲了有关订单方面的优化,比如说读写分离,分库分表,海量数据的处理 其实
在微服务场景下,还有一个分布式事务,分布式事务很难避免
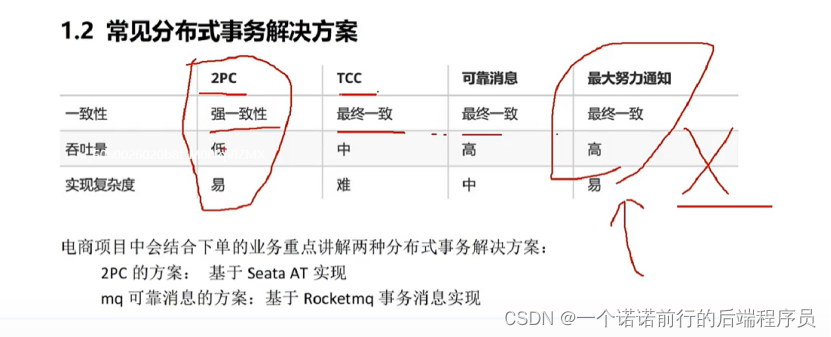
分布式事务的技术选型很多,具体在我们项目中怎么落地结合我们项目去实战,分布式事务的方案在我们项目中怎么使用
分布式事务 我们用到的最多组件就是seata 在电商项目中很多场景都会用到分布式事务 要么一起成功要么一起失败
分布式事务的场景
用户下单 去冻结库存 下单成功了要扣减库存
分布式事务场景进行讲解
下订单 要去锁定库存 此时是一个openFeign的远程调用
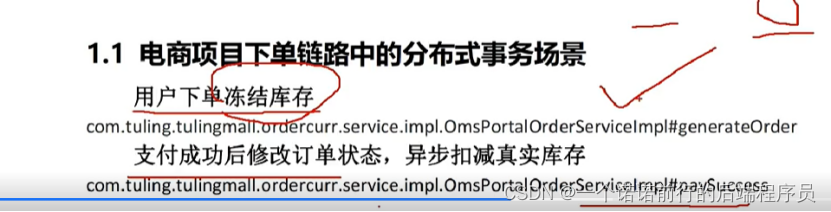
下订单 要去锁定库存 此时是一个openFeign的远程调用
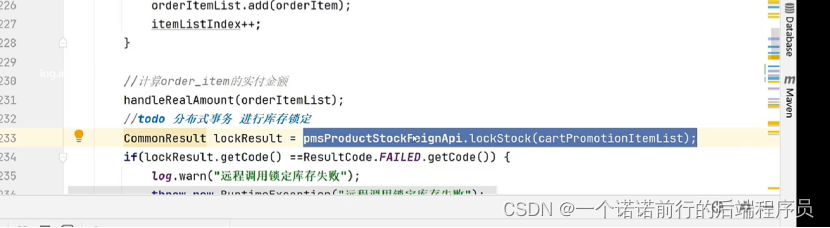
我们支付成功后修改订单状态 要去对我们真实库存的扣减
我们支付成功后修改订单状态,要去对我们真实库存的扣减,分布式事务的方案
我们用户下单冻结库存,我们采用基于seata的at方案
支付成功修改订单状态状态,我们可以采用rocketmq的事务方案
我们项目中使用分布式事务的2个场景 以及我们选择的方案 第一个 场景就是采用seata的at模式
本地事务提交,避免了传统2pc,会锁定连接对象的问题,
在seata的at模式中第一阶段直接提交本地事务
https://blog.youkuaiyun.com/weixin_43989347/article/details/123954734 seata
xa
1.> 执行业务sql 但是不提交事务 上报分支事务
2.> 提交事务/回滚事务
业务性能篇
我们在完成核心业务后,我们还要考虑我们的烯烃具备承载 高并发 高流量的能力
高并发的缓存方案
缓存的方案redis,我们通常使用mysql+redis就可以来使用缓存解决高并发的问题
缓存的作用,不仅仅采用redis这么简单 我们要考虑整体的缓存方案
对于一个完整的缓存设计,大概分为3种
1>客户端缓存
2>网络缓存
3>服务端缓存
数据在整个缓存链路的位置
客户端缓存 页面缓存,比如说将数据存储在用户浏览器中 比如说localstorage
浏览器缓存 动静结合只需要用ajax 来渲染数据 而不渲染页面
client--------->nginx--->service
我们可以采用nginx做反向代理,我们将某一些数据,放在nginx当中,
比如说静态页面html 我可以直接将这些页面放在nginx中
cdn 我可以建立很多内容分发的节点 比如说我可以在北京做一个节点 我未来北京的用户就可以访问到北京的节点 直接获取到数据
我们也可以进行服务端缓存 提升我服务端的响应能力
我们考虑数据端缓存 应该从那些方面来考虑
1、数据库 数据库调优
2. 应用级别缓存 ecache gava
3. 单独搭建一个平台级别的缓存 比如说redis


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









