







文章目录
- 一、模型部署-CNN
- 二、模型部署-YOLOv8检测器
- 三、部署BEVFusion模型
- 1)Overview-and-setting-environment (分析CUDA-Fusion的优化策略与环境搭建和测试)
- 2)About-spconv-algorithm(学习spconv的原理,处理3D点云做高效卷积)
- 3)Export-SParse-Convolution-Network(学习导出带有spconv的SCN网络的onnx)
- 4)Spconv-with-Explicit-GEMM-Conv(显性GEMM conv 是怎么优化的)
- 5)Spconv-with-Implicit-GEMM-Conv(隐形GEMM conv是怎么优化的)
- 6)BEVPool-Optimization(学习BEVPool的优化方案)
- 7)Analyze-each-onnx(分析BEVFusion中各个onnx)
- 8)CUDA-BEVusion-Framework-Design(推理框架设计模式)
- 9)BEVFusion initialization
- 10)cordTrans Precomputation
- 11)BEVFusion-forward
一、模型部署-CNN
1)preprocess-speed-compare(CPU去做图像加速怎么做)
(1)实现一个触发CPU端前处理的性能比较(比较对于访问cv::Mat的数据,哪一种更快)
-
为什么要把前处理放在CPU上?
图像的前处理部分如果放在PGU上面跑(图像没有那么大,很小的图像),并不能充分的硬件资源吃满,导致硬件资源浪费。然后DNN的前向推理forward部分放在GPU上,进行异步的推理 -
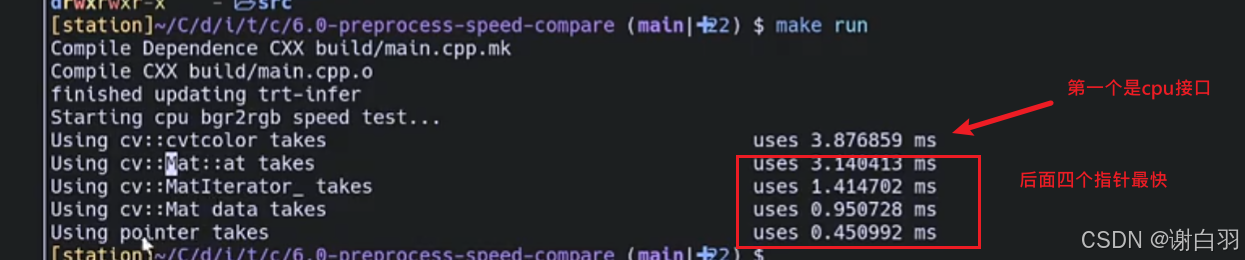
比较的的是四种方法
①cv::Mat::at
②cv::MatIterator
③cv::Mat.data
④cv::Mat.ptr -
速度效果比较(Ptr是最快的)
-
cv::Mat.ptr的代码
void preprocess_cv_pointer(cv::Mat src, cv::Mat tar){
for (int i = 0; i < src.rows; i ++) {
cv::Vec3b* src_ptr = src.ptr<cv::Vec3b>(i);
cv::Vec3b* tar_ptr = tar.ptr<cv::Vec3b>(i);
for (int j = 0; j < src.cols; j ++) {
tar_ptr[j][2] = src_ptr[j][0];
tar_ptr[j][1] = src_ptr[j][1];
tar_ptr[j][0] = src_ptr[j][2];
}
}
}
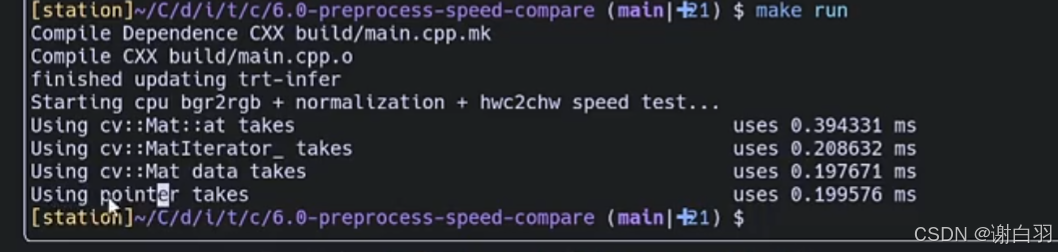
(2)还比较CPU端做bgr2rgb,和bgr2rgb+normalization+hwc2hw的性能比较
-
比较的的是四种方法
①cv::Mat::at
②cv::MatIterator
③cv::Mat.data
④cv::Mat.ptr -
结果时间比较展示(CPU做加速ptr和data效果差不多)
-
ptr和data的代码
void preprocess_cv_mat_data(cv::Mat src, float* tar, float* mean, float* std){
float* ptar_ch0 = tar + src.rows * src.cols * 0;
float* ptar_ch1 = tar + src.rows * src.cols * 1;
float* ptar_ch2 = tar + src.rows * src.cols * 2;
int height = src.rows;
int width = src.cols;
int channels = src.channels();
for (int i = 0; i < height; i ++) {
for (int j = 0; j < width; j ++) {
int index = i * width * channels + j * channels;
(*ptar_ch2++) = (src.data[index + 0] / 255.0f - mean[0]) / std[0];
(*ptar_ch1++) = (src.data[index + 1] / 255.0f - mean[1]) / std[1];
(*ptar_ch0++) = (src.data[index + 2] / 255.0f - mean[2]) / std[2];
}
}
}
void preprocess_cv_pointer(cv::Mat src, float* tar, float* mean, float* std){
int area = src.rows * src.cols;
int offset_ch0 = area * 0;
int offset_ch1 = area * 1;
int offset_ch2 = area * 2;
for (int i = 0; i < src.rows; i ++) {
cv::Vec3b* src_ptr = src.ptr<cv::Vec3b>(i);
for (int j = 0; j < src.cols; j ++) {
tar[offset_ch2++] = (src_ptr[j][0] / 255.0f - mean[0]) / std[0];
tar[offset_ch1++] = (src_ptr[j][1] / 255.0f - mean[1]) / std[1];
tar[offset_ch0++] = (src_ptr[j][2] / 255.0f - mean[2]) / std[2];
}
}
}
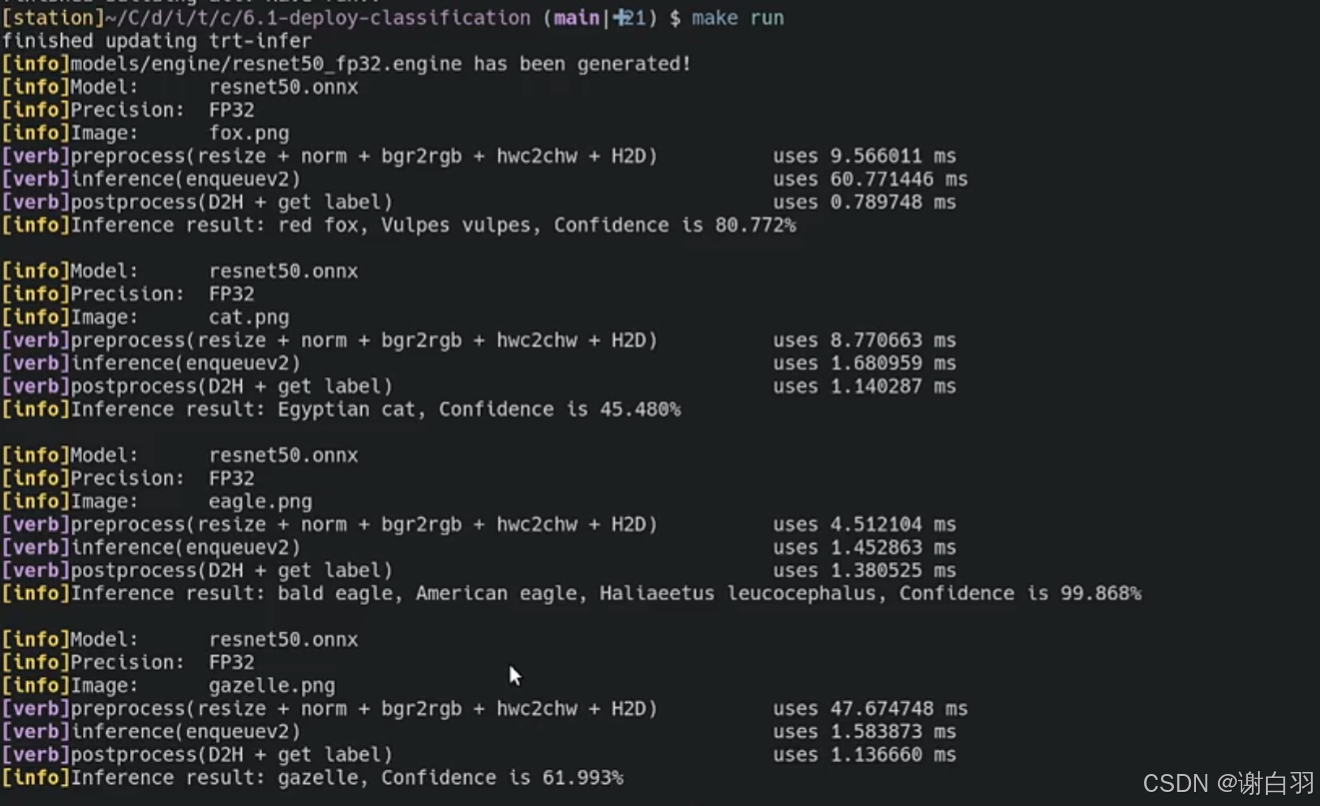
2)deploy-classification-basic(初步的分类器在部署的时候怎么做)
-
代码总体流程
①preprocess
②enqueue
③postprocess -
代码执行结果
-
模仿pytorch的推理流程,定制一些mean和std的参数
①链接:https://pytorch.org/hub/pytorch_vision_resnet/
②图片

-
推理流程
①加载engine,初始化对应logger,创建context,获取输出、输入维度,创建cuda流
②根据输入维度获取:频道、高、宽,根据输出频道获取这个向量的长度
(模型输出的类别数量。在深度学习模型中,尤其是在图像分类任务中,模型的输出通常是一个向量,其中每个元素代表一个类别的概率。如果数据集有 10 个不同的类别,那么 num_classes 就会被设置为 10)
③分配host和device的内存空间
④读取图片数据
⑤图片做一个resize
⑥CPU的host端做一个normalization+BFR2RGB+hwc2cwh
⑦把host的数据拷贝到device,开始推理
⑧后处理结束后,推理结束释放内存 -
后处理流程
①寻找最大值及其位置:使用 std::max_element 函数找到 output_host 数组中的最大值,并记录其位置 pos。这个最大值通常对应于模型预测的最可能的类别
②计算置信度:将最大值乘以 100 得到置信度 confidence,表示模型对预测结果的信心程度
③后处理总结:后处理阶段是将模型的输出转化为可理解的预测结果,并提供相关的置信度信息,同时对整个推理过程的时间进行监控和分析。 -
后处理代码
/*Postprocess -- 寻找label*/
ImageNetLabels labels;
int pos = max_element(output_host, output_host + num_classes) - output_host;
float confidence = output_host[pos] * 100;
timer.stop_cpu();
timer.duration_cpu<Timer::ms>("postprocess(D2H + get label)");
3)design-of-inference-model
(1)代码可复用性
- 相同的流程可以用C++工厂模式的设计思路去搭建模型,实现封装
①都是前处理-》DNN推理-》后处理流程
②创建引擎的时候,都是:builder->network->config->parser->serialize->save file
③做推理inference的时候,都是:load file->deserialize->engine->context->enqueue
④初始化推理的时候,要分配host memory,分配device memory
(2)代码可读性
①在main中,只需要做到:
创建一个worker-》woker读取图片-》worker做推理
②worker暴露的接口根据main函数传入参数不同,执行不同的task,例如做分类、做检测、做分割
(3)安全性
①用RAII 智能指针帮助我们管理内存的释放
②对错误调用的处理
(4)可扩展性
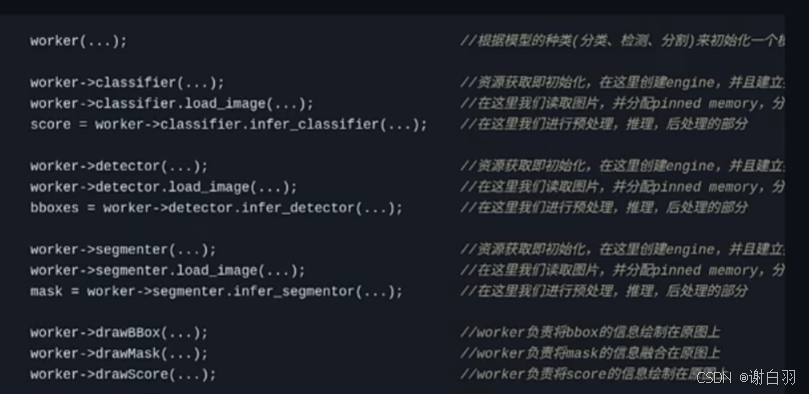
①当有新的task出现时候,尽量做到最小限度的代码修改
1)woker创建
2)woker分类
3)woker检测
4)woker分割
5)woker 绘制、融合
(5)可调试性
①在设计中比较关键的几个点设置debug信息,比如
1)yolo在NMS处理后,还剩多少bbox
2)onnx模型在TensorRT优化后,网络架构是什么样子
3)模型各个layer所支持输入的data layout是NCHW还是NHWC等
4)deploy-classification-advanced(从零手写推理框架应该考虑什么东西)
- 整体流程
①初始化参数,定好图片大小和图片的类别、模型的任务类型、模型的推理设备
②创建一个worker的实例,在创建的时候就完成初始化
③根据worker中的task类型进行推理
(1)代码可复用性
具体体现model类的函数
// 以下都是子类自己实现的内容, 通过定义一系列虚函数来实现
// setup负责分配host/device的memory, bindings, 以及创建推理所需要的上下文。
// 由于不同task的input/output的tensor不一样,所以这里的setup需要在子类实现
virtual void setup(void const* data, std::size_t size) = 0;
// 不同的task的前处理/后处理是不一样的,所以具体的实现放在子类
virtual bool preprocess_cpu() = 0;
virtual bool preprocess_gpu() = 0;
virtual bool postprocess_cpu() = 0;
virtual bool postprocess_gpu() = 0;
(2)代码可读性
外部创建logger只需要调用create_logger这个函数接口
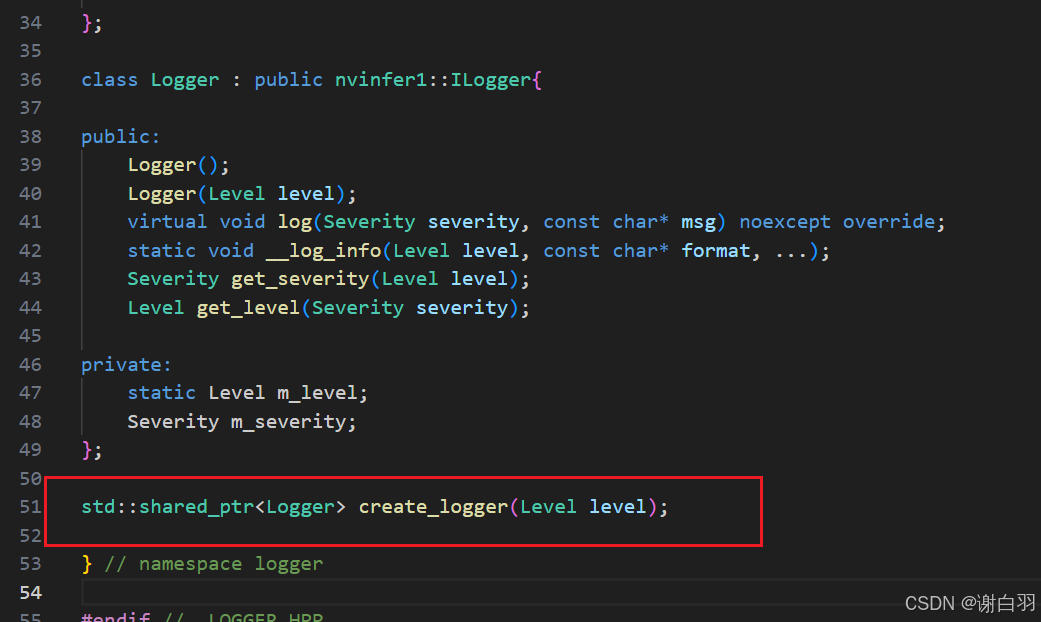
(3)安全性
model实例在创建的时候,就把内部资源都初始化好,内部变量都初始化好,用share_ptr去做内存管理
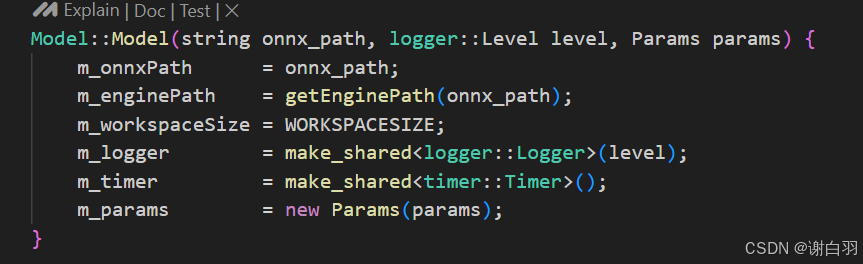
(4)可扩展性
这里只做了检测任务,所以,只初始化好检测任务的实例

namespace thread{
class Worker {
public:
Worker(std::string onnxPath, logger::Level level, model::Params params);
void inference(std::string imagePath);
public:
std::shared_ptr<logger::Logger> m_logger;
std::shared_ptr<model::Params> m_params;
std::shared_ptr<model::classifier::Classifier> m_classifier; // 因为今后考虑扩充为multi-task,所以各个task都是worker的成员变量
std::vector<float> m_scores; // 因为今后考虑会将各个multi-task间进行互动,所以worker需要保存各个task的结果
};
std::shared_ptr<Worker> create_worker(
std::string onnxPath, logger::Level level, model::Params params);
}; //namespace thread
(5)可调试性
指定打印日志级别

5)int8-calibration(怎么做int8量化和校准)
①960张图片做训练
②以64为batchsize做训练
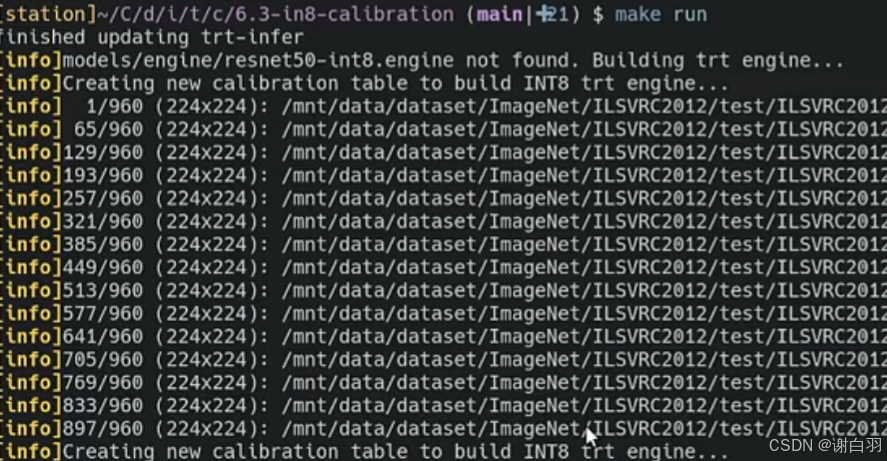
(1)如何用C++实现int8的calibrator
- 涉及到的文件
src/cpp/trt_calibrator.cpp
src/cpp/trt_model.cpp
include/trt_calibrator.cpp
-
总结
1)需要设置的config
2)需要重载的函数,实现基本的calibrator
3)在build的时候通过config指定calibrator
4)校准代码展示及四个函数代码讲解 -
1)需要设置的config
如果要模型实现FP16或INT8量化的话,我们需要在模型创建时候的config里面设置
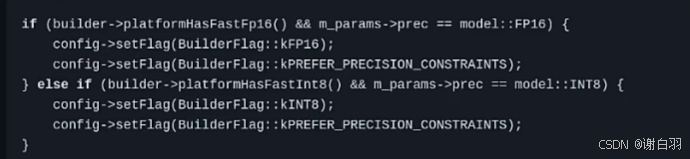
-
如果要做INT8的话,就需要自己设计一个calibrator校准器,设计和logger与plugin一样,在创建calibrator类的时候需要继承nvinfer1里的calibrator
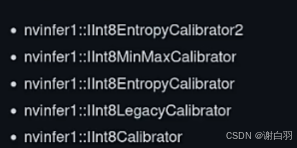
①legacyCalibrator是Percentile calibration,用的比较少
②Entropy是尽量让int8和FP32量化前后的分布尽量保持一致,2和1的区别是融合前做校准还是融合后做校准,一般默认都是继承2
③MinMax是从FP32转到INT8的时候,需要把FP32最大和最小的值都给包含进去
④Int8Calibrator是古早版本的,很早就不用了

-
为什么INT8需要校准器?
因为int8表示的dynamic range远低于FP16或FP32 -
2)需要重载的函数

各个函数的解释

-
注意点补充
①不同的batch size会有不同的校准效果
②在getBatch获取的图像必须要和真正推理时所采用的预处理保持一致,不然dynamic range会不准
③实现这个readCalibrationCache函数可以让我们避免每次做int8推理的时候都需要做一次calibration(readCalibrationCache就是读取缓存)
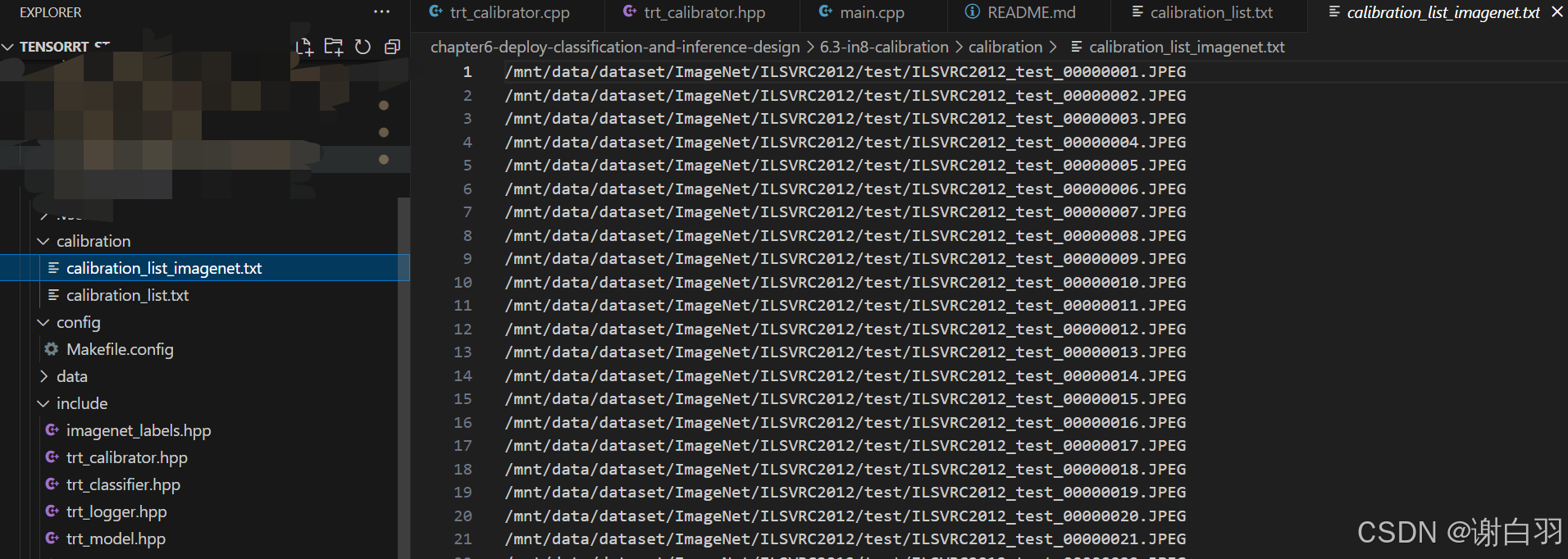
④这里面的calibration_list_imagenet.txt使用的是ImageNet2012的test数据集的一部分。这里可以根据各自的情况去更改。需要注意的是,如果calibrator改变了,或者模型架构改变了,需要删除掉calibration_table.txt来重新计算dynamic range。否则会报错 -
3)在build的时候通过config指定calibrator
shared_ptr<Int8EntropyCalibrator> calibrator(new Int8EntropyCalibrator(
64,
"calibration/calibration_list_imagenet.txt", //图片地址
"calibration/calibration_table.txt", //图片名字
3 * 224 * 224, 224, 224));
config->setInt8Calibrator(calibrator.get());
- 4)校准代码展示及四个函数代码讲解
总体流程
①头文件
②构造函数
③getBatch把拿到的数据按照batchsize做预处理
④readCalibrationCache: 读取calibration table的信息
⑤writeCalibrationCache: 将calibration cache的信息写入到calibration table中
①头文件
#ifndef __TRT_CALIBRATOR_HPP__
#define __TRT_CALIBRATOR_HPP__
#include "NvInfer.h"
#include <string>
#include <vector>
namespace model{
class Int8EntropyCalibrator: public nvinfer1::IInt8EntropyCalibrator2 {
public:
Int8EntropyCalibrator(
const int& batchSize,
const std::string& calibrationSetPath,
const std::string& calibrationTablePath,
const int& inputSize,
const int& inputH,
const int& inputW);
~Int8EntropyCalibrator(){};
//需要重载四个函数
int getBatchSize() const noexcept override {return m_batchSize;};
bool getBatch(void* bindings[], const char* names[], int nbBindings) noexcept override;
const void* readCalibrationCache(std::size_t &length) noexcept override;
void writeCalibrationCache (const void* ptr, std::size_t legth) noexcept override;
private:
const int m_batchSize;
const int m_inputH;
const int m_inputW;
const int m_inputSize;
const int m_inputCount;
const std::string m_calibrationTablePath {nullptr};
std::vector<std::string> m_imageList;
std::vector<char> m_calibrationCache;
float* m_deviceInput{nullptr};
bool m_readCache{true};
int m_imageIndex;
};
}; // namespace model
#endif __TRT_CALIBRATOR_HPP__
②构造函数
1、loadDataList读取图片数据
2、让m_imageList里面存储的数据是能让batchsize整除的
3、用random_shuffle把里面的数据重新排列
4、为数据分配内存cudaMalloc
Int8EntropyCalibrator::Int8EntropyCalibrator(
const int& batchSize,
const string& calibrationDataPath,
const string& calibrationTablePath,
const int& inputSize,
const int& inputH,
const int& inputW):
m_batchSize(batchSize),
m_inputH(inputH),
m_inputW(inputW),
m_inputSize(inputSize),
m_inputCount(batchSize * inputSize),
m_calibrationTablePath(calibrationTablePath)
{
m_imageList = loadDataList(calibrationDataPath);
m_imageList.resize(static_cast<int>(m_imageList.size() / m_batchSize) * m_batchSize);
std::random_shuffle(m_imageList.begin(), m_imageList.end(),
[](int i){ return rand() % i; });
CUDA_CHECK(cudaMalloc(&m_deviceInput, m_inputCount * sizeof(float)));
}
③getBatch把拿到的数据按照batchsize做预处理
1、对每个batchsize里面的图片进行预处理
2、把数据存在bindings[0]里面,把数据传过去校准
bool Int8EntropyCalibrator::getBatch(
void* bindings[], const char* names[], int nbBindings) noexcept
{
if (m_imageIndex + m_batchSize >= m_imageList.size() + 1)
return false;
LOG("%3d/%3d (%3dx%3d): %s",
m_imageIndex + 1, m_imageList.size(), m_inputH, m_inputW, m_imageList.at(m_imageIndex).c_str());
/*
* 对一个batch里的所有图像进行预处理
* 这里可有以及个扩展的点
* 1. 可以把这个部分做成函数,以函数指针的方式传给calibrator。因为不同的task会有不同的预处理
* 2. 可以实现一个bacthed preprocess
* 这里留给当作今后的TODO
*/
cv::Mat input_image;
float mean[] = {0.406, 0.456, 0.485};
float std[] = {0.225, 0.224, 0.229};
for (int i = 0; i < m_batchSize; i ++){
input_image = cv::imread(m_imageList.at(m_imageIndex++));
process::preprocess_resize_gpu(
input_image,
m_deviceInput + i * m_inputSize,
m_inputH, m_inputW,
mean, std, process::tactics::GPU_BILINEAR);
}
bindings[0] = m_deviceInput;
return true;
}
④readCalibrationCache:读取calibration table的信息
1、以流的形式放到ifstream
2、将calibration table的信息存储到calibtration cache,这样可以每次创建int推理引擎的时候跑一次calibration校准
calibration tabble
1)校准表是一个数据文件,包含了在INT8量化过程中收集的统计信息。这些统计信息用于确定每个张量的量化参数,例如缩放因子(scale factor)和零点(zero point)。
2)在进行INT8量化时,TensorRT会遍历校准数据集(通常是一部分代表性的训练数据或验证数据),并收集每个张量的激活值分布。这些分布信息用于计算最佳的量化参数,以最小化量化误差。
3)校准表通常以二进制文件的形式存储,可以在不同的TensorRT引擎实例之间共享,以便在部署时使用相同的量化参数。
/*
* 读取calibration table的信息来创建INT8的推理引擎,
* 将calibration table的信息存储到calibration cache,这样可以防止每次创建int推理引擎的时候都需要跑一次calibration
* 如果没有calibration table的话就会直接跳过这一步,之后调用writeCalibrationCache来创建calibration table
*/
const void* Int8EntropyCalibrator::readCalibrationCache(size_t& length) noexcept
{
void* output;
m_calibrationCache.clear();
ifstream input(m_calibrationTablePath, ios::binary);
input >> noskipws;
if (m_readCache && input.good())
copy(istream_iterator<char>(input), istream_iterator<char>(), back_inserter(m_calibrationCache));
length = m_calibrationCache.size();
if (length){
LOG("Using cached calibration table to build INT8 trt engine...");
output = &m_calibrationCache[0];
}else{
LOG("Creating new calibration table to build INT8 trt engine...");
output = nullptr;
}
return output;
}
⑤writeCalibrationCache:将calibration cache的信息写入到calibration table中
void Int8EntropyCalibrator::writeCalibrationCache(const void* cache, size_t length) noexcept
{
ofstream output(m_calibrationTablePath, ios::binary);
output.write(reinterpret_cast<const char*>(cache), length);
output.close();
}
(2)推理量化太久怎么办?(timing caches)
每一个layer都有自己之前通过auto-tuning选择优化最好的tatics,如果把这个部分数据选择方案提前存储好,那么部署的时候就不需要再通过auto-tuning再搜索选择最好的tatics
6)trt-engine-explorer(官方组件看模型在tensorRT量化后有什么不同)
- trt-engine-explorer介绍
trt-engine-explorer是NVIDIA官方提供的分析TensorRT优化后的推理引擎架构的工具包,统计出模型架构、输入输出、onnx那些层删了或添加了(内部其实是调用trtexec获得的信息)
(1)安装环境及遇到的问题解决方法
-
目录路径
-
安装步骤

-
若是安装后执行不了
①可能是Flask版本的问题:
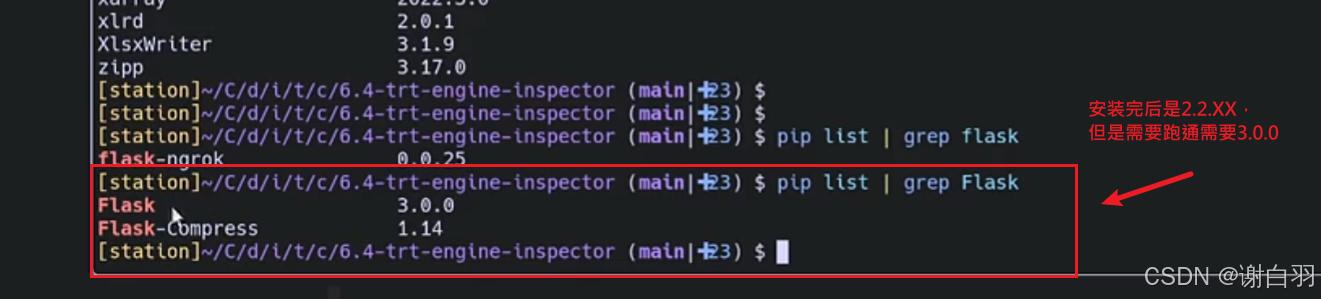
怎么操作升级
pip install --upgrade Flask
(2)怎么跑通这个工具?
- 主要用到的脚本
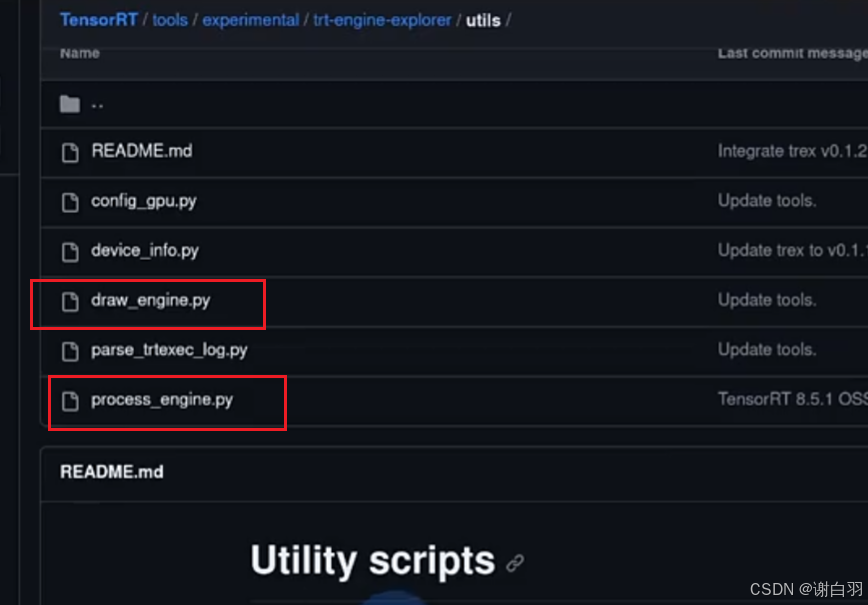
①process_engine.py:根据onnx构建TensorRT引擎,然后用json格式打印各个layer的信息
②跑通指令;

③生成的json文件
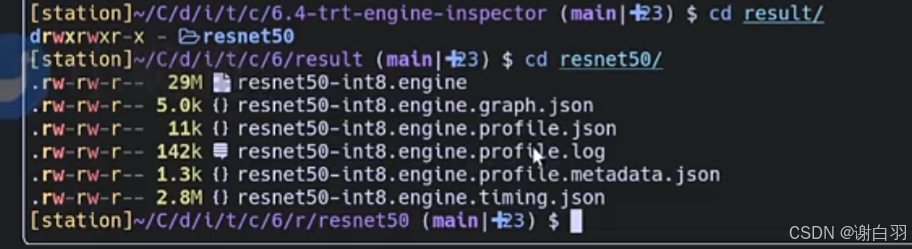
④如果需要打印完整信息,在模型构建的时候选择verbosity是kDETAILED

⑤产出的文件:
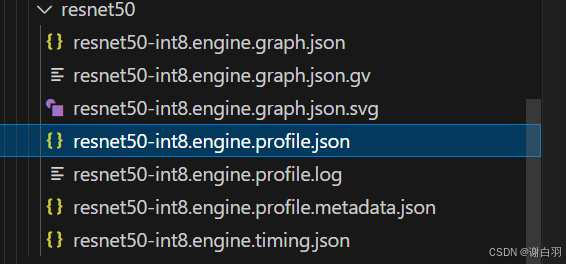
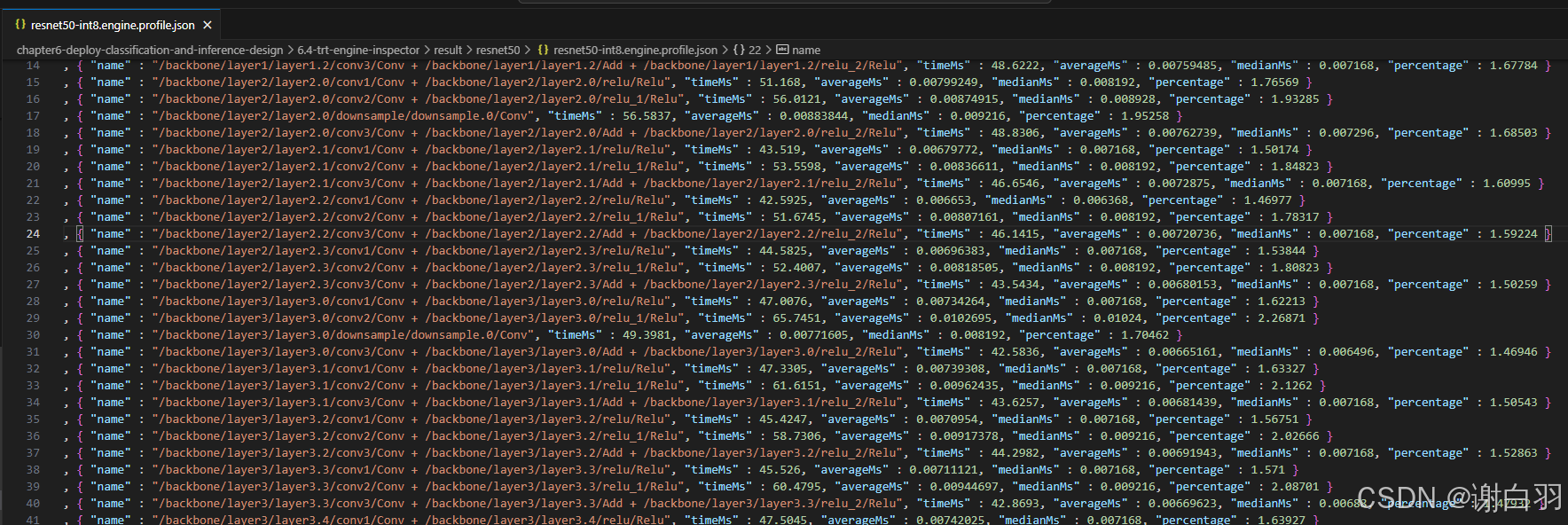
1)profile.json:表示每个layer的推理时间
2)metadata:GPU的硬件信息(不需要看)
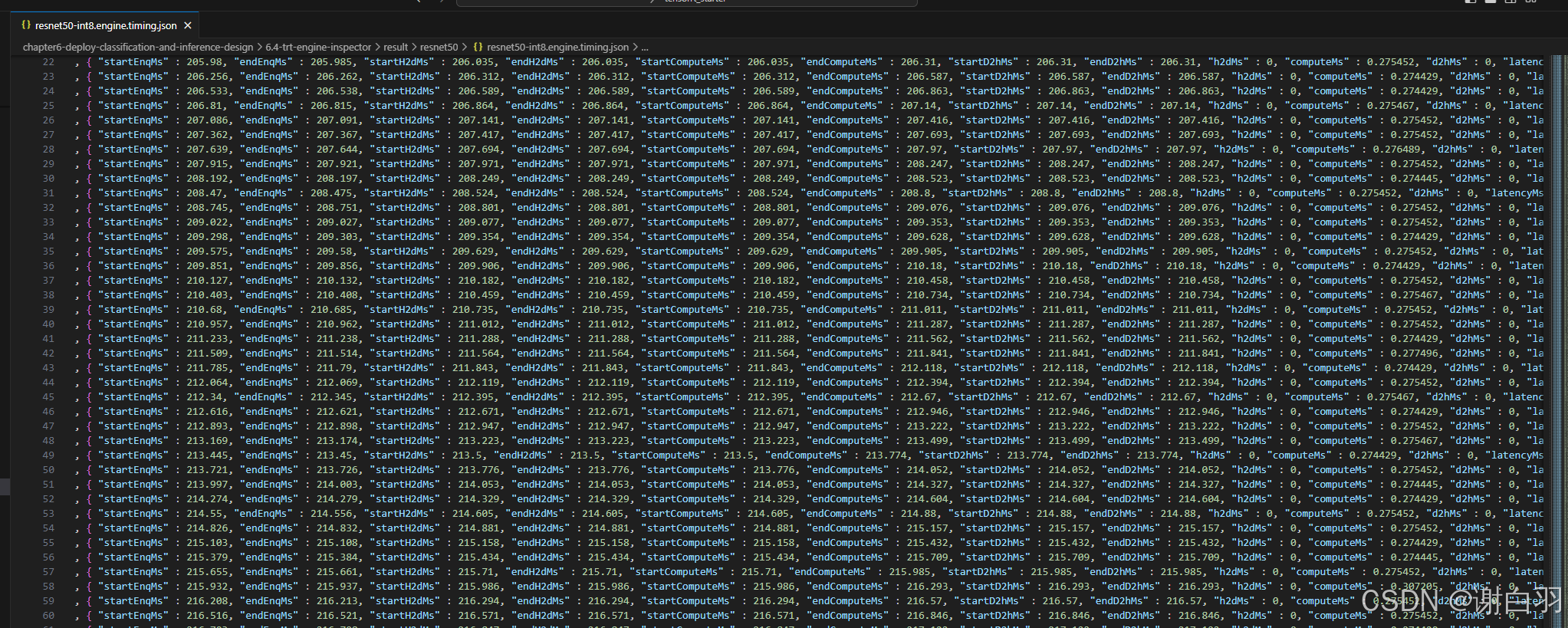
3)timing:推理时间
1)profile.json:表示每个layer的推理时间
2)metadata:GPU的硬件信息(不需要看)

3)timing:推理时间
⑥使用draw_engine.py文件

用open打开svg图片

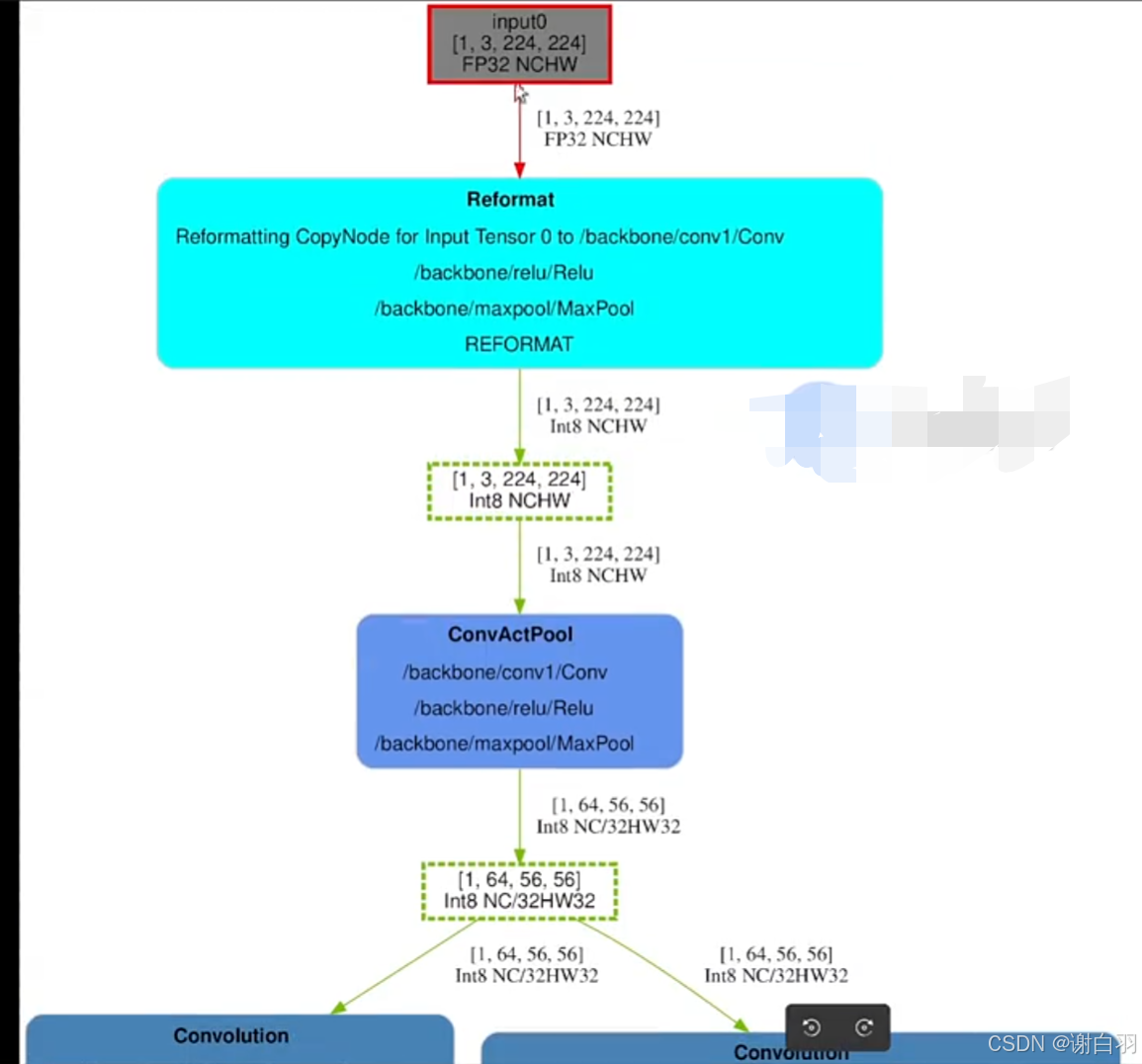
具体展开
netron展示的onnx
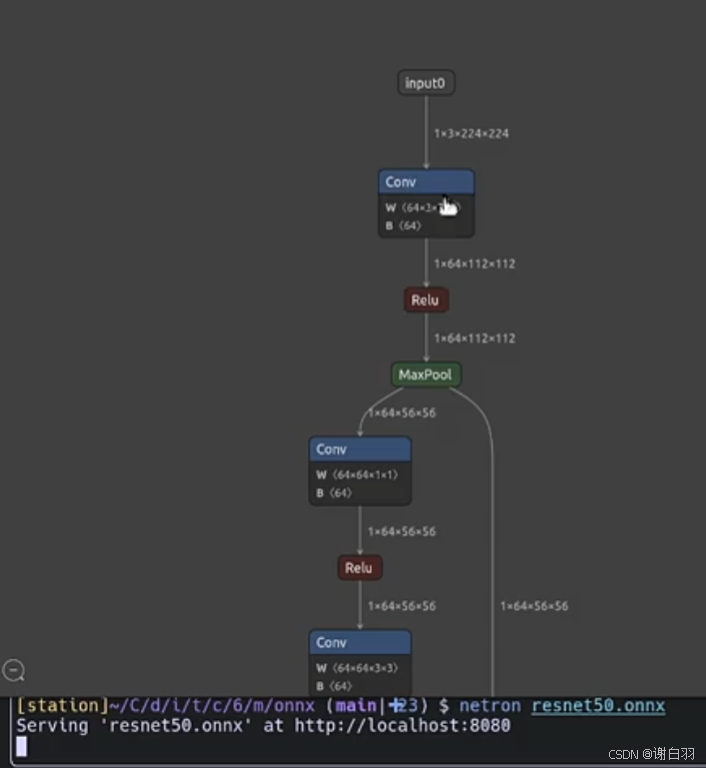
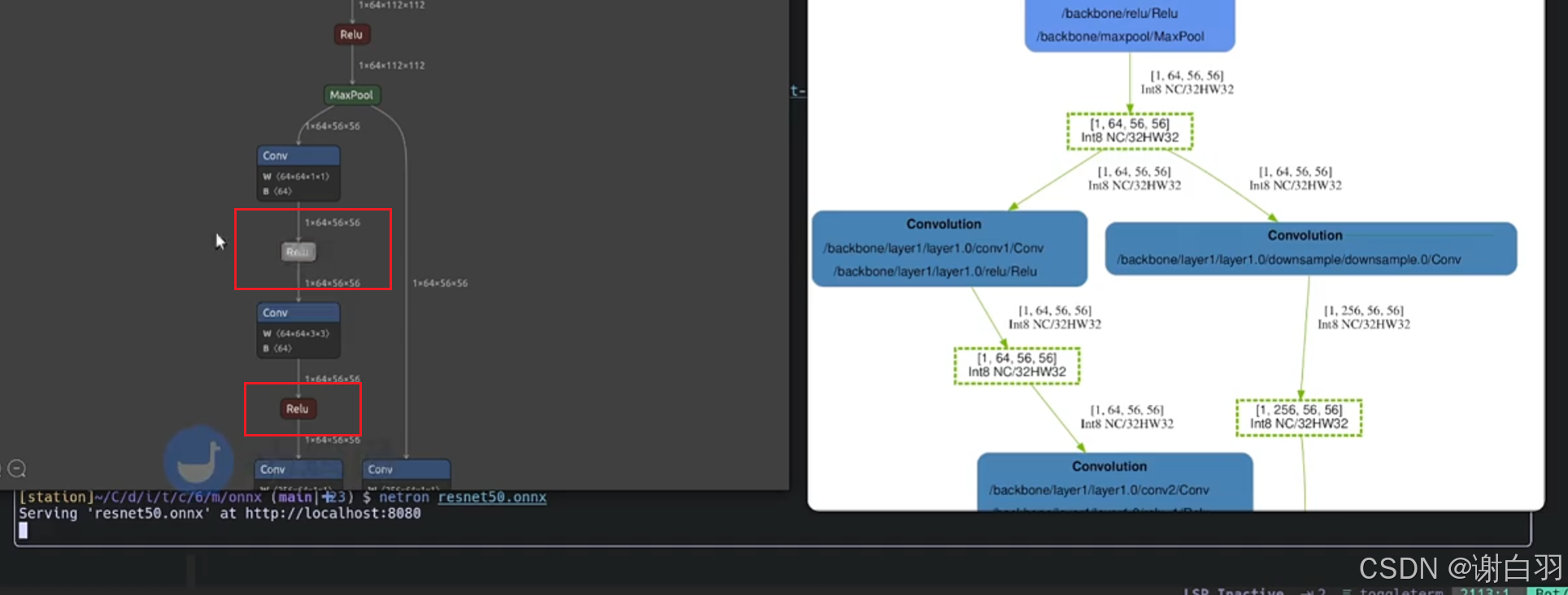
1)可以看到有个绿色虚线框,虚线表示已经裁剪掉了
2)蓝色框reformat表示是额外添加的,reformat表示更改了数据格式
(例如FP32数据更改成int8类型就算更改)
3)往下走可以看到Relu激活函数都没了
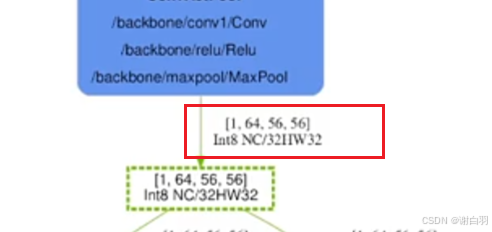
4)tensorRT内部数据排版(data format)
(3)process_engine.py一些参数
①构建引擎
指令(由于没有calibration,精度是很差的)

二、模型部署-YOLOv8检测器
1)load-save-tensor(tensor的保存:将tensor能在C++和python有来有去通过numpy格式转换)
-
引入一个库:cnpy
①库作用:它可以用来将python中的numpy数据打包成npy或者npz格式,之后从c++中读取;
或者将c++中的array或者vector打包成npy或者npz格式,让python读取。
②库的应用场景:将C++做的一些后处理和pytorch做的后处理的结果进行比较。比如说,
如果原本的yolov8模型中pytorch的bbox的位置信息和confidence和我们自己C++手写的
实现结果有很大的不同的话,我们可能会考虑是在哪一步的处理有出入
③库链接:https://github.com/rogersce/cnpy
④类似的库:同时知名度也比较高的有Aten,或者Autograd,但是cnpy由于只提供tensor的save/load,也是我们在debug中仅仅需要的功能,所以相比下来会比Aten和torchlib要轻量许多,方便使用 -
python保存np数据(创建字典,然后存储key为data_python的value数据)
import os
import numpy as np
from logger import init_logger
logger = init_logger()
def createData(data_path, data_label, data_shape):
dataDict = {}
dataDict[data_label] = np.random.rand(*data_shape).astype(np.float32)
np.savez(data_path, **dataDict)
logger.info("Succeeded saving data as .npz file!")
logger.info("Tensor shape:{}".format(dataDict[data_label].shape))
logger.info("Tensor values:")
print(dataDict[data_label])
return
if __name__ == "__main__":
np.set_printoptions(formatter={'float': '{: .8f}'.format})
current_path = os.path.dirname(__file__)
data_path = current_path + "/../../data/data_python.npz"
data_label = "data_python"
data_shape = (2, 3, 4, 4)
#创建数据
createData(data_path, data_label, data_shape)
- python读取C++保存的np数据
def loadData(data_path, data_label):
dataDict = np.load(data_path)
logger.info("Succeeded loaded data as .npz file!")
logger.info("Tensor shape:{}".format(dataDict[data_label].shape))
logger.info("Tensor values:")
print(dataDict[data_label])
return
if __name__ == "__main__":
np.set_printoptions(formatter={'float': '{: .8f}'.format})
current_path = os.path.dirname(__file__)
data_path = current_path + "/../../data/data_python.npz"
data_label = "data_python"
data_shape = (2, 3, 4, 4)
data_path = current_path + "/../../data/data_cpp.npz"
data_label = "data_cpp"
loadData(data_path, data_label)
- c++读取python保存的数据
/*
从c++读取一个python下保存的npz file
*/
cnpy::npz_t npz_data = cnpy::npz_load("data/data_python.npz");
cnpy::NpyArray arr = npz_data["data_python"];
for (int i = 0; i < arr.shape.size(); i ++){
LOG("arr.shape[%d]: %d", i, arr.shape[i]);
}
LOG("Succeeded loading data from .npy/.npz!");
LOG("Tensor values:");
printTensorNPY(arr);
- C++保存np数据
void initTensor(float* data, int size, int min, int max, int seed) {
srand(seed);
for (int i = 0; i < size; i ++) {
data[i] = float(rand()) * float(max - min) / RAND_MAX;
}
}
/*
在c++下保存一个python可以识别的npy/npz file
*/
const int b = 3;
const int c = 2;
const int h = 4;
const int w = 4;
int size = b * c * h * w;
float* data = (float*)malloc(size * sizeof(float));
initTensor(data, size, 0, 1, 0);
cnpy::npz_save("data/data_cpp.npz", "data_cpp", &data[0], {b, c, h, w}, "w");
cnpy::npy_save("data/data_cpp.npy", &data[0], {b, c, h, w}, "w");
LOG("Succeeded saving data as .npy/.npz!");
LOG("Tensor values:");
printTensorCXX(data, b, c, h, w);
- 编译和安装
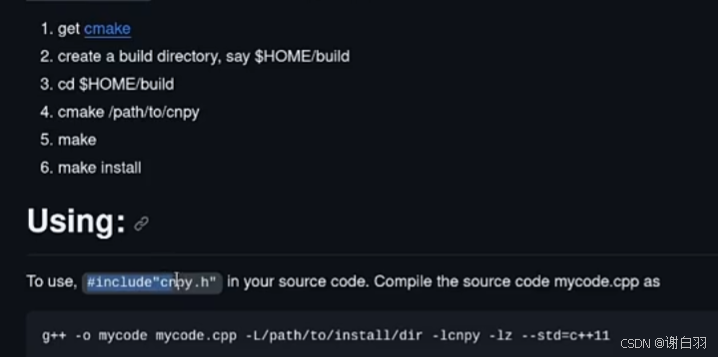
2)affine-transformation(仿射变换)
-
为什么需要学习仿射变换?
①在做classification这种,只需要把图片resize成24x24就够了;
②在做detection或segmentation的时候需要把图片resize成模型能识别的大小,才能去做推理,得到mask,再把mask还原到原来的尺寸,
这就需要做一个正向和反向的resize,就需要用到仿射变换 -
双线性插值(之前的2.10中有讲过)
①scale
②shift

-
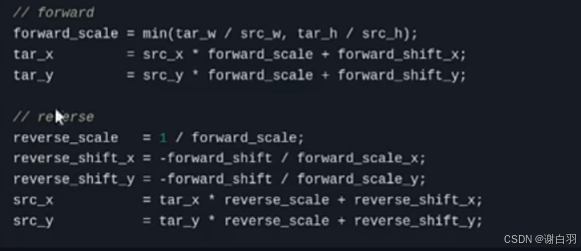
仿射变换
①forward:src->tar坐标
②reverse:tar坐标->src坐标
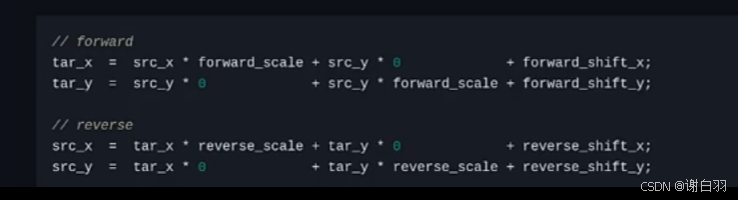
规范化
// 存储forward时需要的scale和shift
void calc_forward_matrix(TransInfo trans){
forward[0] = forward_scale;
forward[1] = 0;
forward[2] = - forward_scale * trans.src_w * 0.5 + trans.tar_w * 0.5;
forward[3] = 0;
forward[4] = forward_scale;
forward[5] = - forward_scale * trans.src_h * 0.5 + trans.tar_h * 0.5;
};
// 存储reverse时需要的scale和shift
void calc_reverse_matrix(TransInfo trans){
reverse[0] = reverse_scale;
reverse[1] = 0;
reverse[2] = - reverse_scale * trans.tar_w * 0.5 + trans.src_w * 0.5;
reverse[3] = 0;
reverse[4] = reverse_scale;
reverse[5] = - reverse_scale * trans.tar_h * 0.5 + trans.src_h * 0.5;
};
// 仿射变换的计算公式
__device__ void affine_transformation(
float trans_matrix[6],
int src_x, int src_y,
float* tar_x, float* tar_y)
{
*tar_x = trans_matrix[0] * src_x + trans_matrix[1] * src_y + trans_matrix[2];
*tar_y = trans_matrix[3] * src_x + trans_matrix[4] * src_y + trans_matrix[5];
}
- 仿射和双线性插值对比
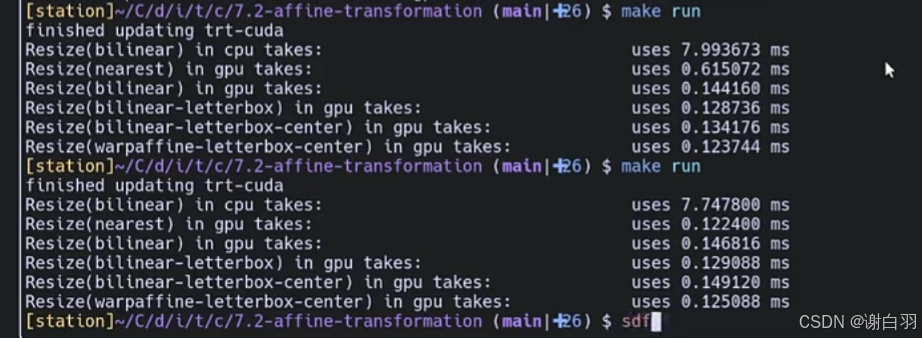
- 查看图片

3)deploy-yolo-basic(yolo部署detection)
- 总结
6.4小结的扩展 - 重点
只需要关注preprocess和postprocess。preprocess可以使用仿射变换warp affine,postprocess需要自己实现一个decode和nms的算法
(1)yolo源码安装
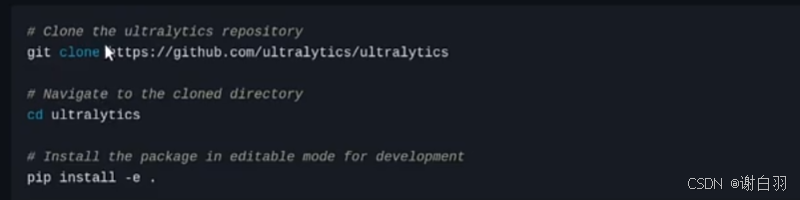
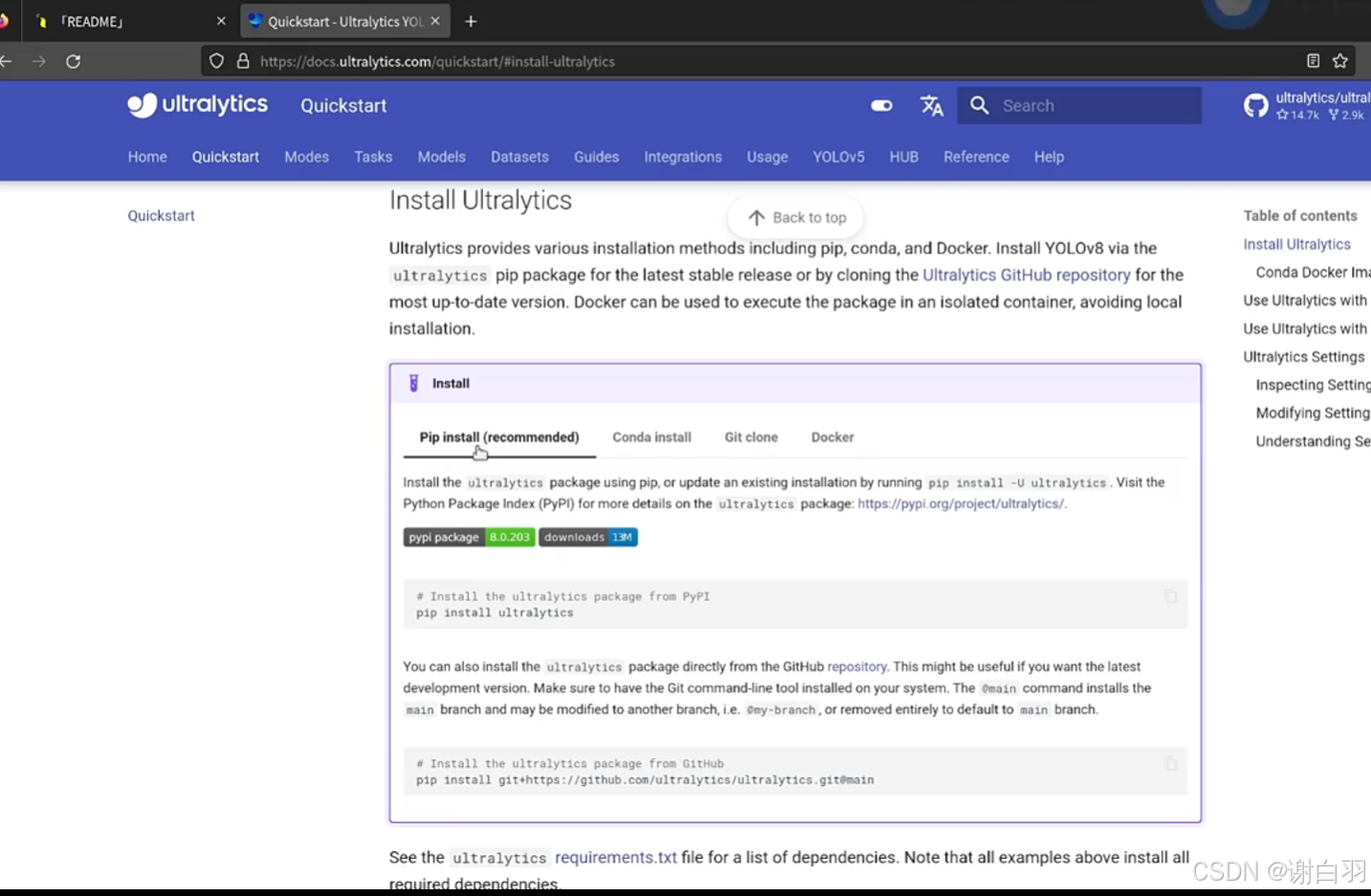
由于官方是推荐pipinstall去安装,但是后面我们可能是对网路进行修改,所以安装到系统环境变量不合适
- 启动顺序
①进入conda的yolo8环境
conda activate yolo8
②打印安装的ultra版本
pip list |grep ultra
③导出onnx
- 导出yolo的onnx模型代码
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained model
# Export the model
model.export(format='onnx')
(2)理解ultralytics的后处理实现
- 步骤
①修改detect的head部分
②关于动态batch(这里的batchsize是1)
③把bbox从输出tensor拿出来,并进行decode,把获取的bbox放入到m_bboxes中(后处理)
④把decode得到的m_bboxes根据nms threshold进行NMS处理(后处理)
⑤把最终得到的bbox绘制到原图中(后处理)
①修改detect的head部分
原因:但是由于yolo目标检测模型onnx的输出格式是[n, feature, bbox],不方便我们在C++做处理。我们希望对每一个bbox做处理,
所以希望每一个bbox内部的数据是内存上连续的,我们可以更改一下detect的head部分
# ultralytics/ultralytics/nn/modules/head.py
class Detect(nn.Module):
# ...
def forward(self, x):
# ...
y = torch.cat((dbox, cls.sigmoid()), 1)
y = y.transpose(1, 2)
return y if self.export else (y, x)
self.export的作用
训练阶段:需保留中间特征(如 x)用于反向传播和损失计算6。
部署阶段:只需最终检测结果(y),减少冗余数据传递
②关于动态batch(这里的batchsize是1)
备注:如果需要改成动态batchsize的话,如下图所示,需要改成-1;如果要导出支持动态batch的onnx,需要改动的地方比较多,日后有机会再说
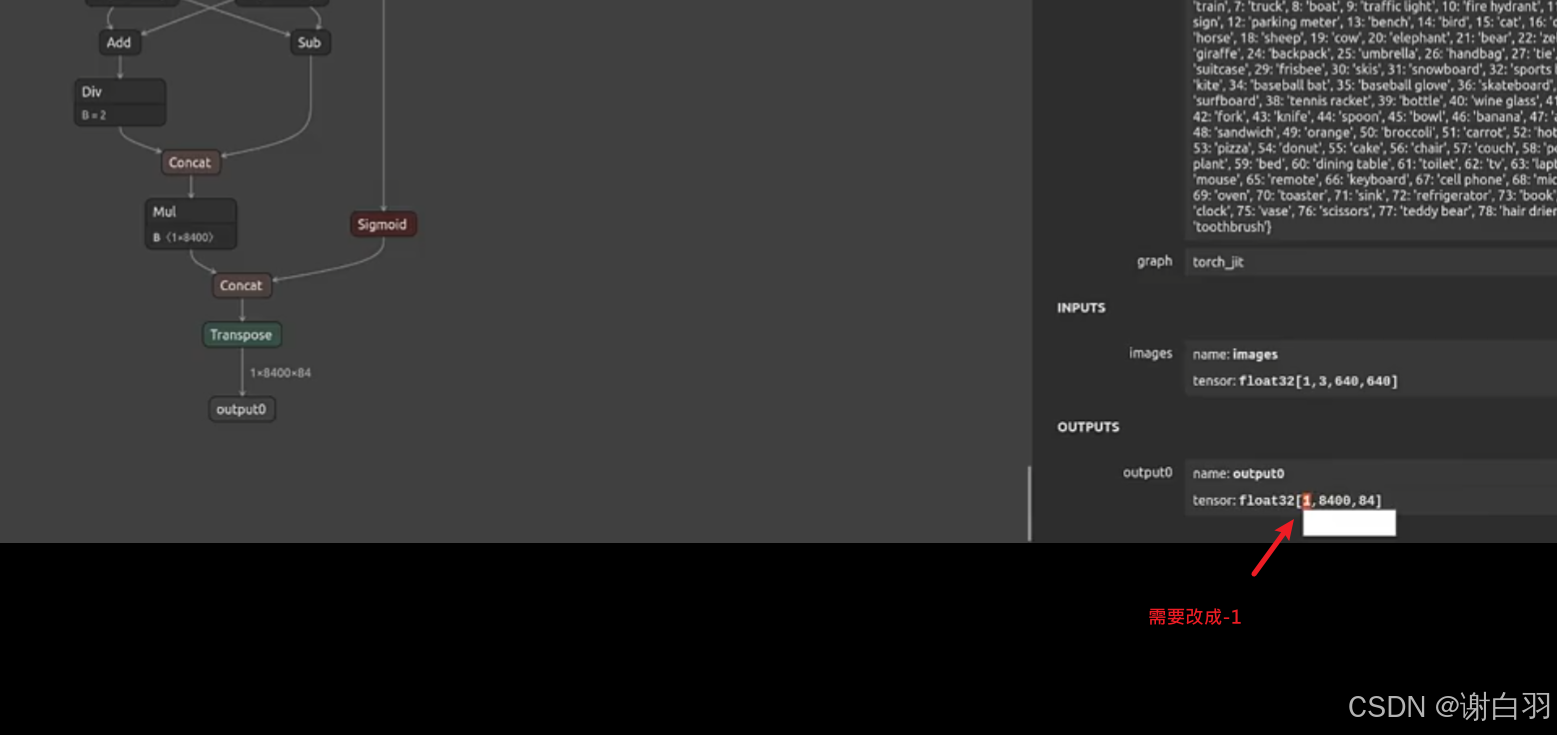
③把bbox从输出tensor拿出来,并进行decode,把获取的bbox放入到m_bboxes中(后处理)
我们需要做的就是将[batch, bboxes, ch]转换为vector
- 从每一个bbox中对应的ch中获取cx, cy, width, height
- 对每一个bbox中对应的ch中,找到最大的class label, 可以使用std::max_element
- 将cx, cy, width, height转换为x0, y0, x1, y1
- 因为图像是经过resize了的,所以需要根据resize的scale和shift进行坐标的转换(这里面可以根据preprocess中的到的affine matrix来进行逆变换)
- 将转换好的x0, y0, x1, y1,以及confidence和classness给存入到box中,并push到m_bboxes中,准备接下来的NMS处理
④把decode得到的m_bboxes根据nms threshold进行NMS处理(后处理)
- 做一个IoU计算的lambda函数
- 将m_bboxes中的所有数据,按照confidence从高到低进行排序
- 最终希望是对于每一个class,我们都只有一个bbox,所以对同一个class的所有bboxes进行IoU比较,
选取confidence最大。并与其他的同类bboxes的IoU的重叠率最大的同时IoU > IoU threshold
⑤把最终得到的bbox绘制到原图中(后处理)
- 通过label获取name
- 通过label获取color
- cv::rectangle
- cv::putText
4)quantization-analysis(针对量化掉精度严重,按照什么思路去排查错误)
(1)掉点严重思考的点
- 针对int8掉点严重的问题,有思考的点:
- 1)是否在input/output附近做了int8量化;intput是敏感层,输入的数据比较重要;output跟后处理的结果是绑定的,尽量别做量化
(当分类框精准但分类的时候掉点严重的时候,那就跟输入输出无关;当对cx、cy输入输出做量化,框的位置也会有错误)
- 2)如果是multi-task的话,是否所有的task都掉点严重
- 3)calibration的数据集是不是选的不是很好:是不是数据集太少了(2000个其实够的,考虑是不是太多了\或是数据集太偏了)
- 4)calibration batch size是不是选择的不是很好:改成1、2、16是不是会好一点
- 5)calibrator是不是没有选择好:校准算法是否能选更好的
- 6)某些计算是否不应该做量化:某些计算操作,做量化之后变化严重,是否不该做量化
- 7)使用polygraphy分析
- 总结
结合模型架构,顺理成章的猜到yolov8掉点严重的原因是因为IInt8EntropyCalibrator2
(2)思路引导
-
思路顺序
①看是否在input/output附近做了int8量化,用什么精度做的量化和推理:
②校准数据集的因素
③calibration的batchsize是不是没选好
④calibrator是不是没选好 -
思路引导
①看是否在input/output附近做了int8量化,用什么精度做的量化和推理:
(用trtexec的process_engine.py脚本去跑,看json结果)
python process_engine.py 模型位置 输出json位置 --profile-engine

用draw_engine.py画一下onnx图
python draw_engine.py xxx路径下的.json文件

注意:进入conda环境启动,因为没有模块graphviz
conda activate trt-trex

打开svg图
open xxx.json.svg

注意:如果svg打开报错,那么由如下方法去解决
(1)打开jupyter
jupyter-notebook --ip=0.0.0.0 --no-browser
(2)双击打开svg
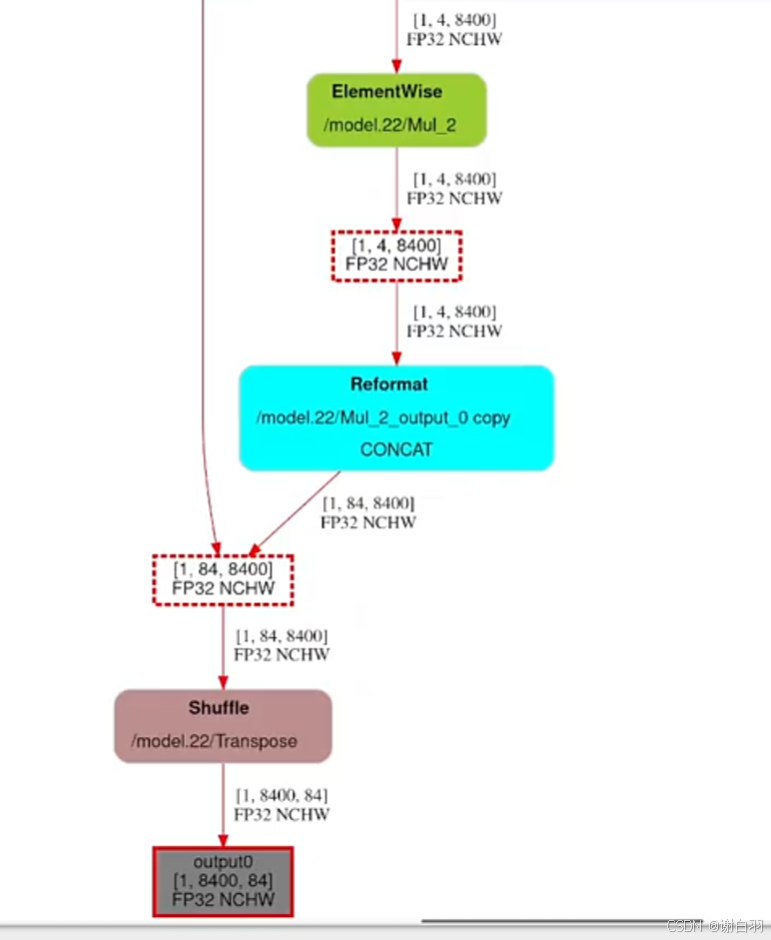
输出:可以看到靠近输出的地方精度都是FP32
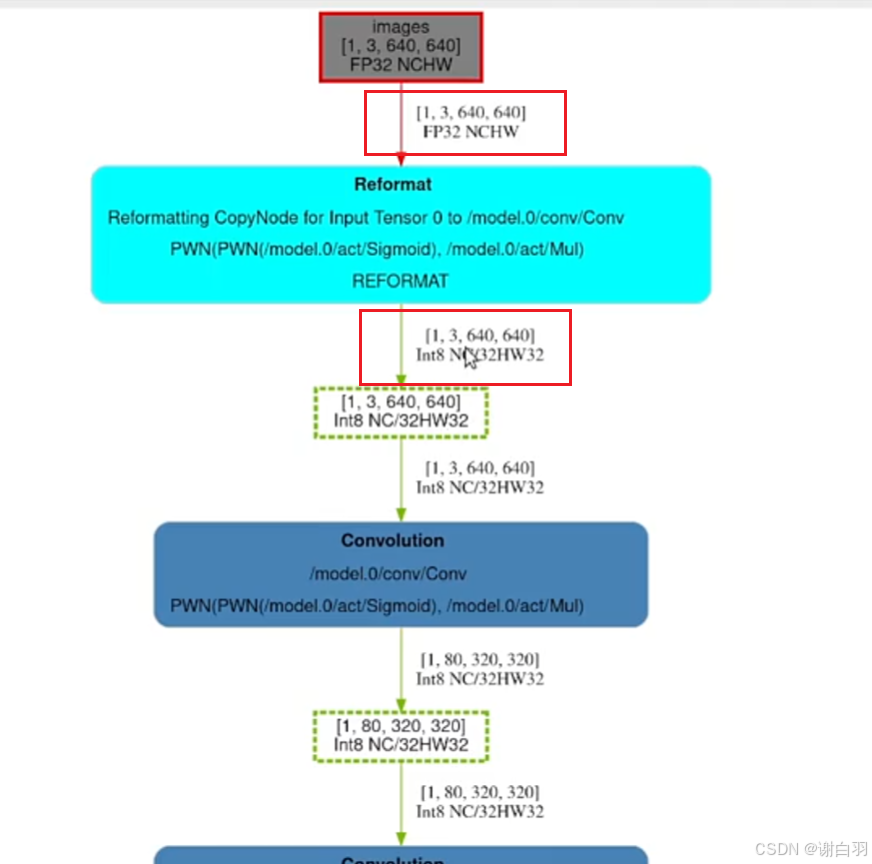
输入:去做的话,第一层尽量要求是FP32
②校准数据集的因素
这里项目用的是coco的校准数据集(可以调整数量100、500、1000时分别会怎么样,或是自己的数据集会怎么样)
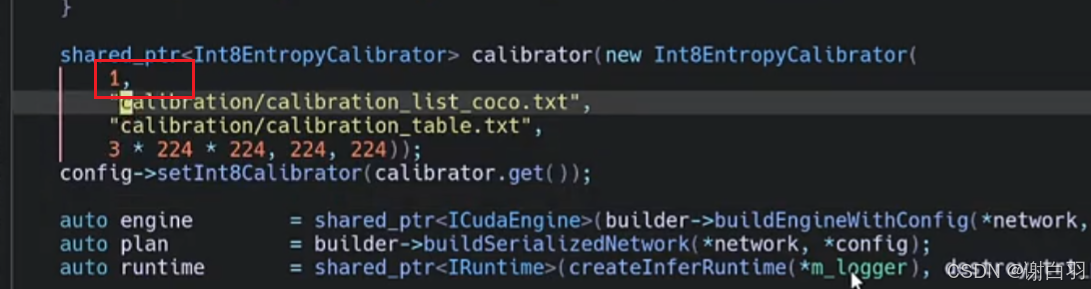
③calibration的batchsize是不是没选好
修改batchsize大小,都试试会不会影响精度
④calibrator是不是没选好
尝试不同的calibrator,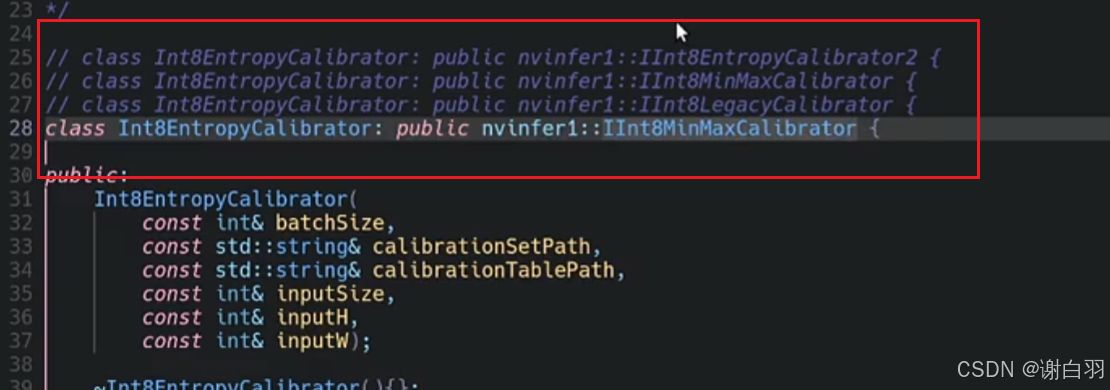
记得删除calibration_table和对应engine(这里是动态范围)
打印后处理之前的tensor bbox的confidence
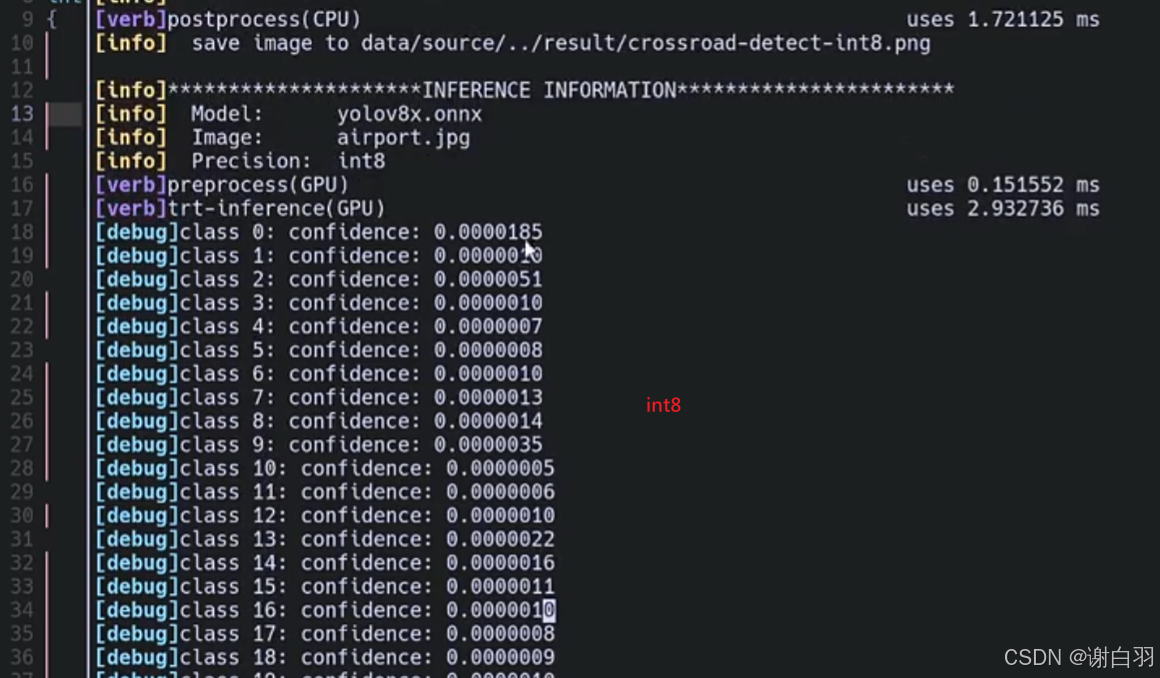
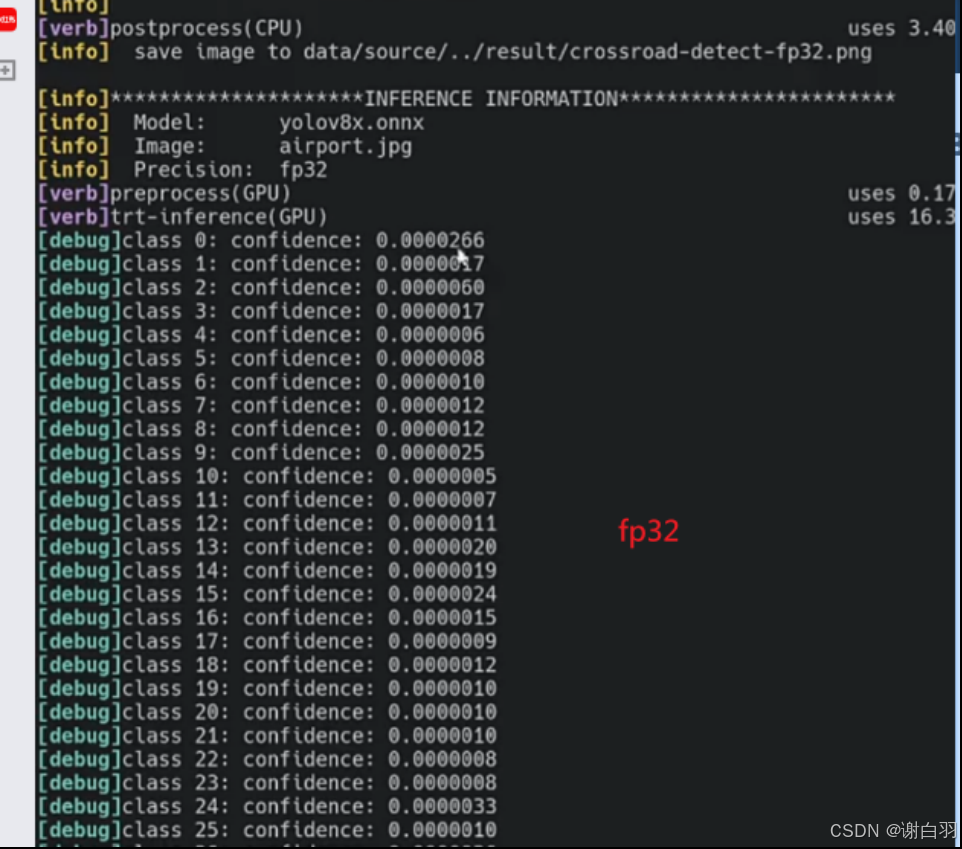
可以看到比较大的值266被截取成185,保留不下来,权重的最大值信息被删除,就可以试试把EntropyCalibrator2改成Int8MinMaxCalibrator,可以去保留权重的最大值和最小值信息
换成新的calibrator去看量化结果
(pwn代表element-wise的计算,那么多concat和slice操作跟计算本身没有关系,主要是占用内存比较多,保存临时数据比较多,对推理性能不是那么好)
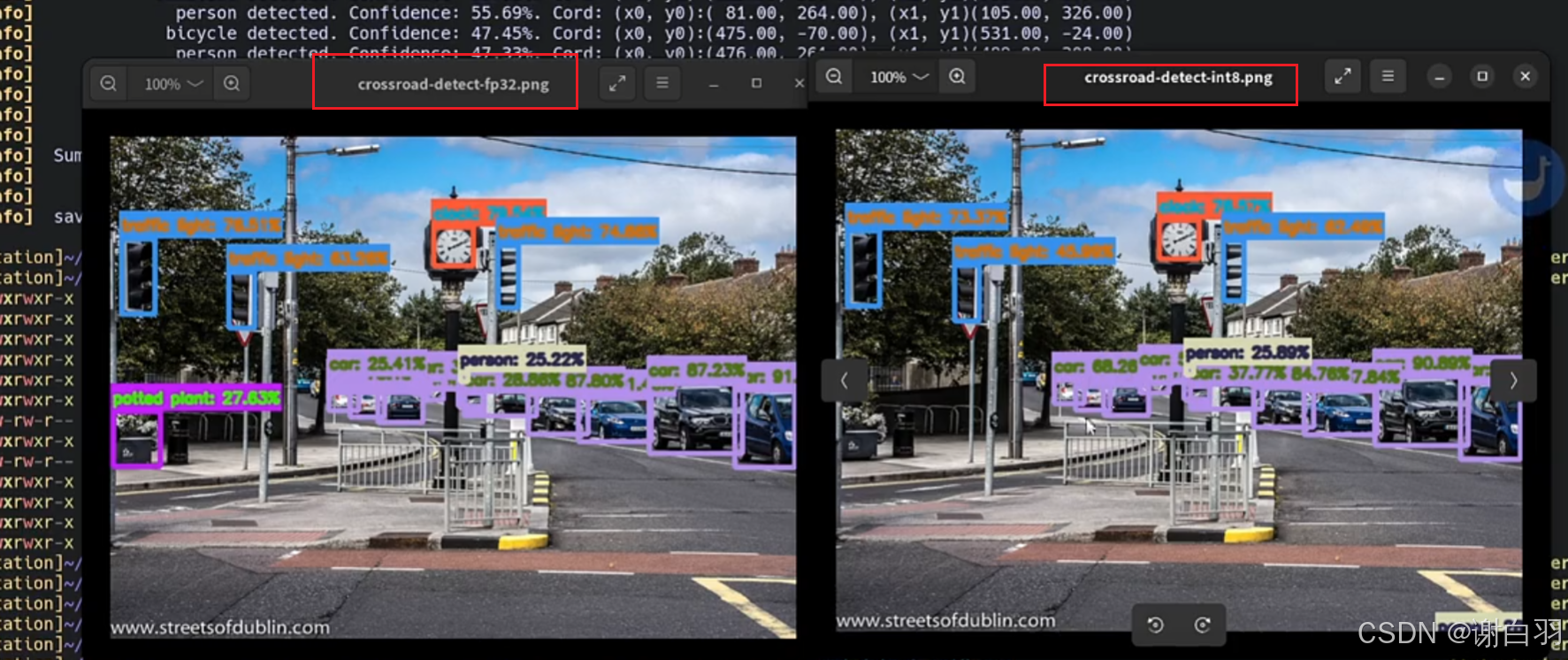
检测结果展示:可以看到精度还原还是不错的,

(3)优化点
- 可以优化的地方
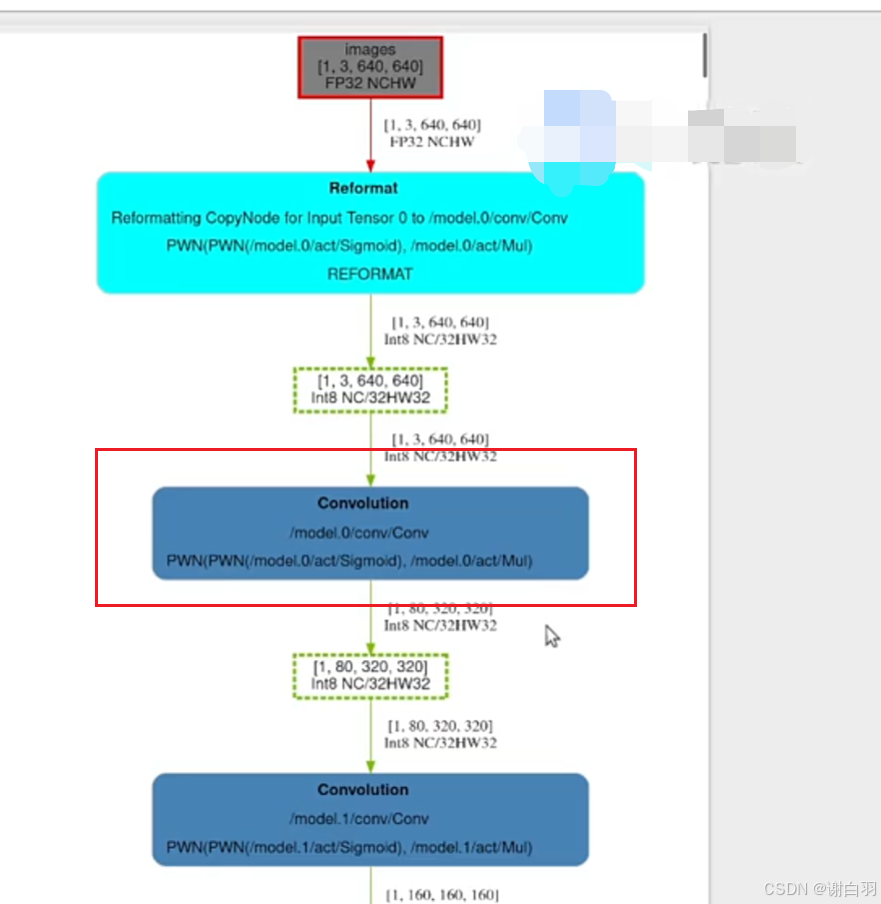
①把输入的地方,起码第一层的conv+mul+sigmoid改成精度为FP32
5)B站开源课yolo用tensorRT部署(白老师)
- yolo算法基本思想
①S x S grid on input:切分成小模块

②bounding boxes划分网格 + confidence置信度得分

置信度得分

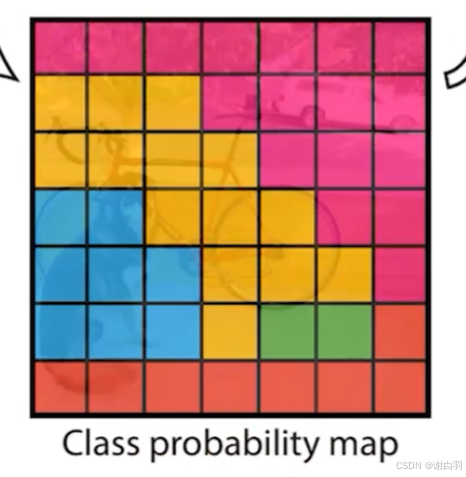
③class probability map:类别概率图
④最后检测出物体
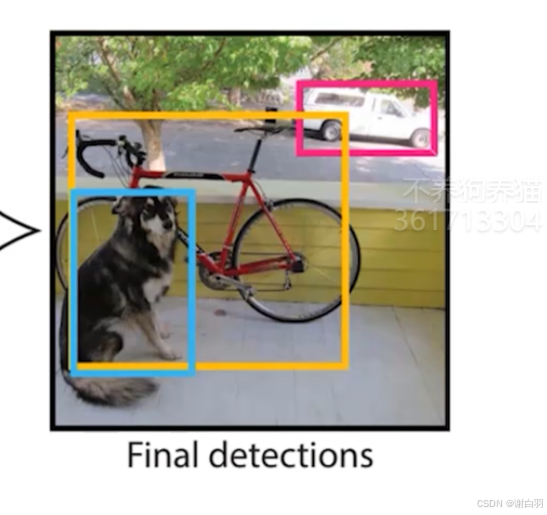
-
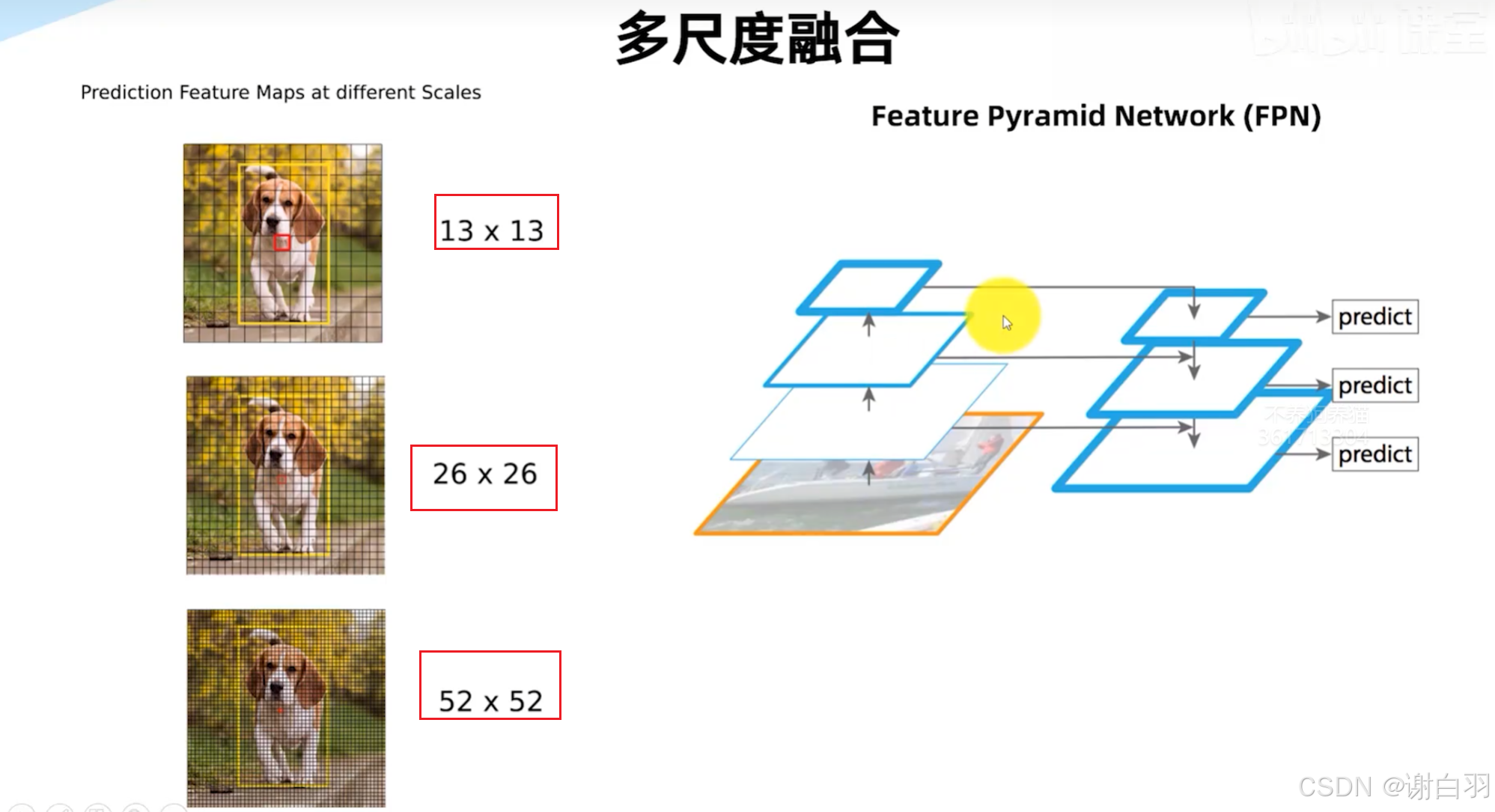
多尺度融合(不同密度划分预测来融合)
-
NMS(非极大抑制。Non-Maximum Suppression)
1)出现原因:可以多个格子检测到同个物体,有很多冗余的
2)做法:比较多个预测框,相互比较之间的IOU,做NMS -
损失函数包括
①分类损失
②定位损失
③置信度损失

-
yolo锚框机制(yolo基本思想)

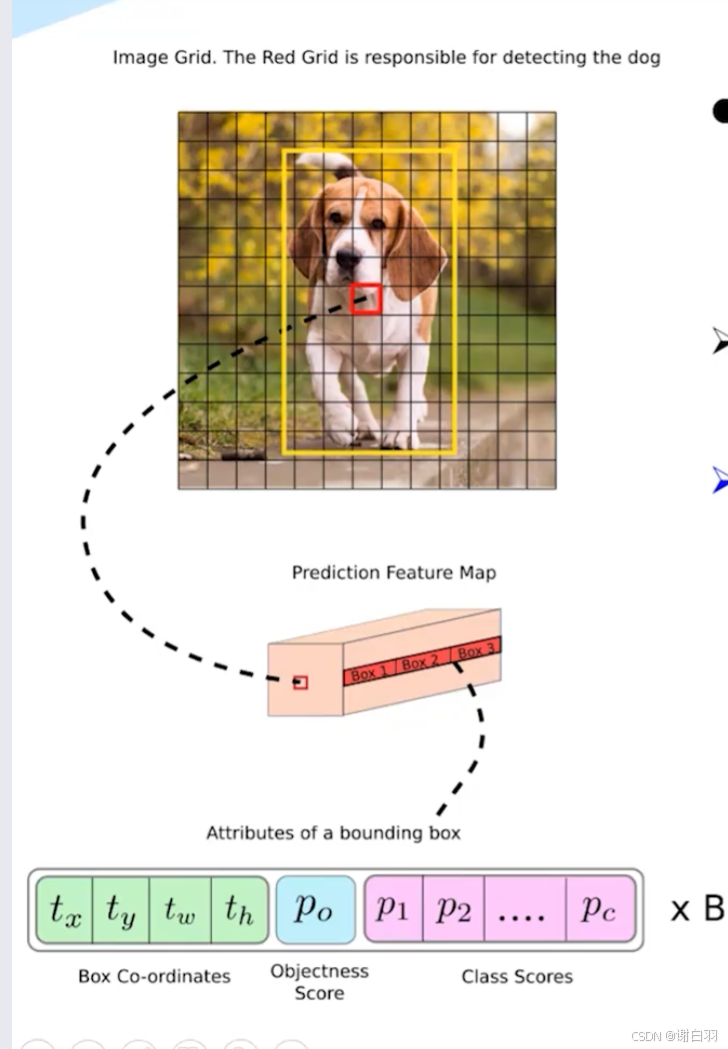
- 置信度得分

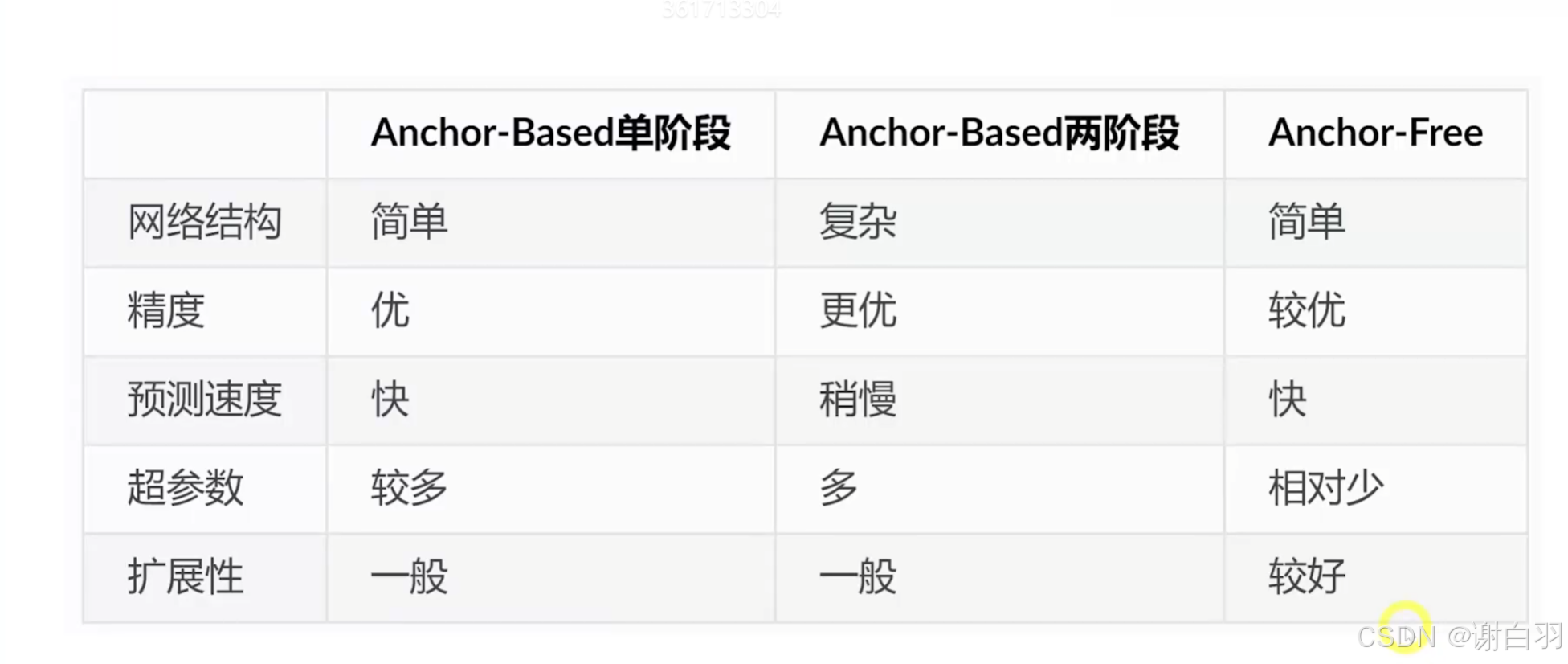
(1)PyTorch->wts->TensorRT(用权重和TensorRT原生API搭建网络)
(2)PyTorch->ONNX->TensorRT(用Parser搭建网络)
三、部署BEVFusion模型
1)Overview-and-setting-environment (分析CUDA-Fusion的优化策略与环境搭建和测试)
- 学习目标
①CUDA-BEVFusion介绍
②搭建部署推理环境
③跑通程序
(1)BEVFusion介绍
-
分类

-
两种BEV的算子
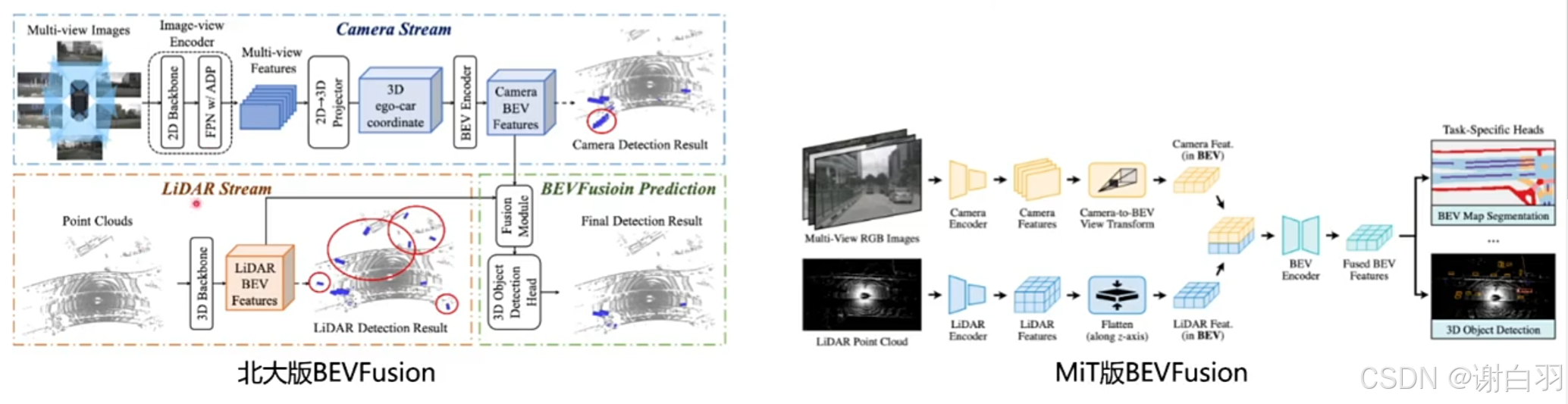
(2)MIT版本的BEVFusion算子介绍
-
这里具体讲的是MIT的BEVFusion
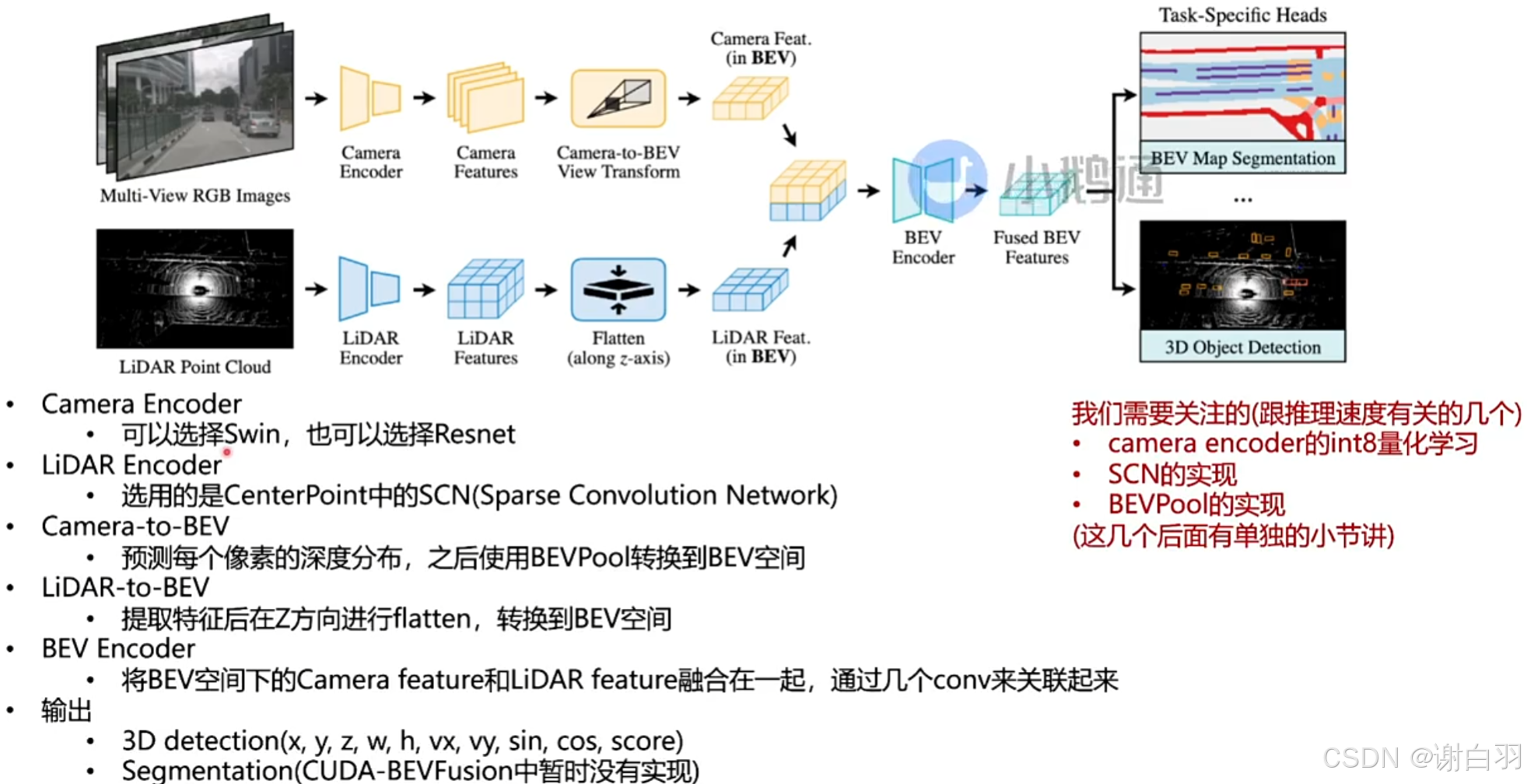
-
备注:
①选swim的好处:可以更加关注六张图片不同位置不同信息attention
(3)CUDA-BEVFusion的优化方向(默认FP16)

(4)CUDA-BEVFusion 环境搭建

(5)下载数据集和模型
BEVFusion的github主页有

多出两个目录:model和example-data
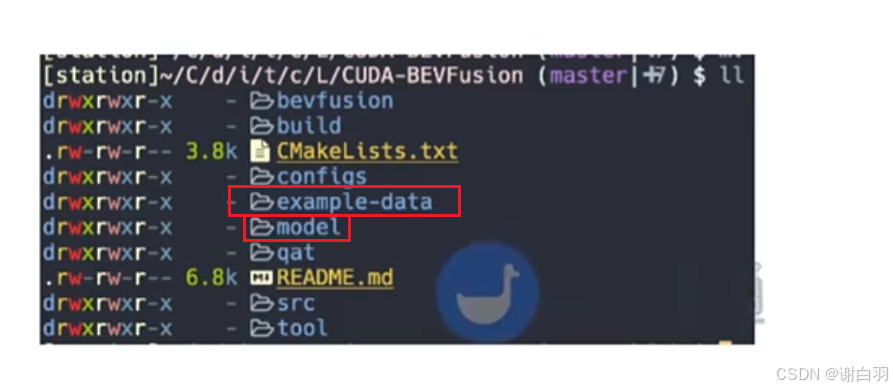
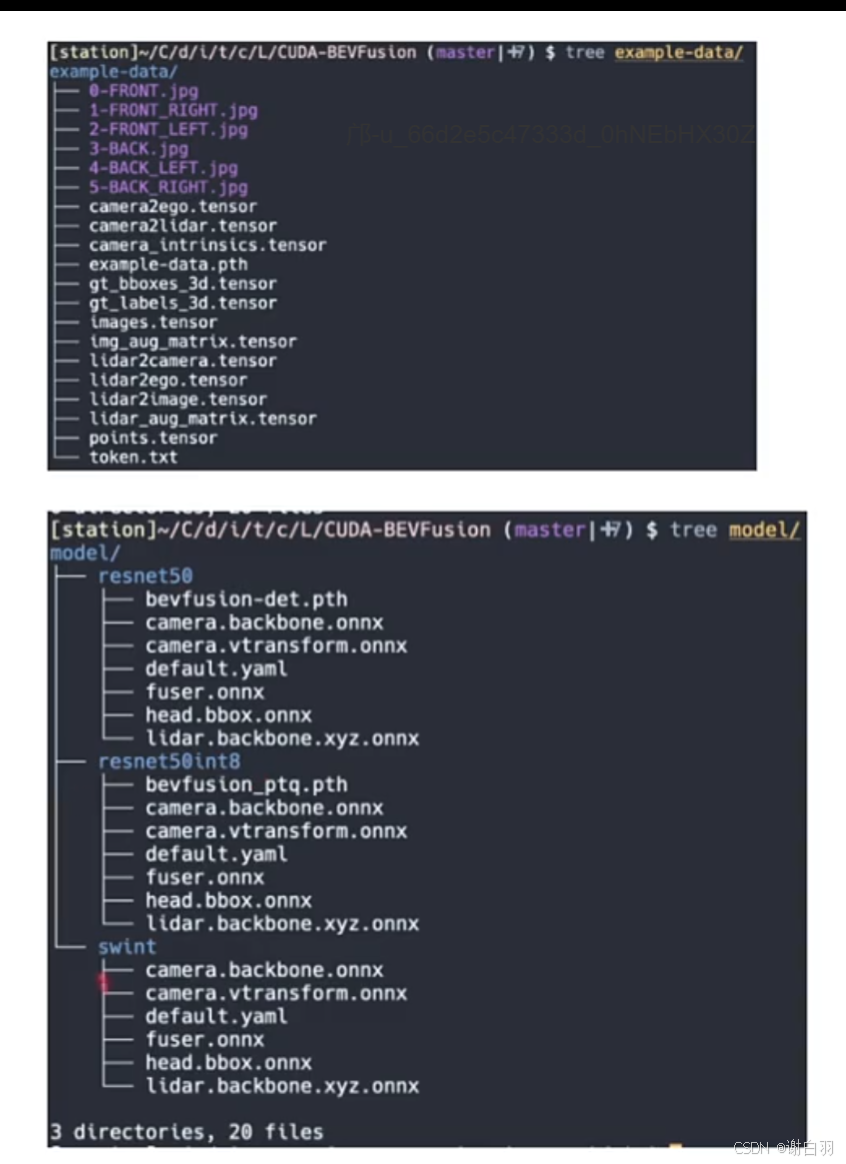
文件内容目录
(6)配置环境
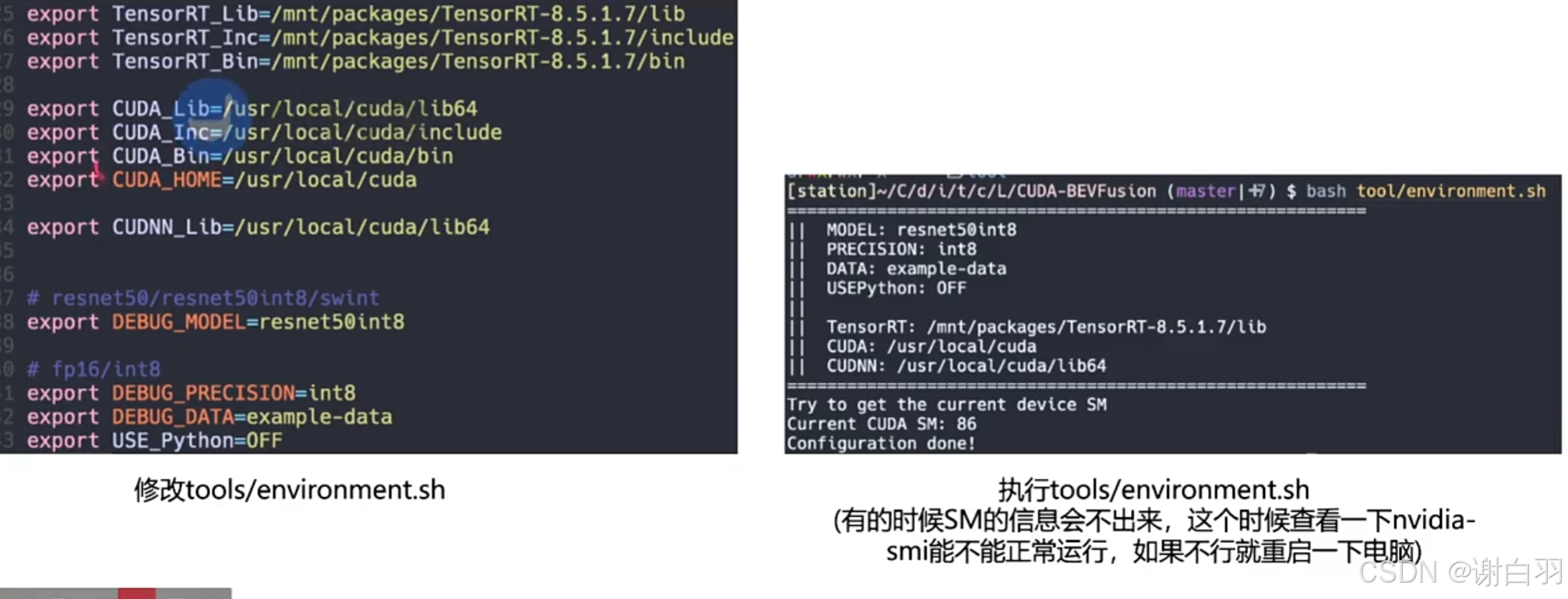
(7)创建引擎(注意:这里的int8没有做校准,因为读取的onnx是带有QDQ节点的)
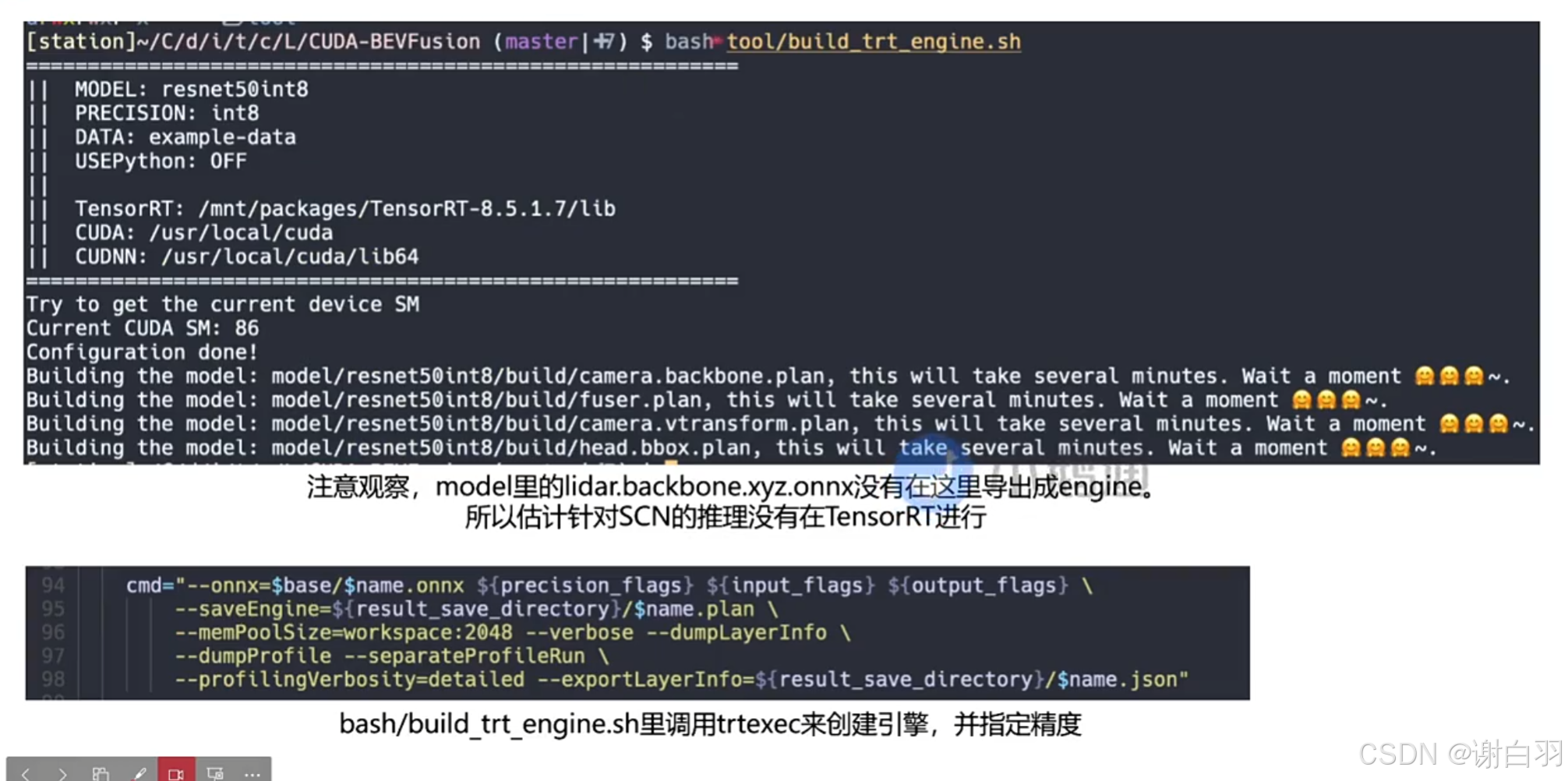
这里针对的是四个onnx做模型创建:
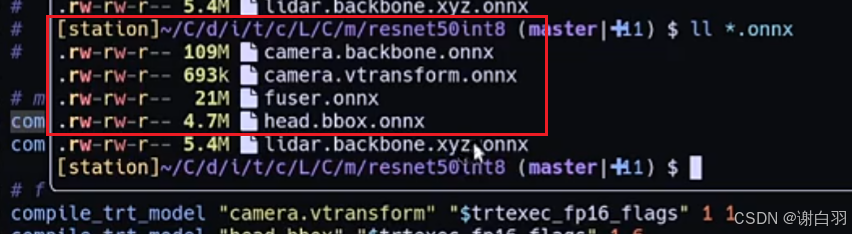
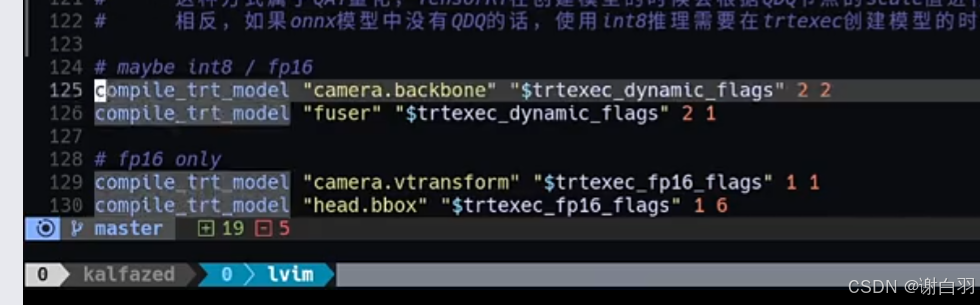
在脚本的这个位置指定
-
注意:(这里没做calibration量化的原因)
①因为这个onnx已经是带有QDQ节点的,已经自带dynamic range。而calibration也是确定这个dynamic range,所以是不需要再去做校准 -
json保存的是trt-layer的信息

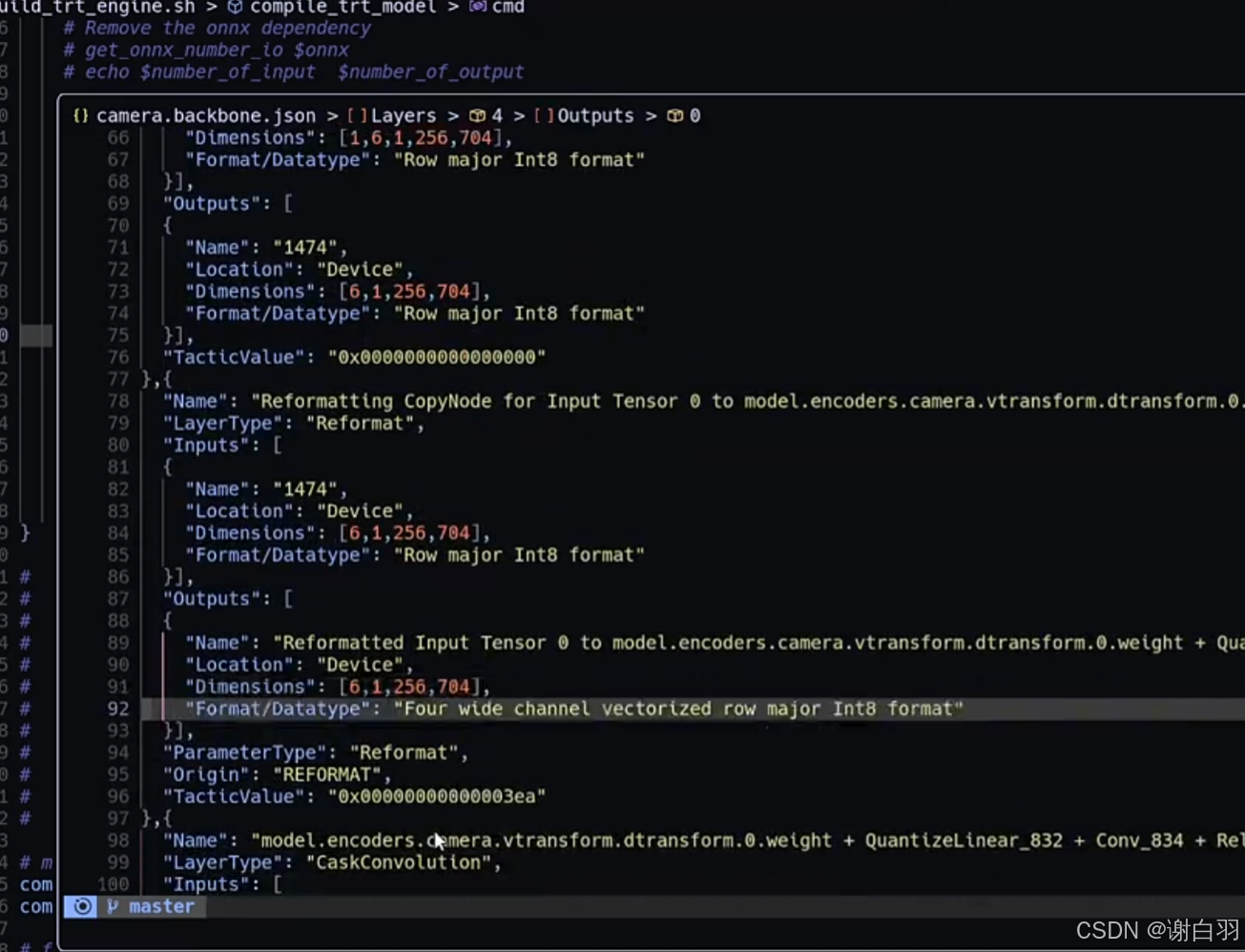
(8)编译+推理
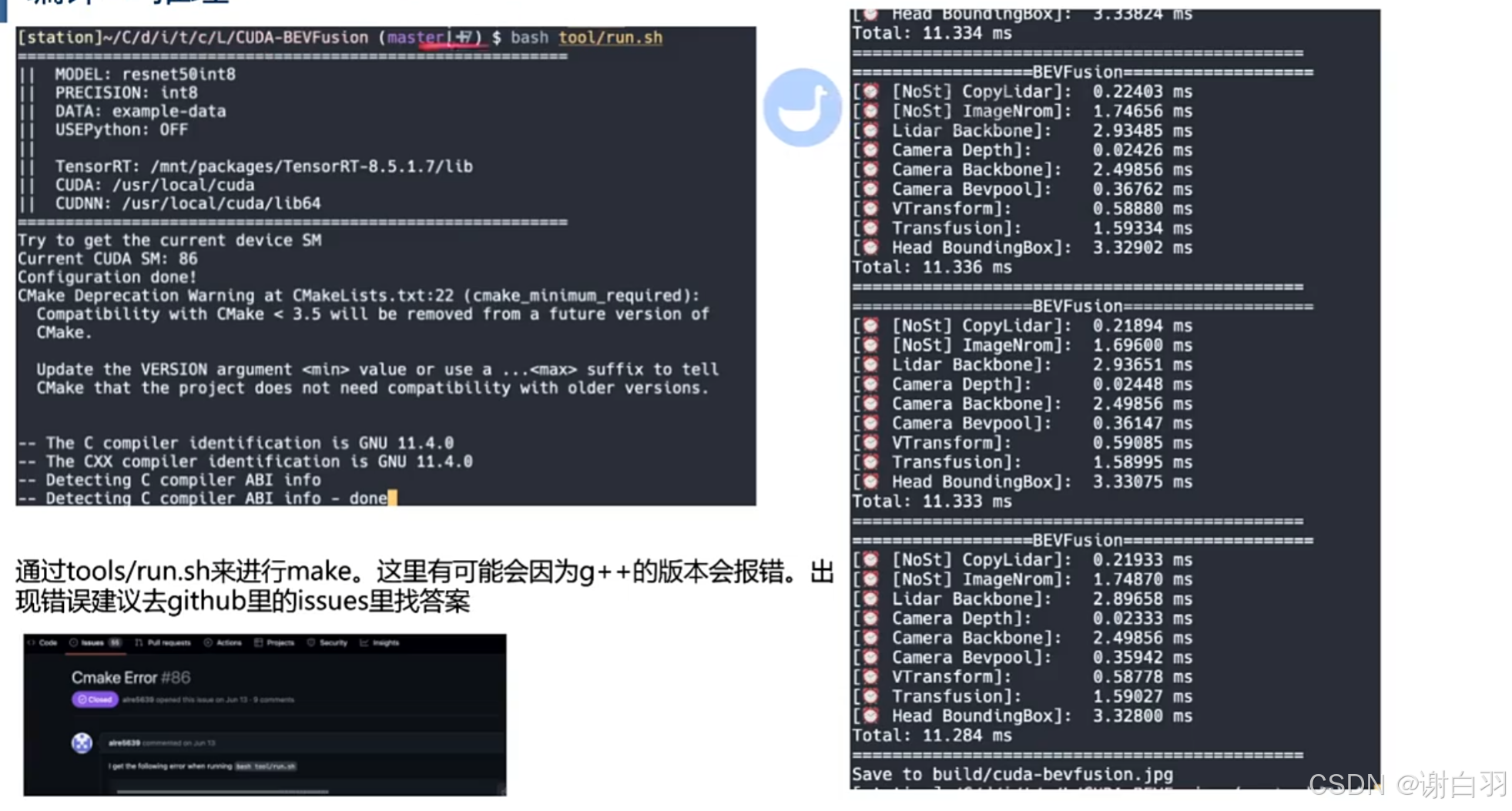
(9)推理结果分析(overhead分析)
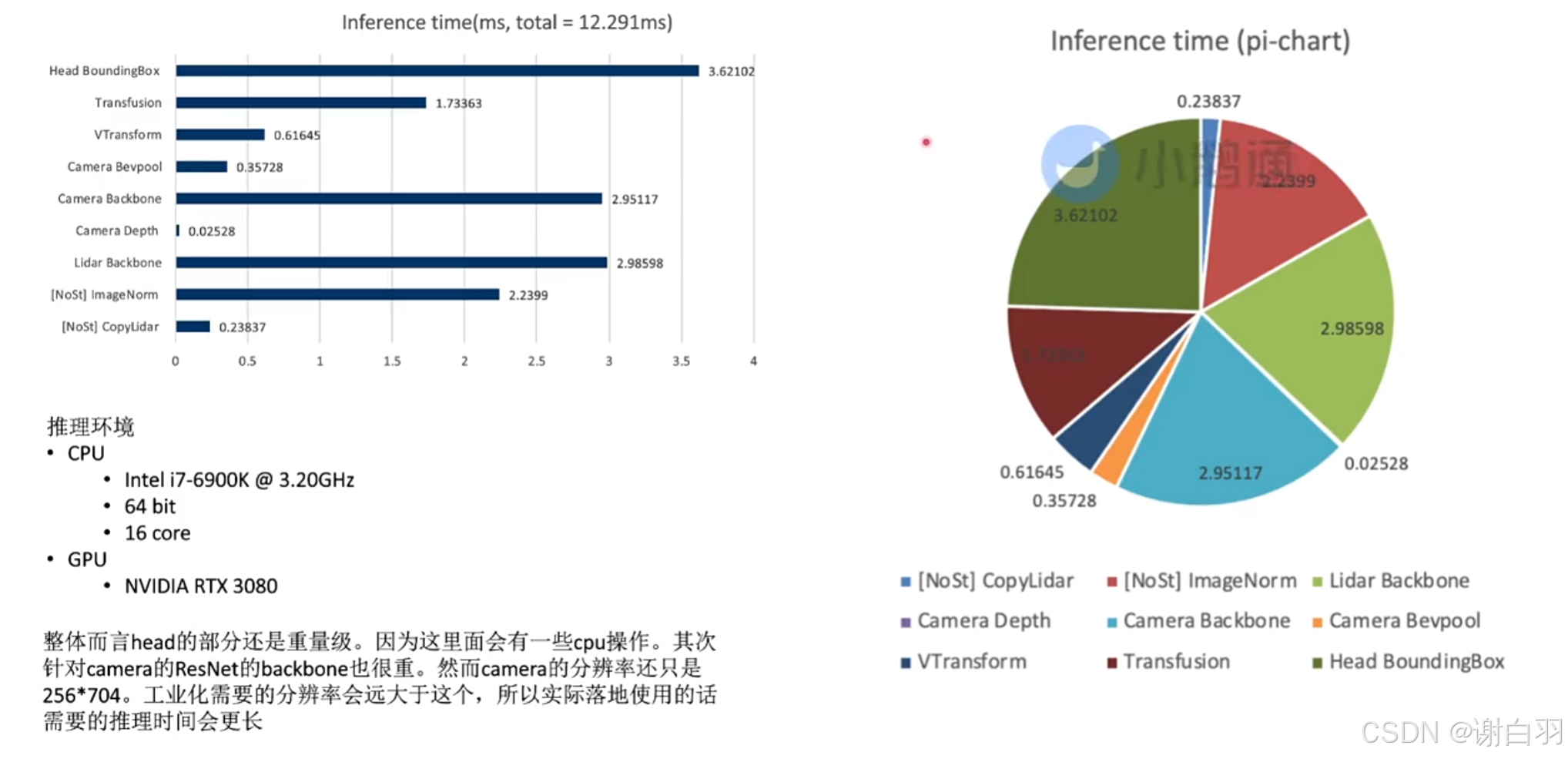
- 总结(推理时间)
①Head BoundingBox:涉及前处理和内存相关操作,可能涉及的时间比较长
②实际camera backbone那边需要的图片工业落地可能要达到2K的清晰度,所以需要的推理时间会更长
2)About-spconv-algorithm(学习spconv的原理,处理3D点云做高效卷积)
- 学习目标
①理解spconv和conv的区别
②理解计算原理和流程
③理解导出onnx需要考虑的事情
(1)基础原理
原因:由于input只有int0参数是非零,所以只需要计算out0、out1
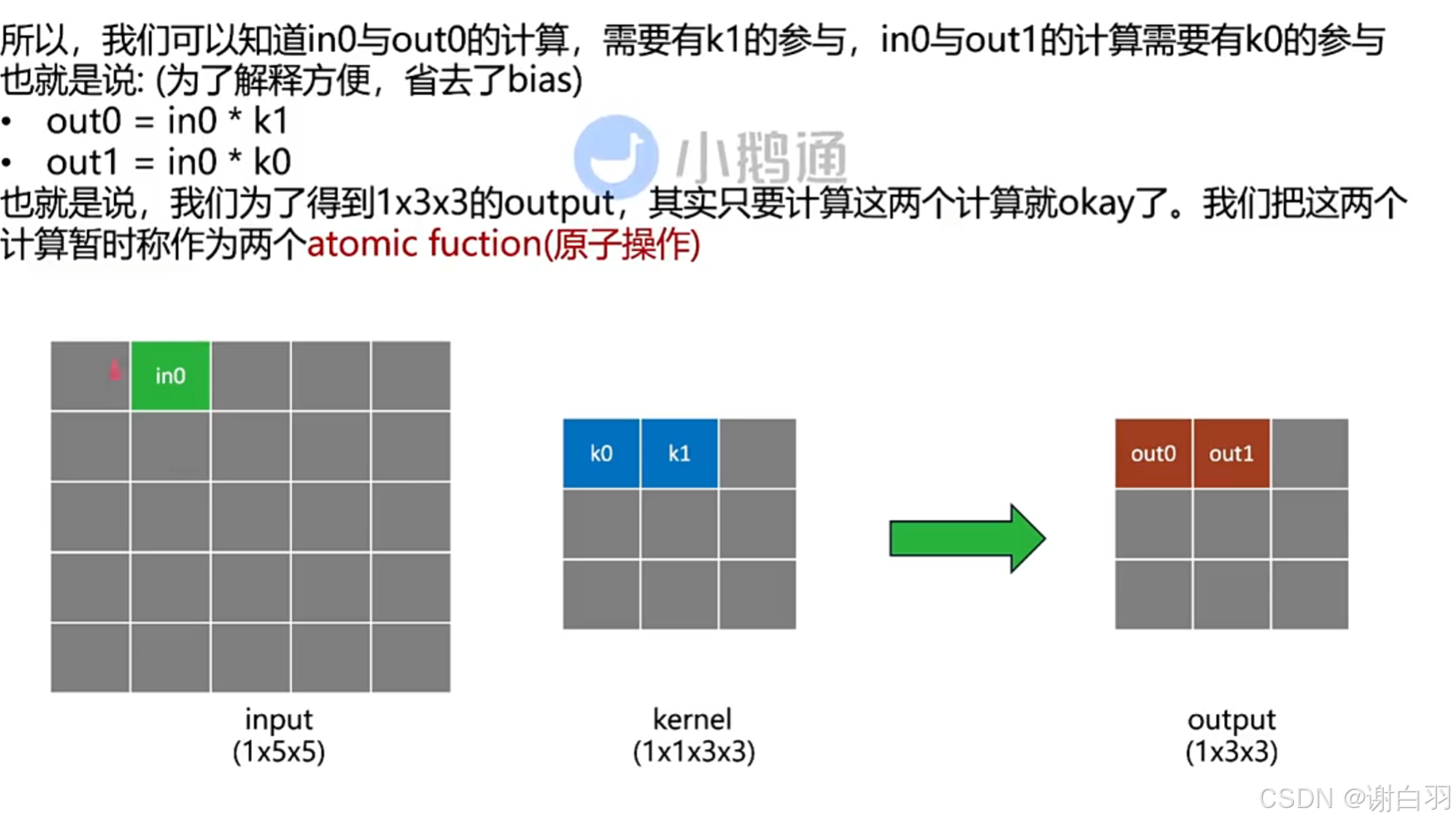
用table存储input和output,分别起名为P_in和P_out,再用rulebook的方式去存储这种关系
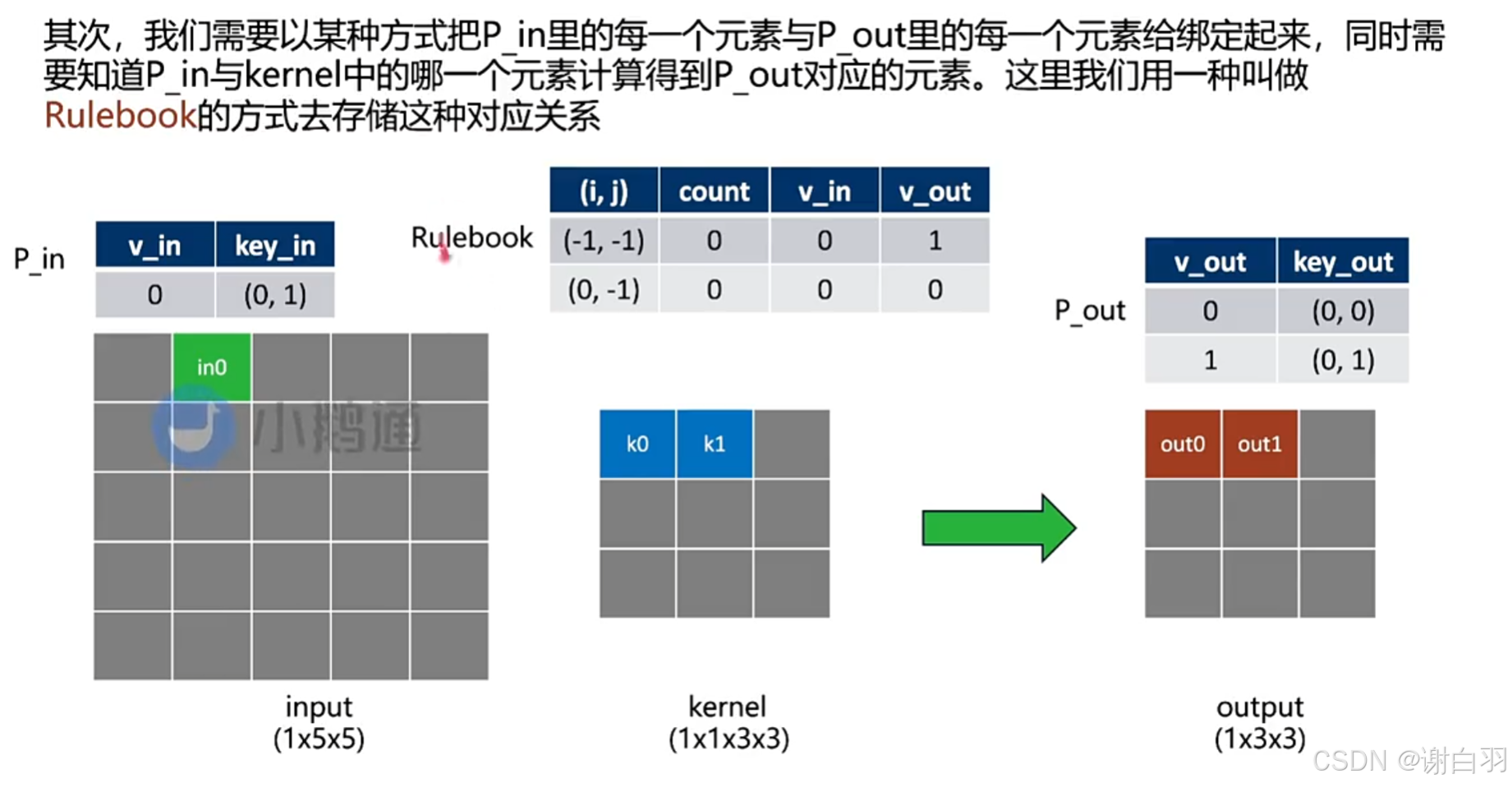
①第一列(i,j):
(-1,-1):表示相对于中间点,k0坐标是(-1,-1)
(0,-1):表示相对于中间点,k1坐标是(0,-1)
②count:
这个点表示涉及的计算是编号的第几个
③v_in:
表示输入的点是哪个点
④v_out:
表示输出的点是哪个点
-
总结(可以这么理解)
①Rulebook第一行,v_in是P_in的v_In,坐标为(0,1)的点做计算,得出v_out为1的点,v_out是1的话,就是表示P_out那边坐标为(0,1)的值 -
如果是多层input来计算,计算结果累加
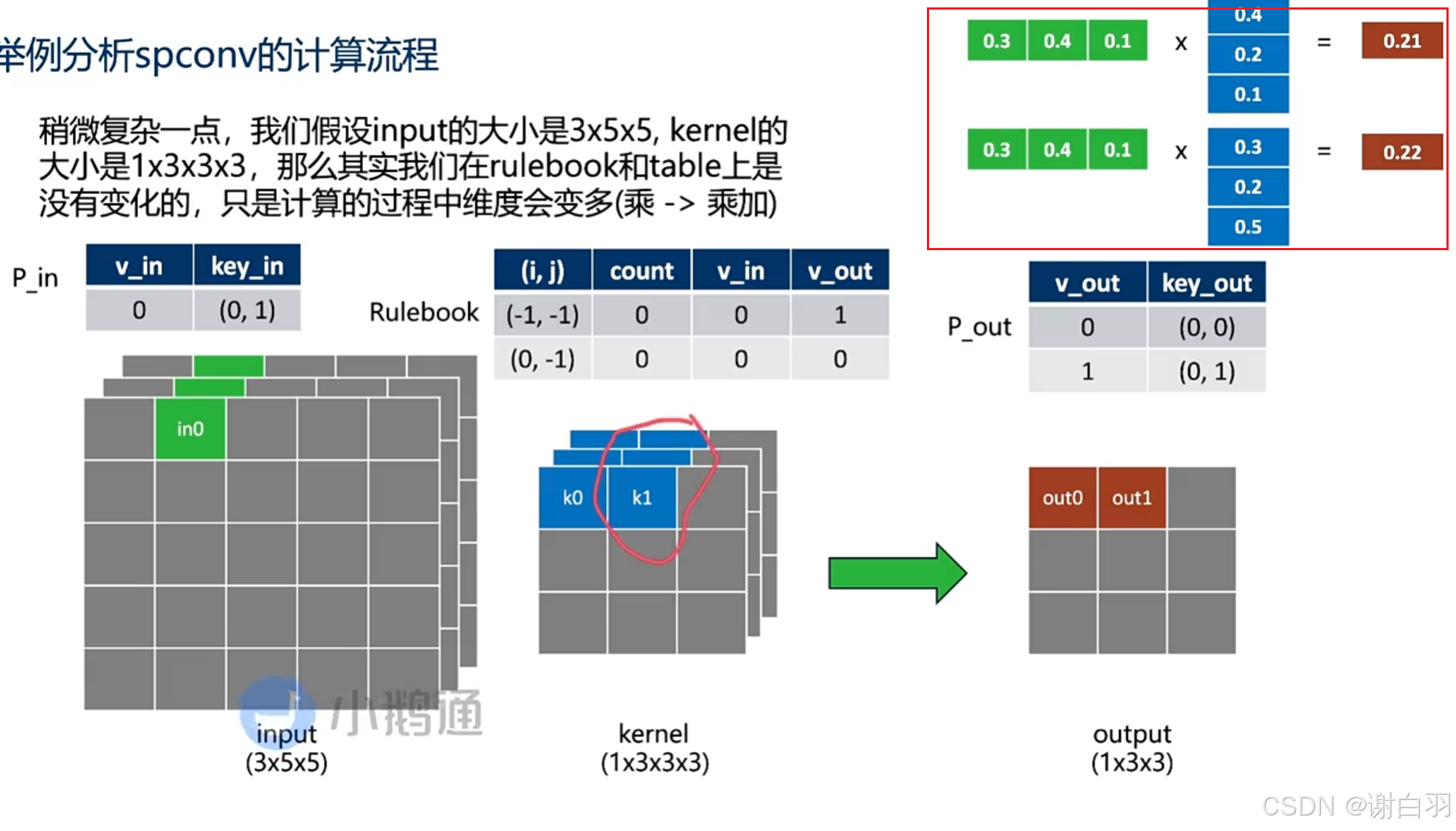
-
如果是多层kernel
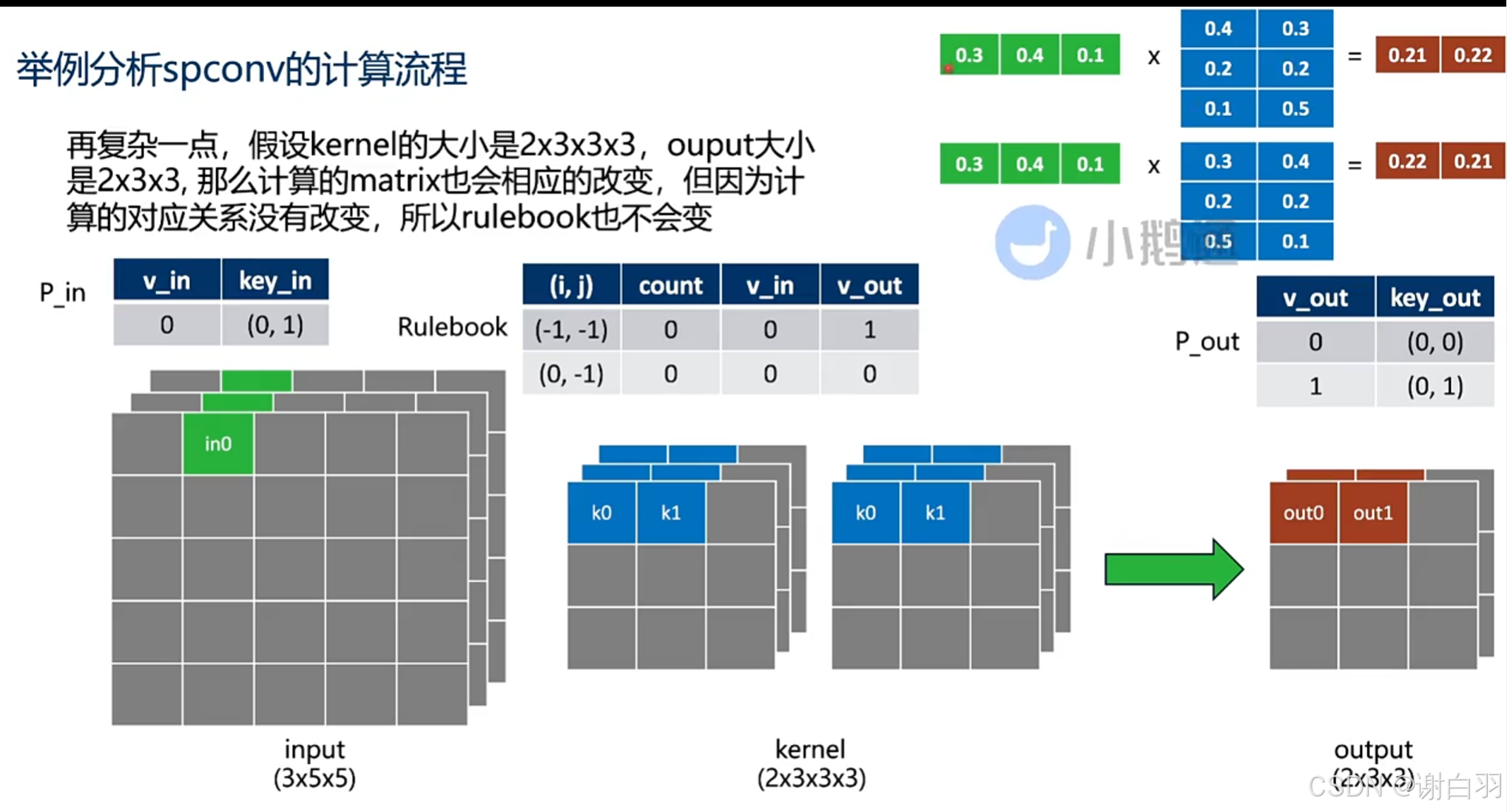
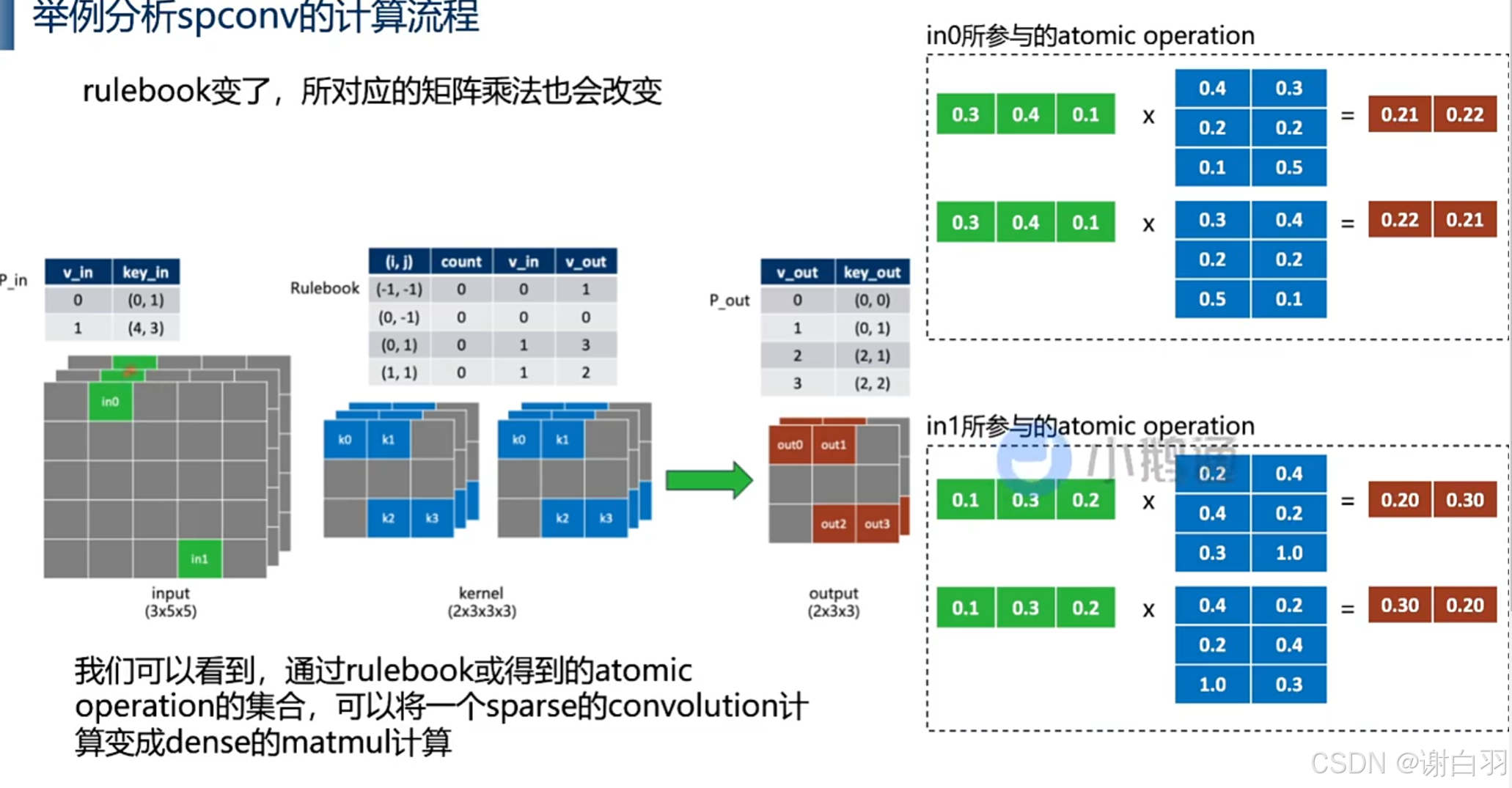
- 总结(可以看到,可以将一个稀疏的conv计算变成dense的matmul计算)
(2)spconv核心代码计算

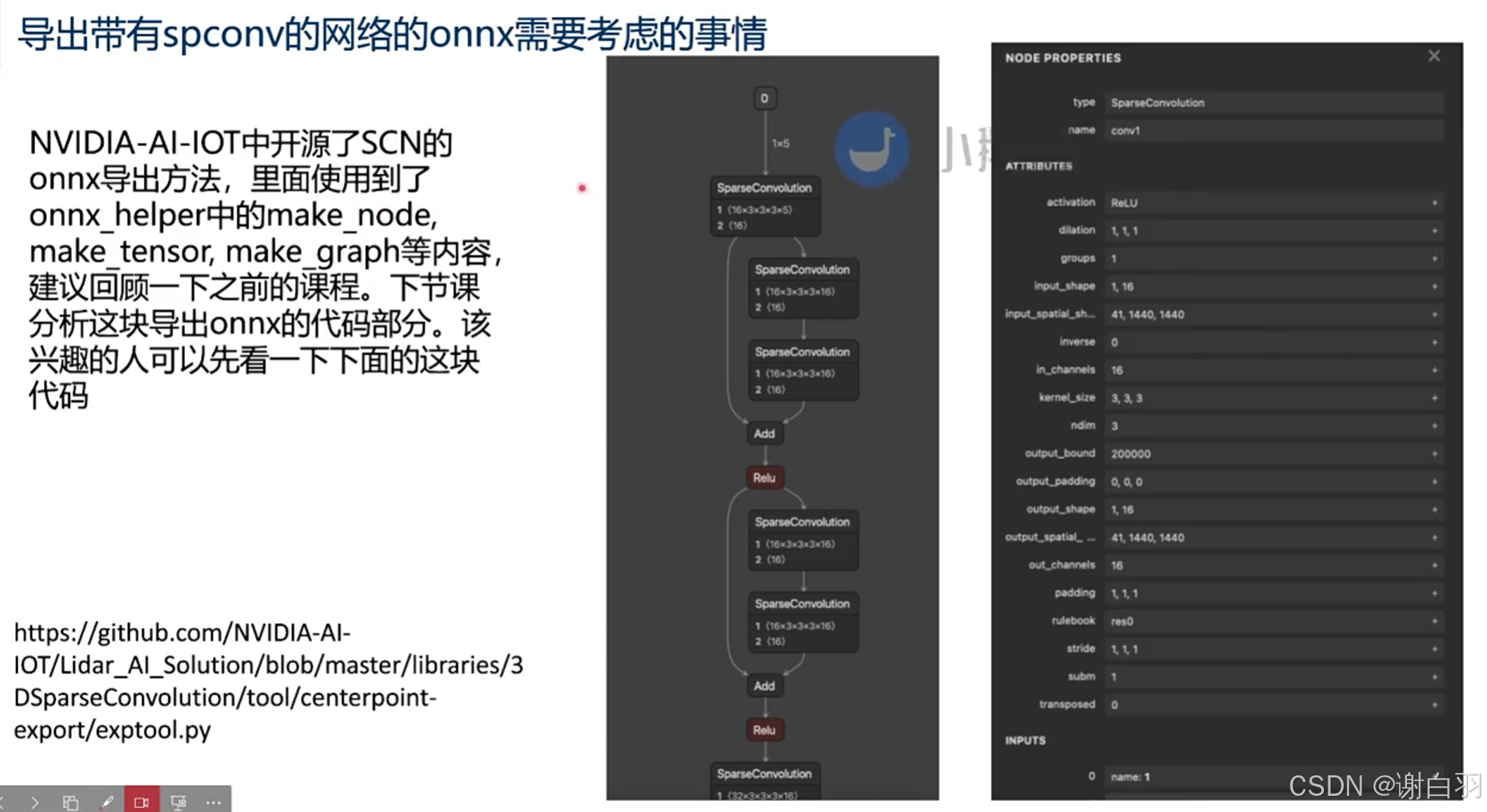
(3)导出带有spconv网络的onnx需要考虑的事
-
背景
scn需要结合其他网络部分(ResNet,BEVPool等等)导出成onnx,使用CUDA,TensorRT进行加速部署,所以我们需要将SCN导出成onnx -
需求遇到的问题
①spconv的onnx节点没有,我们需要自己创建一个
②pytorch->onnx的过程会对DNN的Forward处理进行trace,从而得到onnx相对应的计算节点,但是spconv内部处理复杂,以及layer间的tensor的形式比较特殊,所以没法正常导出 -
解决方案
①对spconv.conv.SparseConvolution.forward的实现进行重定位,取出spconv推理需要的信息,通过onnx_helper创建custom node和graph,实现导出 -
具体实现
3)Export-SParse-Convolution-Network(学习导出带有spconv的SCN网络的onnx)
- 学习目标
①学习利用hook截取spconv的forward
②自定义onnx算子导出onnx的方法
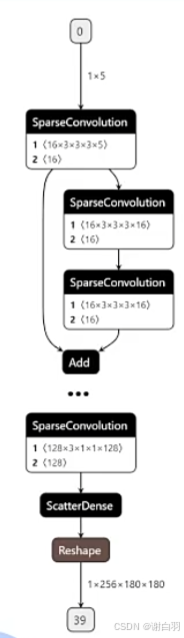
(1)使用spconv进行SCN的推理测试
- 项目地址

- spconv
- 导出onnx
1\ Download and configure the CenterPoint environment from https://github.com/tianweiy/CenterPoint
2\ Export SCN ONNX
$ cp -r tool/centerpoint-export path/to/CenterPoint
$ cd path/to/CenterPoint
$ python centerpoint-export/export-scn.py --ckpt=epoch_20.pth --save-onnx=scn.nuscenes.onnx
$ cp scn.nuscenes.onnx path/to/3DSparseConvolution/workspace/
- 编译和运行
①Build and run test
$ sudo apt-get install libprotobuf-dev
$ cd path/to/3DSparseConvolution
->>>>>> modify main.cpp:80 to scn.nuscenes.onnx
$ make fp16 -j
🙌 Output.shape: 1 x 256 x 180 x 180
[PASSED 🤗], libspconv version is 1.0.0
To verify the results, you can execute the following command.
Verify Result:
python tool/compare.py workspace/centerpoint/out_dense.torch.fp16.tensor workspace/centerpoint/output.zyx.dense --detail
[PASSED].
②Verify output验证输出
$ python tool/compare.py workspace/centerpoint/out_dense.torch.fp16.tensor workspace/centerpoint/output.zyx.dense --detail
================ Compare Information =================
CPP Tensor: 1 x 256 x 180 x 180, float16 : workspace/centerpoint/out_dense.torch.fp16.tensor
PyTorch Tensor: 1 x 256 x 180 x 180, float16 : workspace/centerpoint/output.zyx.dense
[absdiff]: max:0.19891357421875, sum:1438.463379, std:0.001725, mean:0.000173
CPP: absmax:3.066406, min:0.000000, std:0.034445, mean:0.003252
Torch: absmax:3.054688, min:0.000000, std:0.034600, mean:0.003279
[absdiff > m75% --- 0.149185]: 0.000 %, 2
[absdiff > m50% --- 0.099457]: 0.000 %, 17
[absdiff > m25% --- 0.049728]: 0.010 %, 846
[absdiff > 0]: 2.140 %, 177539
[absdiff = 0]: 97.860 %, 8116861
[cosine]: 99.876 %
======================================================
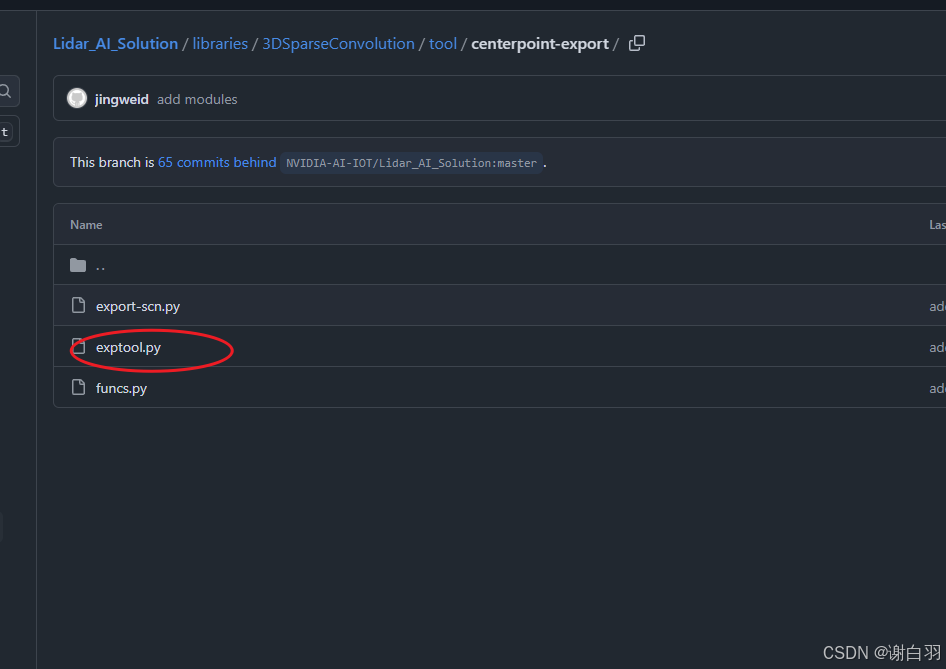
(2)学习CenterPoint中的SCN是如何导出onnx的
-
实际导出代码
-
流程
①export-scn.py导出的主要函数是exptool.py的export_onnx函数
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Export scn to onnx file")
parser.add_argument("--in-channel", type=int, default=5, help="SCN num of input channels")
parser.add_argument("--ckpt", type=str, default=None, help="SCN Checkpoint (scn backbone checkpoint)")
parser.add_argument("--input", type=str, default=None, help="input pickle data, random if there have no input")
parser.add_argument("--save-onnx", type=str, default="centerpoint.scn.onnx", help="output onnx")
parser.add_argument("--save-tensor", type=str, default=None, help="Save input/output tensor to file. The purpose of this operation is to verify the inference result of c++")
args = parser.parse_args()
model = SpMiddleResNetFHD(args.in_channel).cuda().eval().half()
if args.ckpt:
model = funcs.load_scn_backbone_checkpoint(model, args.ckpt)
model = funcs.layer_fusion(model)
print("Fusion model:")
print(model)
if args.input:
with open(args.input, "rb") as f:
voxels, coors, spatial_shape, batch_size = pickle.load(f)
voxels = torch.tensor(voxels).half().cuda()
coors = torch.tensor(coors).int().cuda()
else:
voxels = torch.zeros(1, args.in_channel).half().cuda()
coors = torch.zeros(1, 4).int().cuda()
batch_size = 1
spatial_shape = [1440, 1440, 40]
exptool.export_onnx(model, voxels, coors, batch_size, spatial_shape, args.save_onnx, args.save_tensor)
②上回调函数,当执行到spconv.conv.SparseConvolution.forward函数的时候,执行函数symbolic_sparse_convolution,主要是调用helper创建node,添加到onnx里面去
@register_node("spconv.conv.SparseConvolution.forward")
def symbolic_sparse_convolution(self, ilayer, y, x):
register_tensor(y)
print(f" --> SparseConvolution{ilayer}[{'subm' if self.subm else 'conv'}] -> Input {get_tensor_id(x)}, Output {get_tensor_id(y)}")
if self.transposed:
output_size = spconv.ops.get_deconv_output_size(
x.features.size(), self.kernel_size, self.stride, self.padding, self.dilation, self.output_padding
)
else:
output_size = spconv.ops.get_conv_output_size(
x.features.size(), self.kernel_size, self.stride, self.padding, self.dilation
)
if self.subm:
output_size[0] = x.features.size(0)
output_size[1] = self.out_channels
inputs = [
get_tensor_id(x),
append_initializer(self.weight.data, f"spconv{ilayer}.weight"),
]
if self.bias is not None:
inputs.append(append_initializer(self.bias.data, f"spconv{ilayer}.bias"))
act_type_name = {
tv.gemm.Activation.ReLU : "ReLU",
tv.gemm.Activation.None_ : "None",
tv.gemm.Activation.Sigmoid : "Sigmoid",
tv.gemm.Activation.LeakyReLU : "LeakyReLU"
}
algo_name = {
ConvAlgo.MaskImplicitGemm : "MaskImplicitGemm",
ConvAlgo.MaskSplitImplicitGemm : "MaskSplitImplicitGemm",
ConvAlgo.Native : "Native",
}
output_bound = 200000
if hasattr(self, "output_bound"):
output_bound = self.output_bound
nodes.append(
helper.make_node(
"SparseConvolution", inputs, [get_tensor_id(y)], f"conv{ilayer}",
ndim = self.ndim,
input_spatial_shape = x.spatial_shape,
output_spatial_shape = y.spatial_shape,
in_channels = self.in_channels,
out_channels = self.out_channels,
kernel_size = self.kernel_size,
output_bound = output_bound,
stride = self.stride,
dilation = self.dilation,
padding = self.padding,
transposed = self.transposed,
inverse = self.inverse,
output_padding = self.output_padding,
groups = self.groups,
subm = self.subm,
rulebook = self.indice_key,
activation = act_type_name[self.act_type],
input_shape = x.features.shape,
output_shape = y.features.shape
)
)
③export_onnx先创建两个输入/输出节点,再根据网络中所有节点放在一起创建graph网格
def export_onnx(model, voxels, coors, batch_size, spatial_shape, save_onnx, save_tensor):
global avoid_reuse_container, tensor_map, nodes, initializers, enable_trace
avoid_reuse_container = []
tensor_map = {}
nodes = []
initializers = []
print("Tracing model inference...")
print("> Do inference...")
with torch.no_grad():
register_tensor(voxels)
enable_trace = True
y = model(voxels, coors, batch_size, spatial_shape)[0]
enable_trace = False
if save_tensor is not None:
print("> Do save tensor, The purpose of this operation is to verify the inference result of C++")
print(f" --> Save inference input voxels to {save_tensor}.voxels, voxels.shape = {voxels.shape}")
funcs.save_tensor(voxels, f"{save_tensor}.voxels")
print(f" --> Save inference input coors to {save_tensor}.coors, coors.shape = {coors.shape}")
funcs.save_tensor(coors, f"{save_tensor}.coors")
print(f" --> Save inference output to {save_tensor}.output, output.shape = {y.shape}")
funcs.save_tensor(y, f"{save_tensor}.output")
print(f" --> Save spatial_shape is {spatial_shape}, batch size is {batch_size}")
print(f" --> Save spatial_shape and batch size to {save_tensor}.info")
funcs.save_tensor([batch_size] + spatial_shape, f"{save_tensor}.info")
print("Tracing done!")
inputs = [
helper.make_value_info(
name="0",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT16,
shape=voxels.size()
)
)
]
outputs = [
helper.make_value_info(
name=get_tensor_id(y),
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT16,
shape=y.size()
)
)
]
graph = helper.make_graph(
name="scn",
inputs=inputs,
outputs=outputs,
nodes=nodes,
initializer=initializers
)
opset = [
helper.make_operatorsetid("ai.onnx", 11)
]
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, save_onnx)
print(f"🚀 The export is completed. ONNX save as {save_onnx} 🤗, Have a nice day~")
# clean memory
avoid_reuse_container = []
tensor_map = {}
nodes = []
initializers = []
(3)搭建环境跑起来
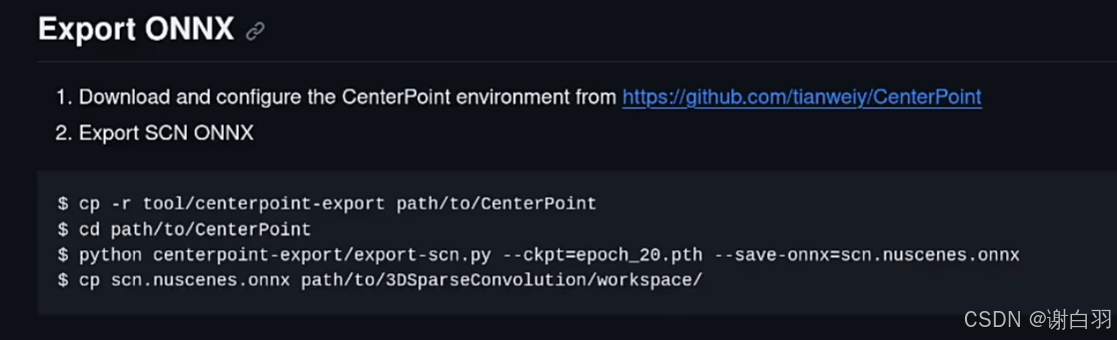
- 步骤
①需要搭建CenterPoint环境
但是它自带的环境是训练用的,很多组件是不需要的
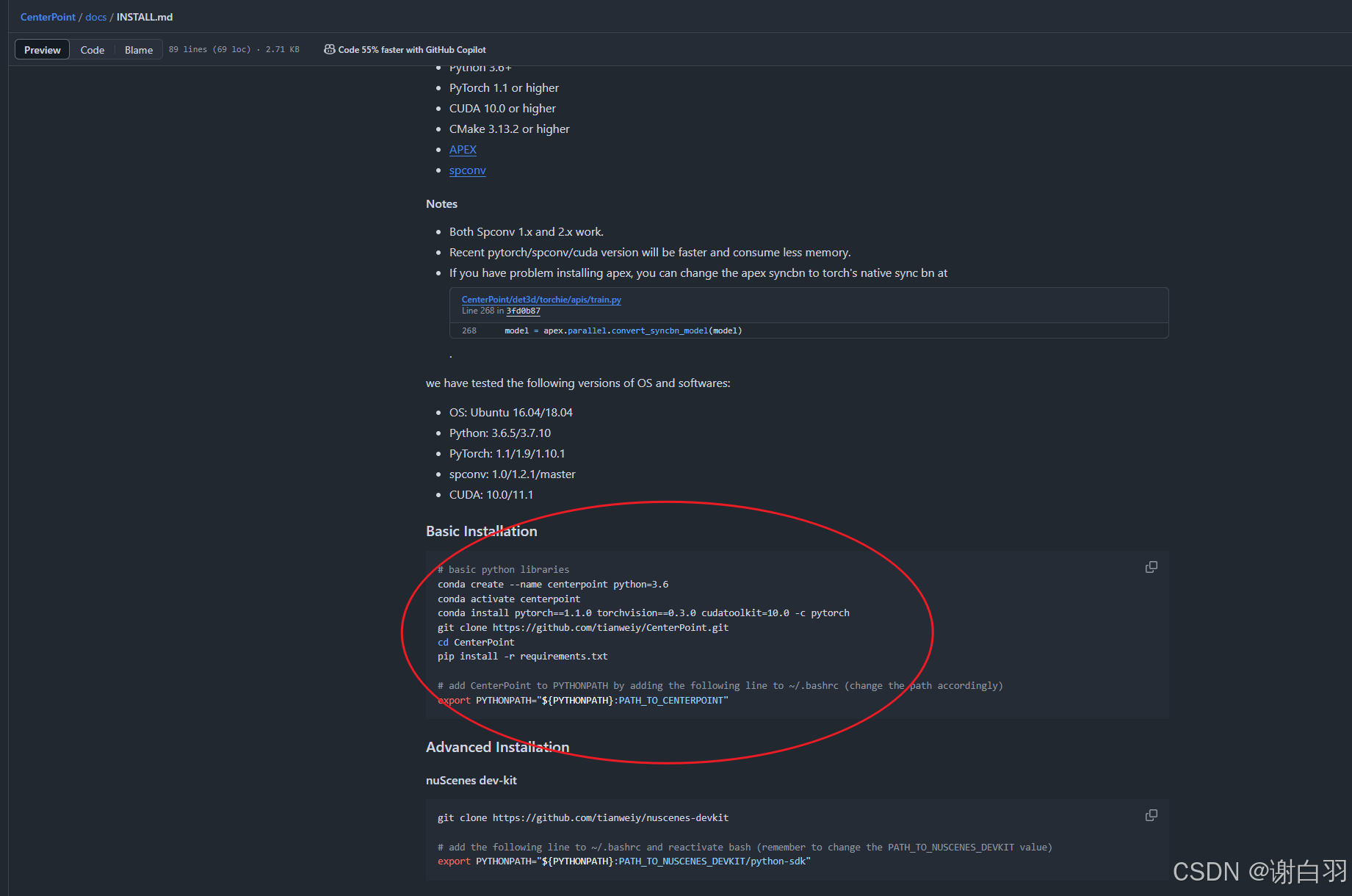
推荐的环境
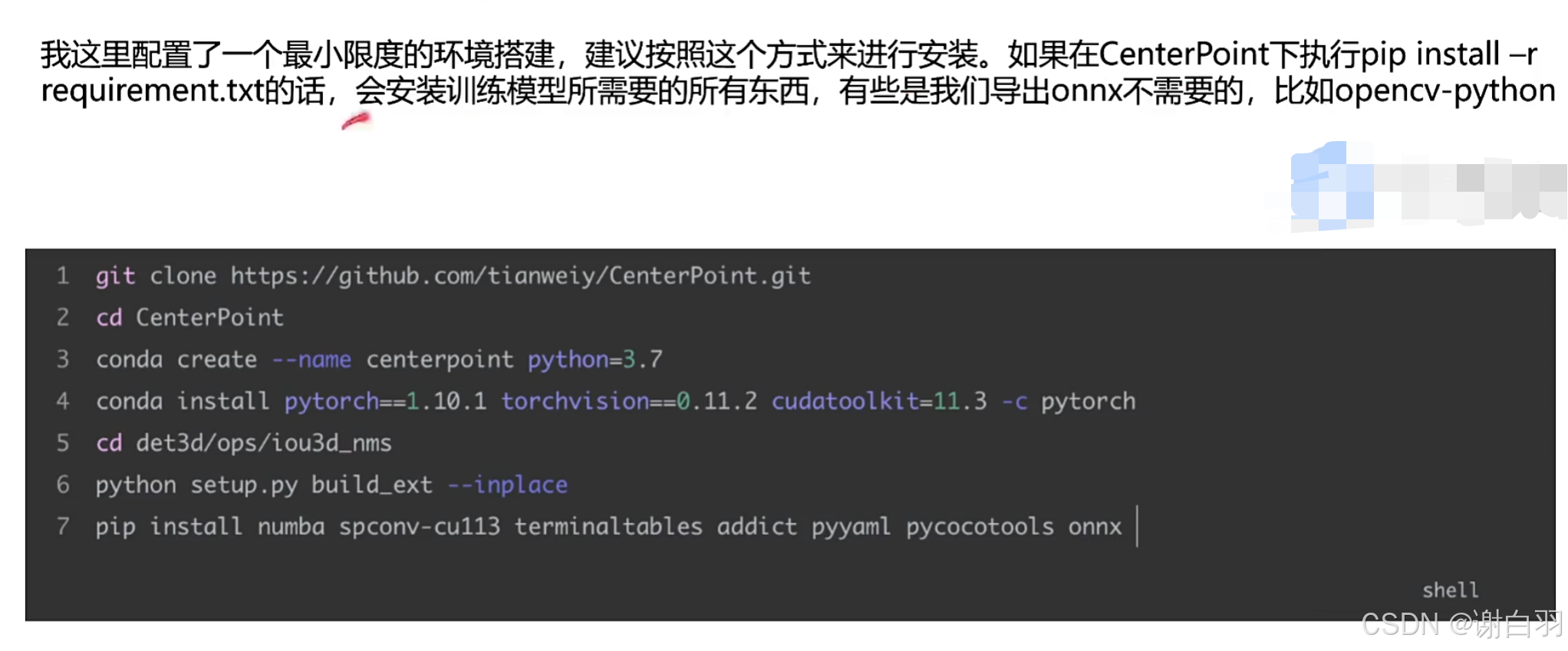
②导出onnx
$ cp -r tool/centerpoint-export path/to/CenterPoint
$ cd path/to/CenterPoint
$ python centerpoint-export/export-scn.py --ckpt=epoch_20.pth --save-onnx=scn.nuscenes.onnx
$ cp scn.nuscenes.onnx path/to/3DSparseConvolution/workspace/
③netron展示onnx

4)Spconv-with-Explicit-GEMM-Conv(显性GEMM conv 是怎么优化的)
- 学习目标
①理解im2col,Explicit GEMM conv
②理解spconv中使用Gather和ScatterAdd做优化的用意是什么
(1)基础知识(GEMM讲解、im2col、数据解释等)
①GEMM:矩阵乘法(Matrix Multiplication)
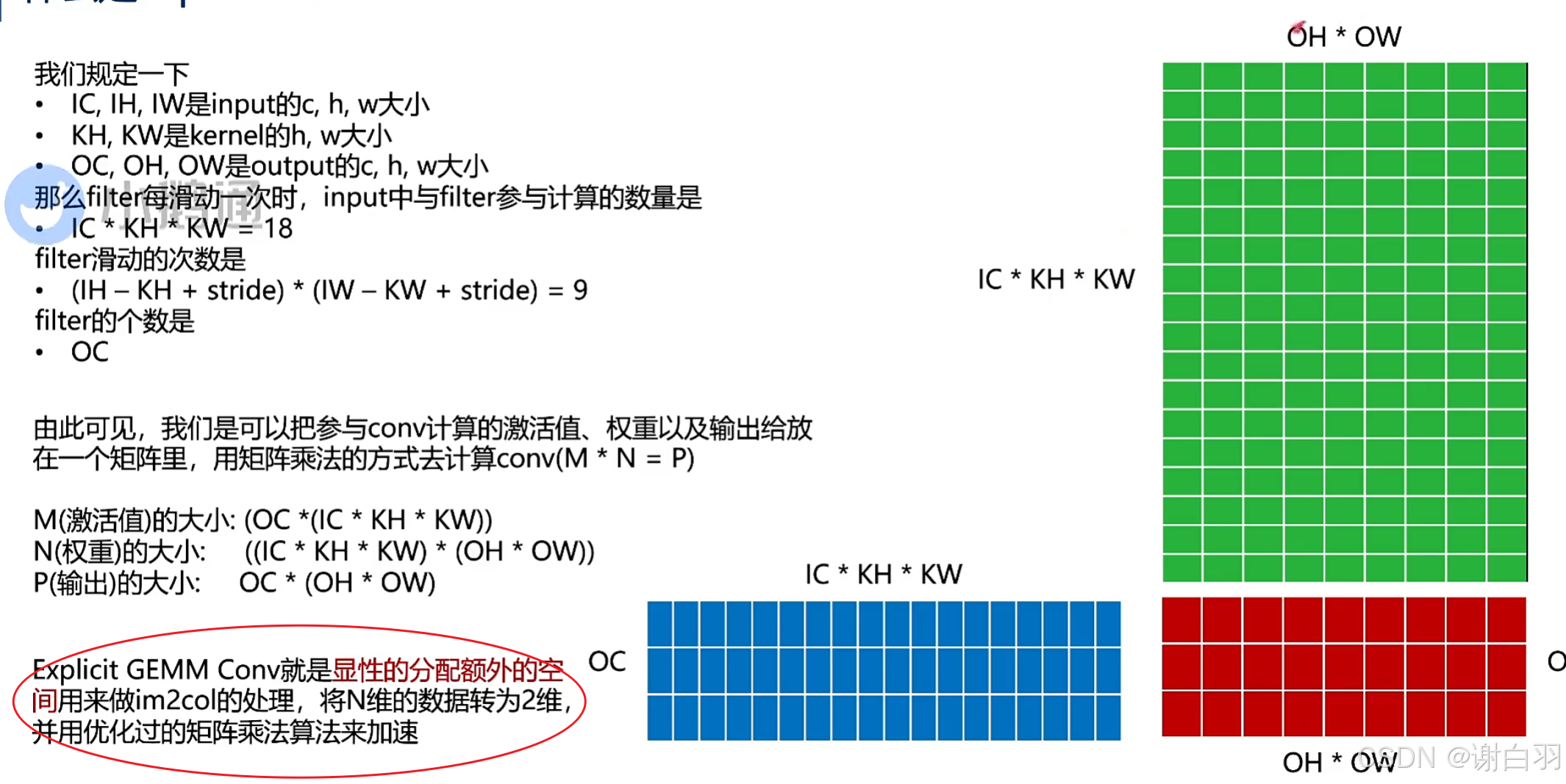
文字解释:
将n维的input、weight、output以及按照output按照一定规律进行展开成2D,之后利用cuDNN中的针对矩阵乘法的方式来进行加速
图片解释:
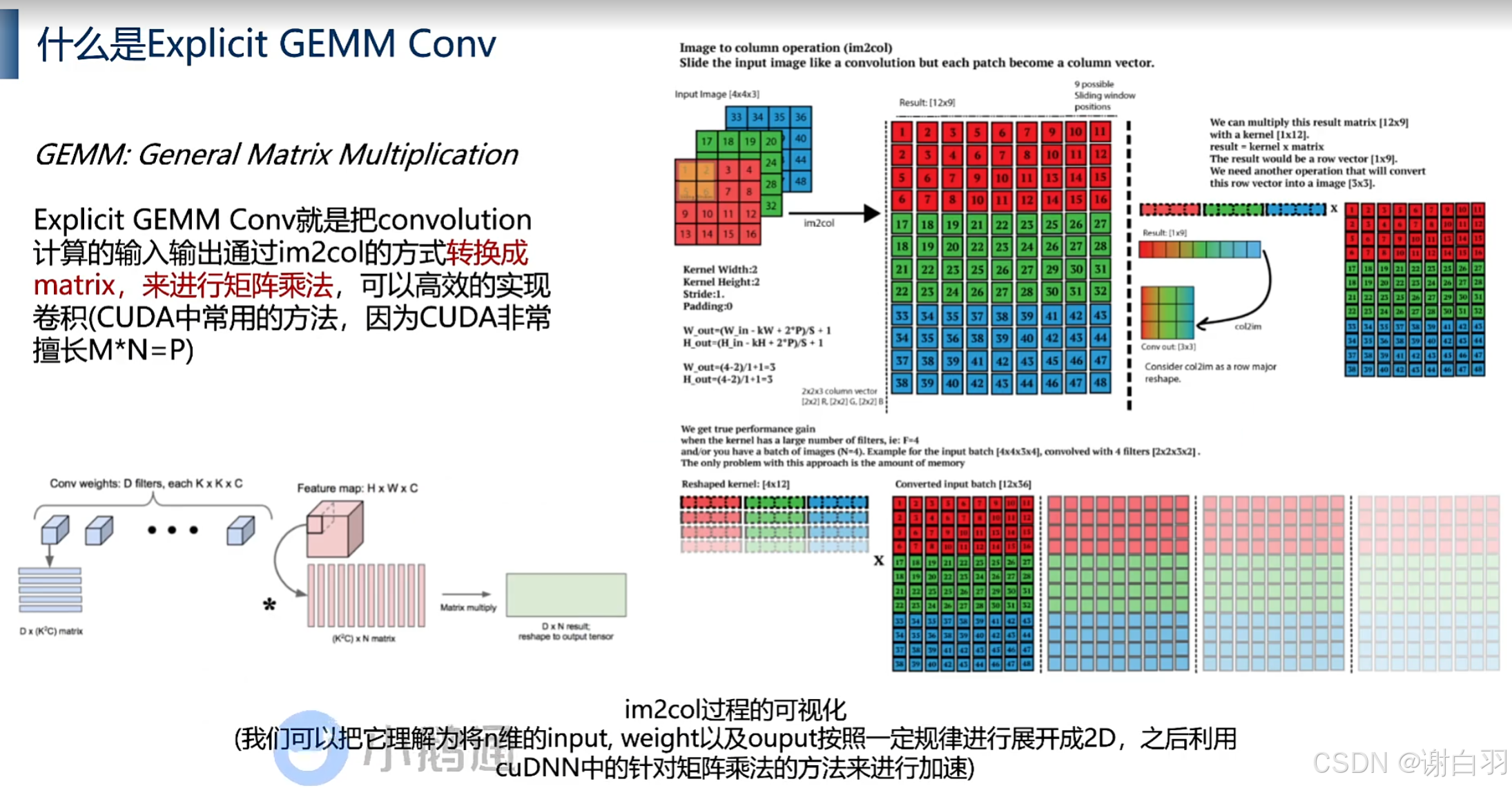
②im2col方法分析(滑动后,矩阵相乘后累加)
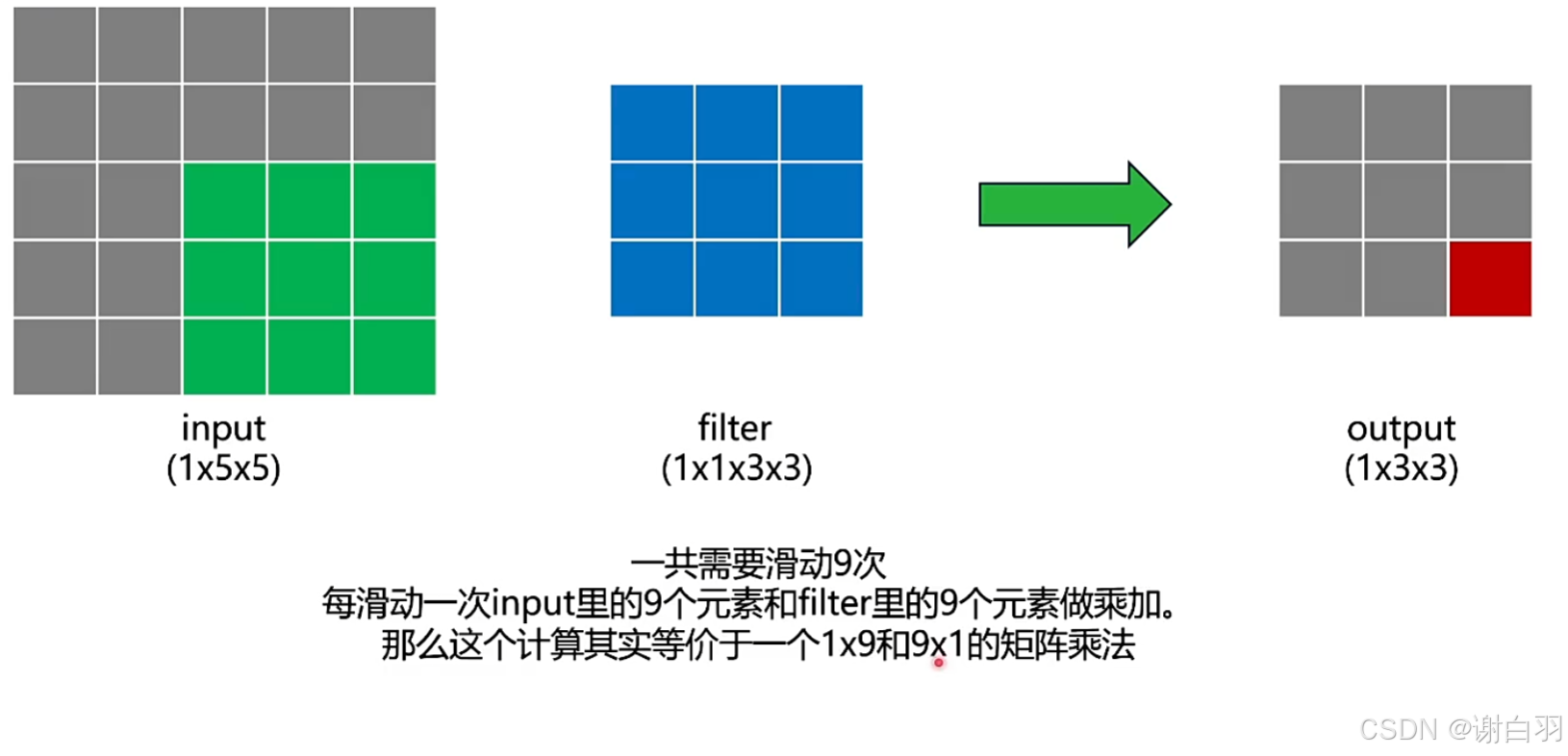
降维后变为

多个channel展开
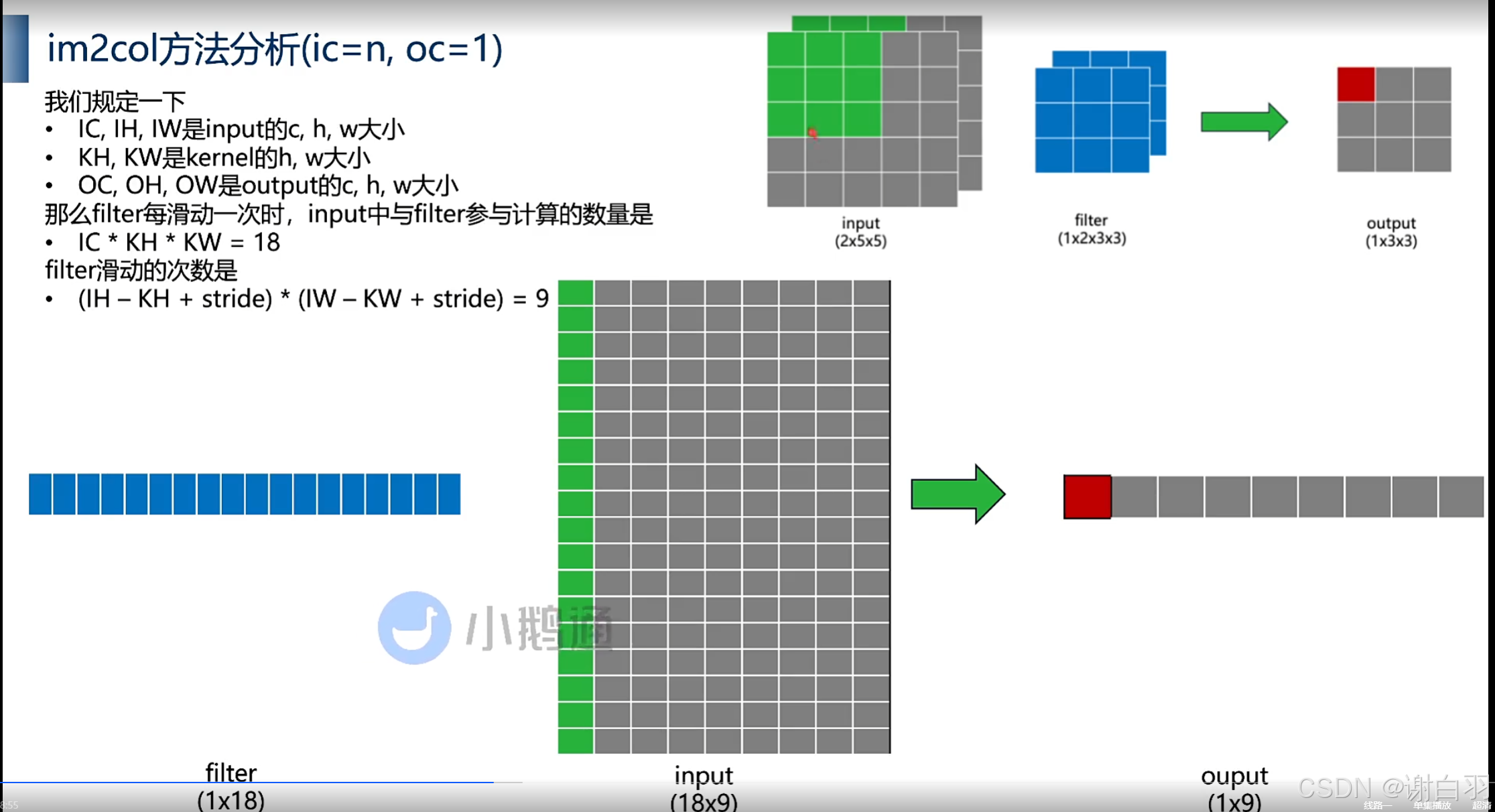
多个filter
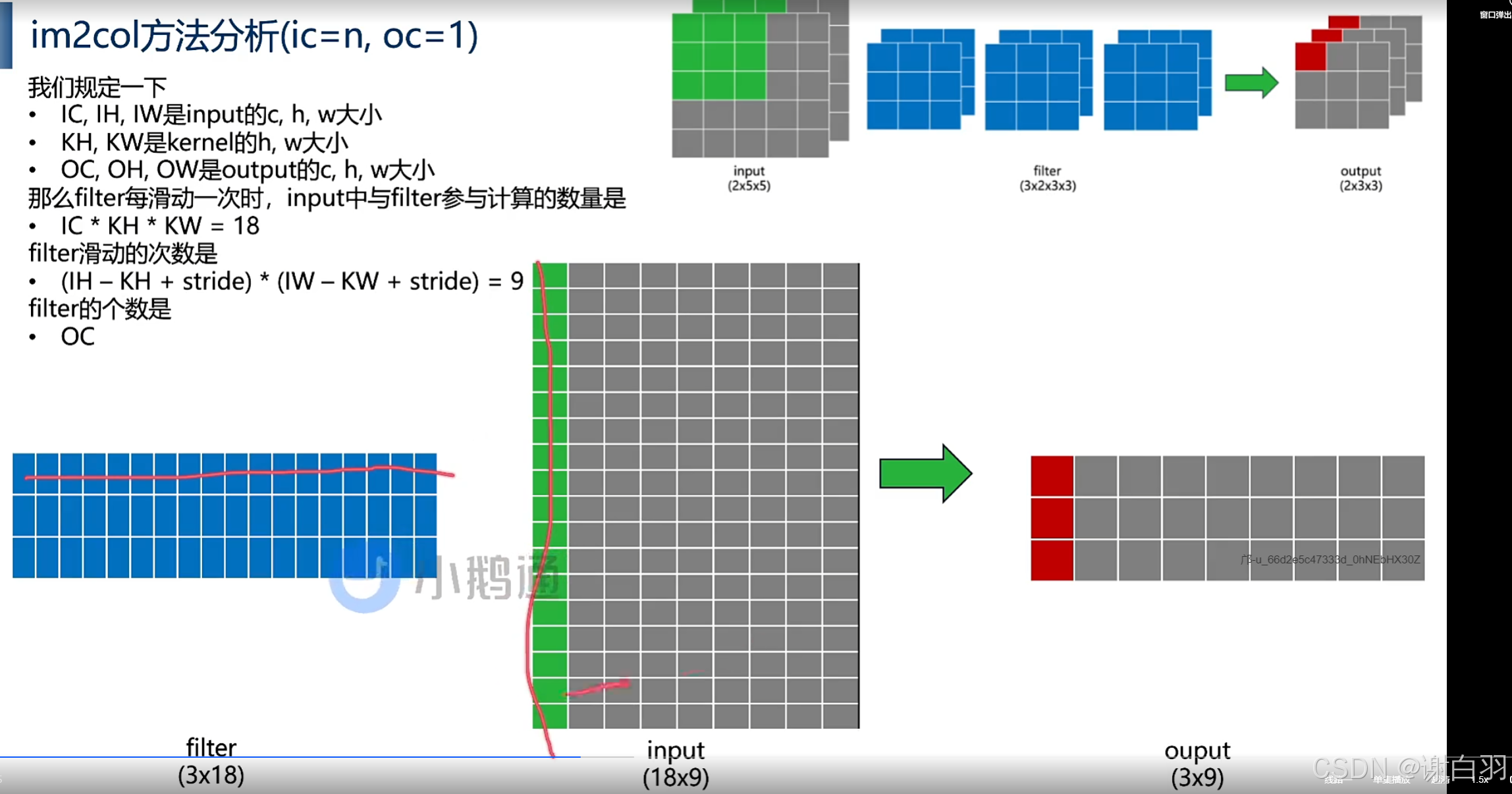
③数据解释
(1)tensor级别


计算总结
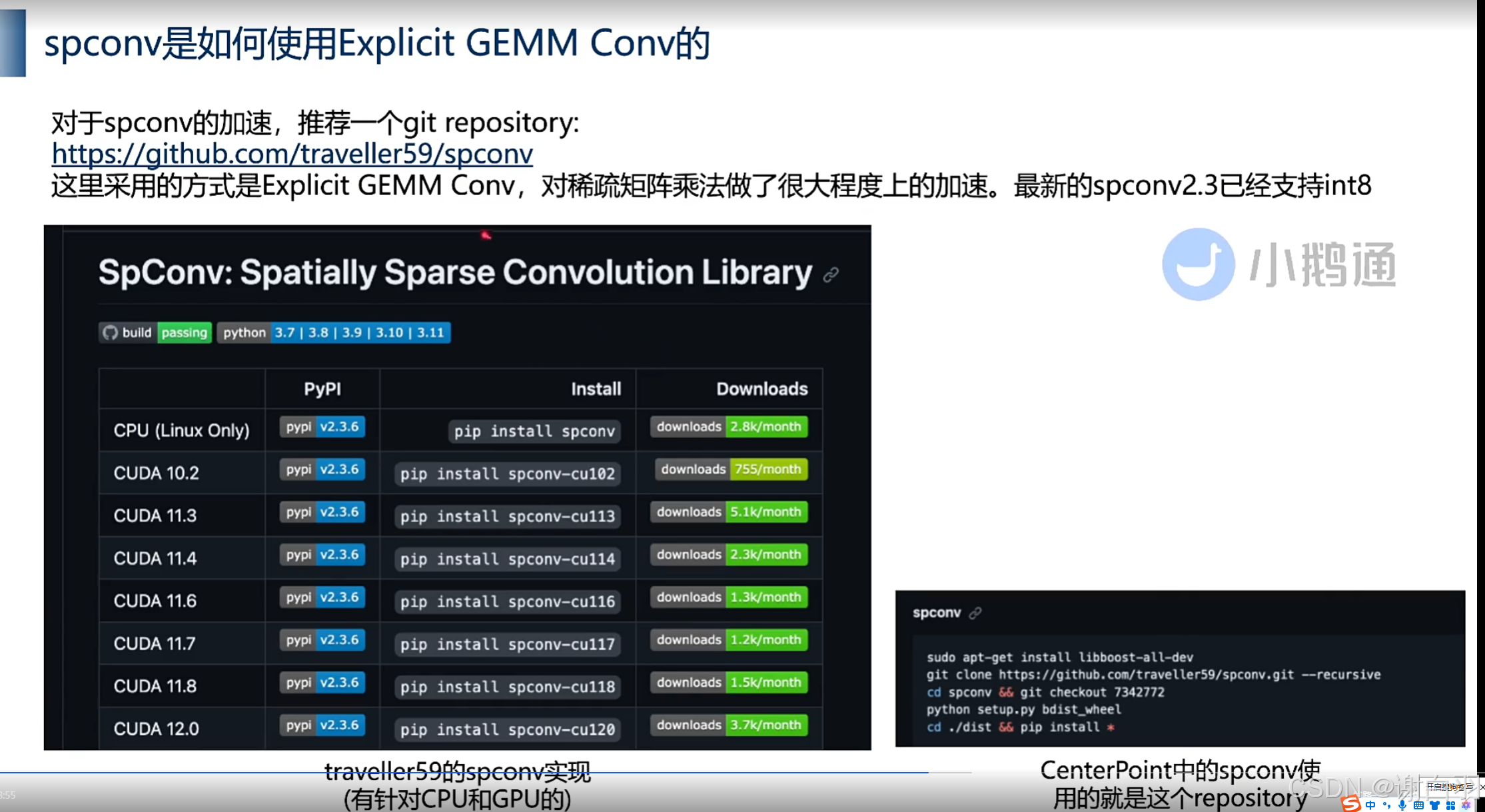
(2)具体实践开源项目
5)Spconv-with-Implicit-GEMM-Conv(隐形GEMM conv是怎么优化的)
- 学习目标
①理解隐形 GEMM Conv与显形 GEMM Conv的区别
②跳过im2col计算索引的方法
③理解Explicit GEMM Conv与spconv的关联性
(1)显性和隐性对比GEMM-conv的区别
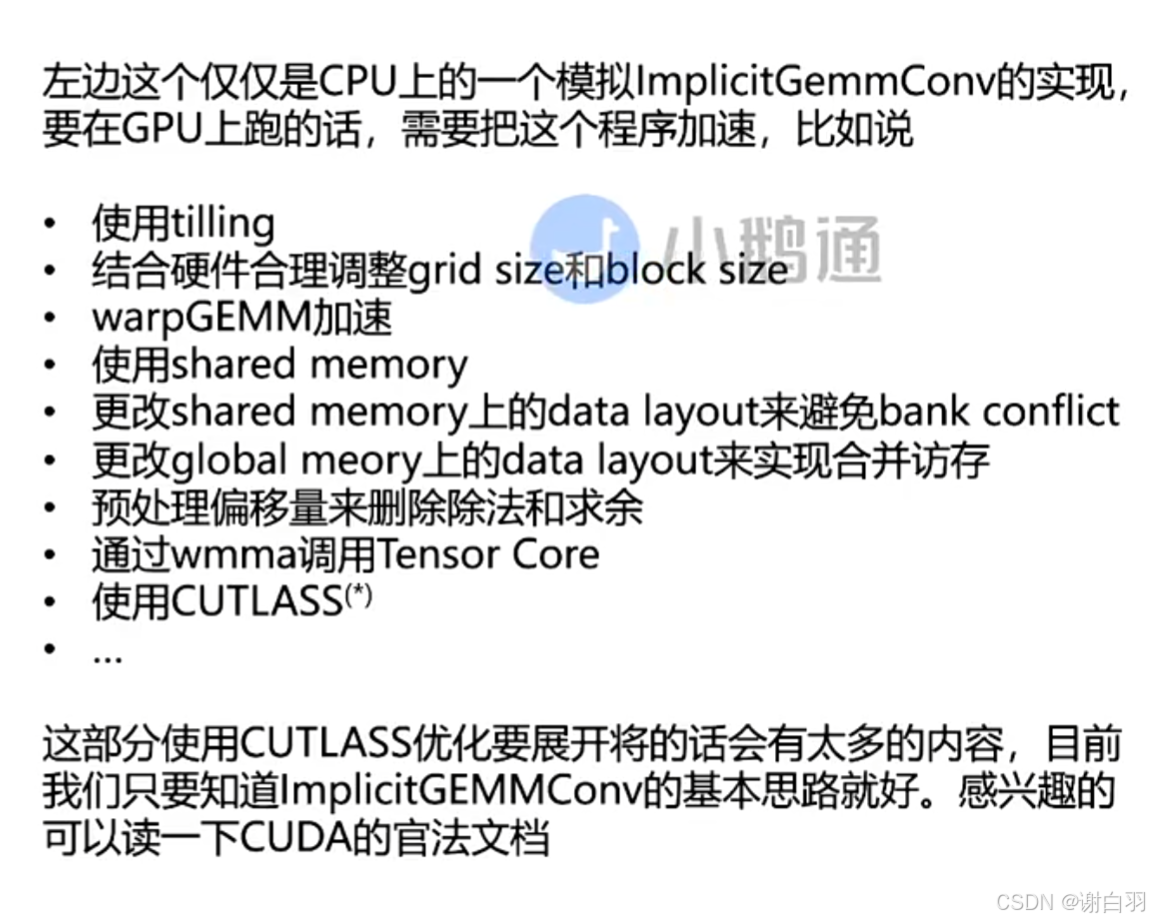
原因:显性GEMM会需要分配额外的空间,有一定的overhead
做法:知道对应关系作为索引就行。预先把数据global memory放到shared memory中做warp级别的加速。结合cutlass可以在Tensor core上实现高速GEMM计算

①回顾显性GEMM-Conv
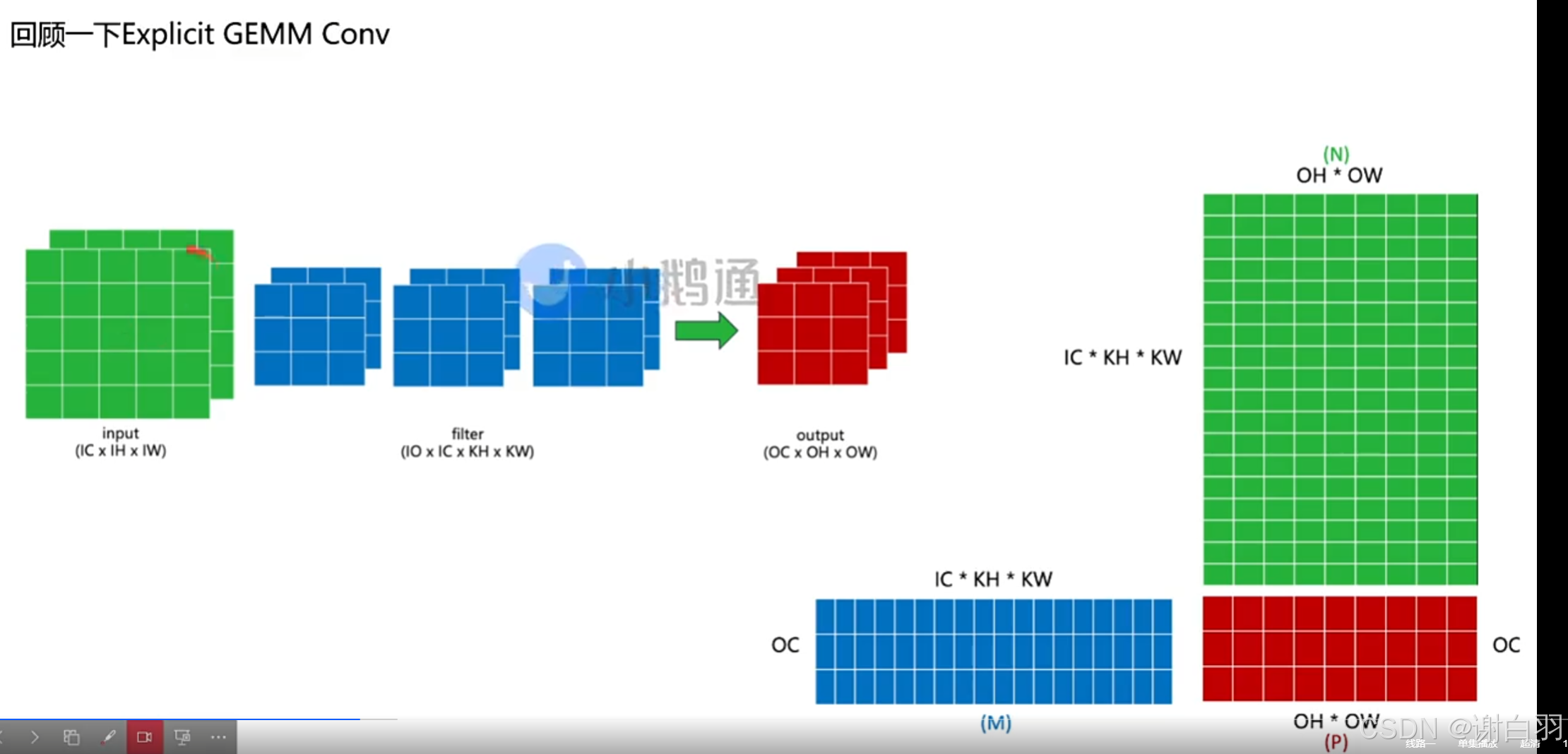

- 参数解释

- 得到的关系

filter的关系

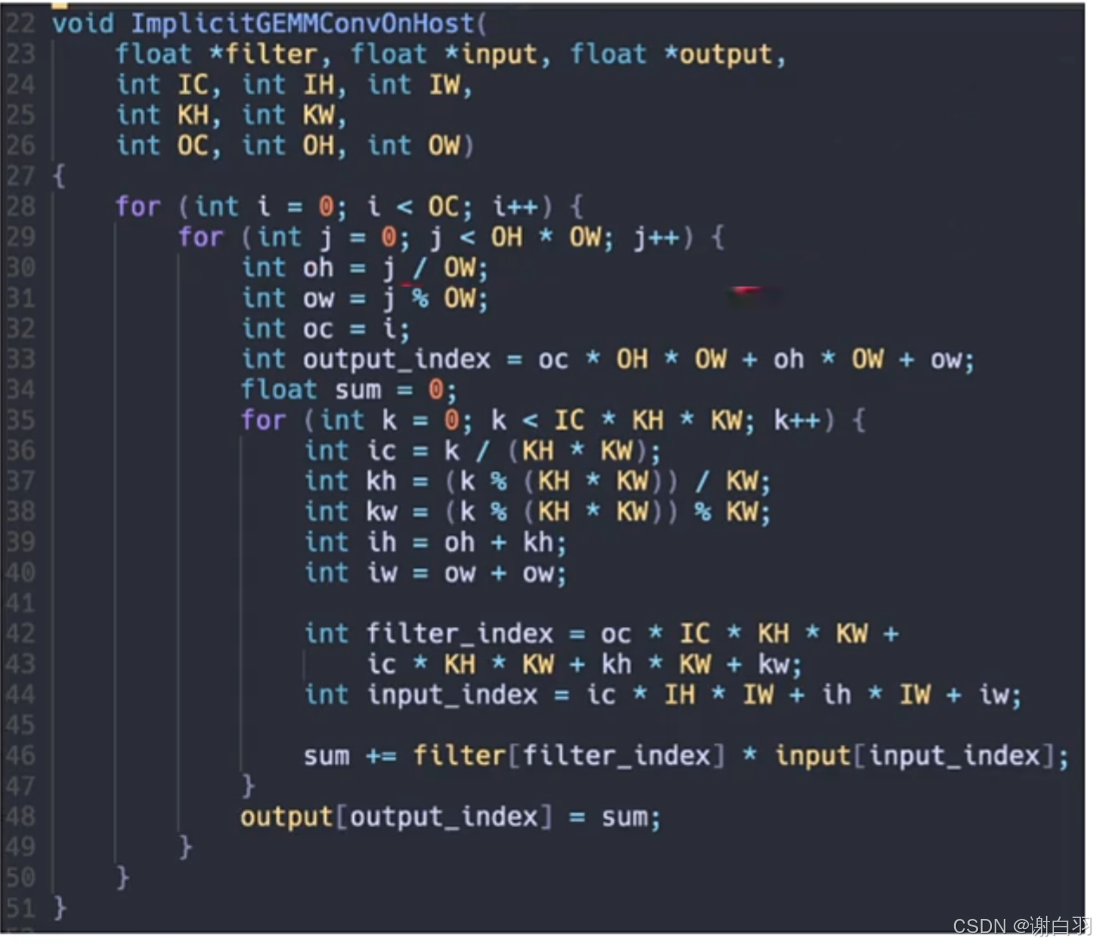
- 注意事项
(2)spconv也有用到Implicit GEMM Conv的方法

(3)Cutlass与implicit GEMM Conv
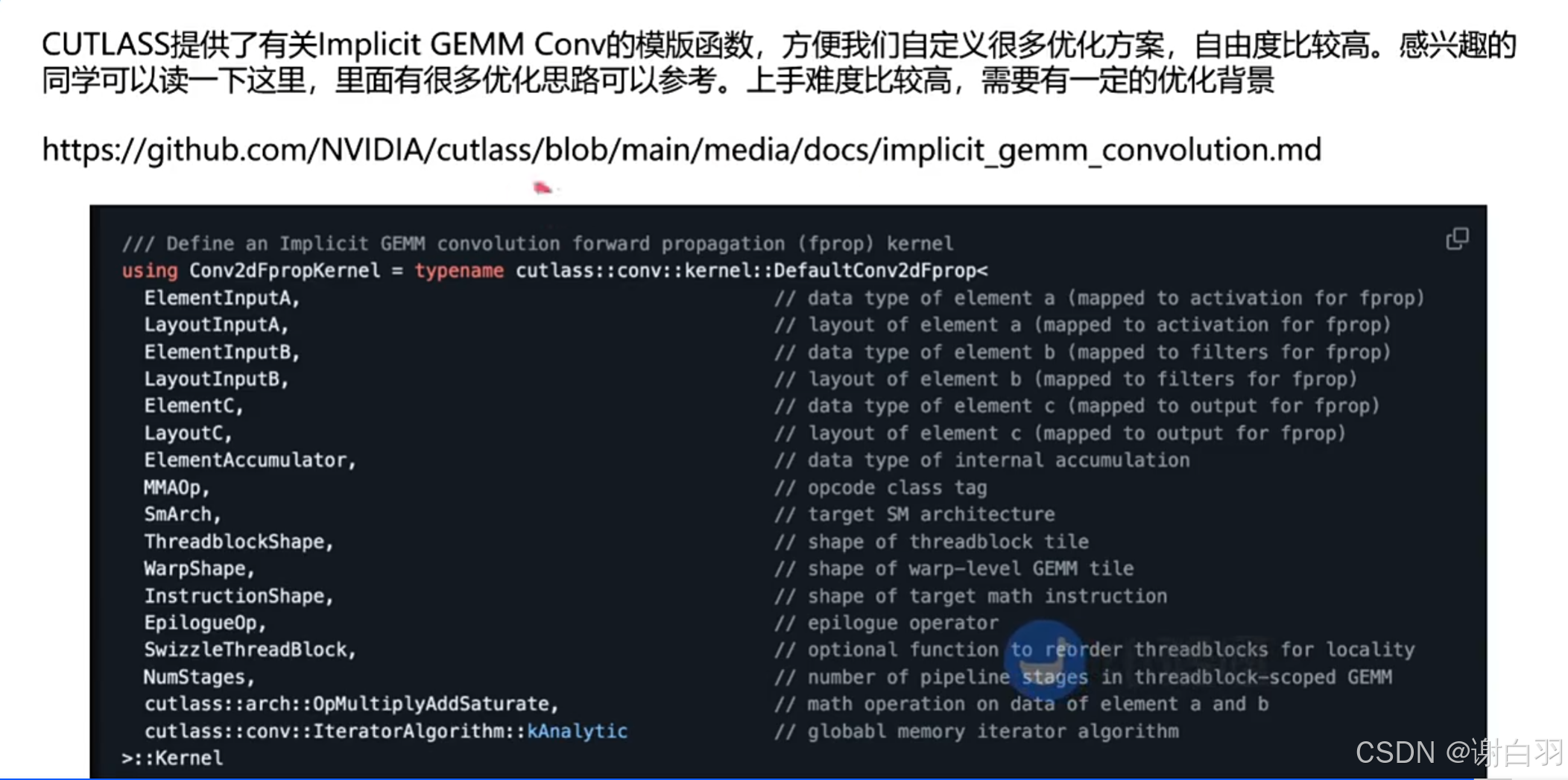
6)BEVPool-Optimization(学习BEVPool的优化方案)
- 学习目标
①学习BEVPool是什么
②LSS的2D到BEV的投影方法
③BEVFusion和CUDA-BEVFusion中对BEVPool的加速方法
(1)BEVpool介绍
- BEVPool流程
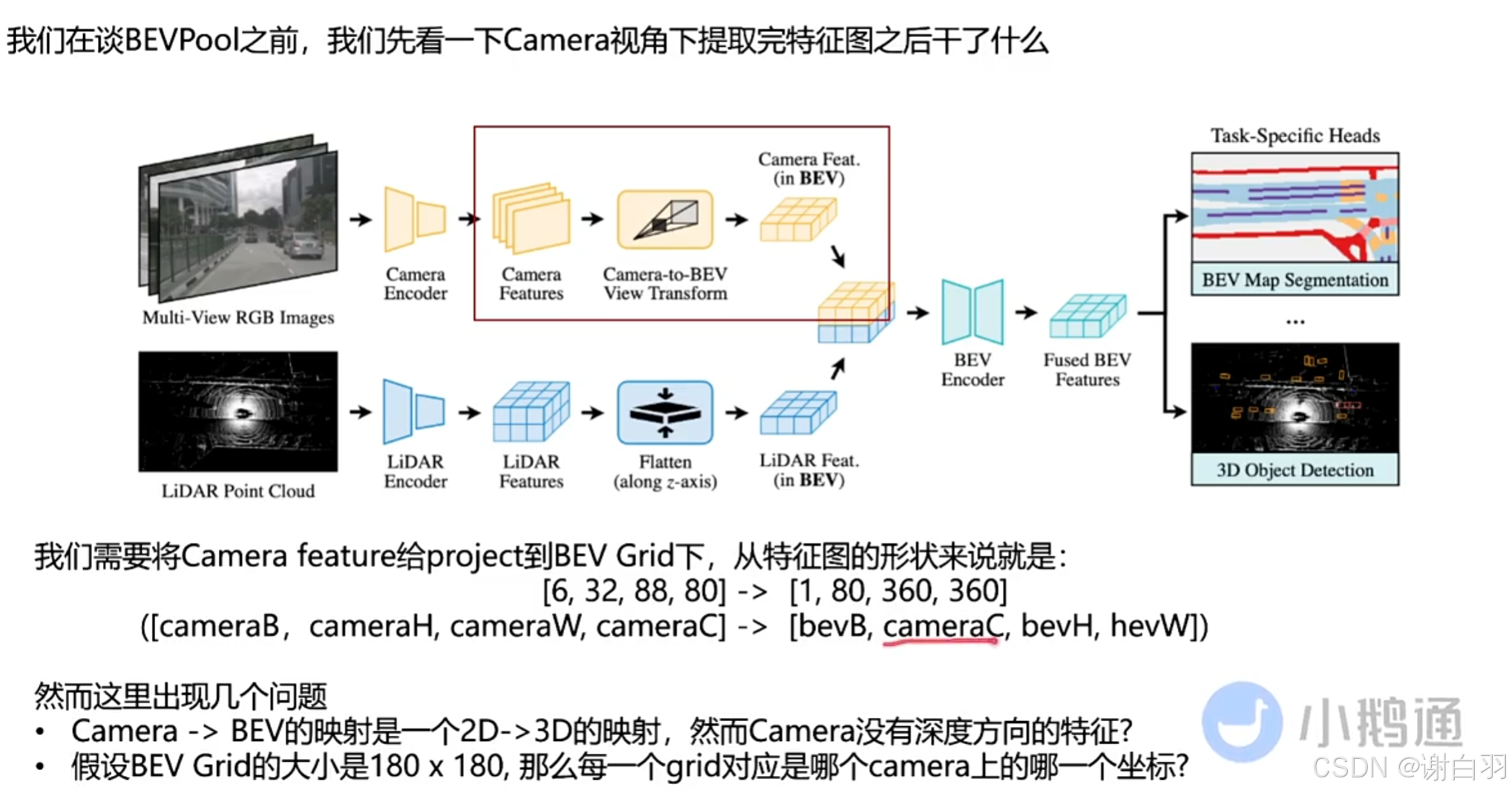
问题:
①camera没有深度方向特征
②每个grid对应camera坐标不清晰
(2)点击云生成介绍及投影介绍
-
深度方向做概率预测D个深度概率,然后把概率密度用softmax处理
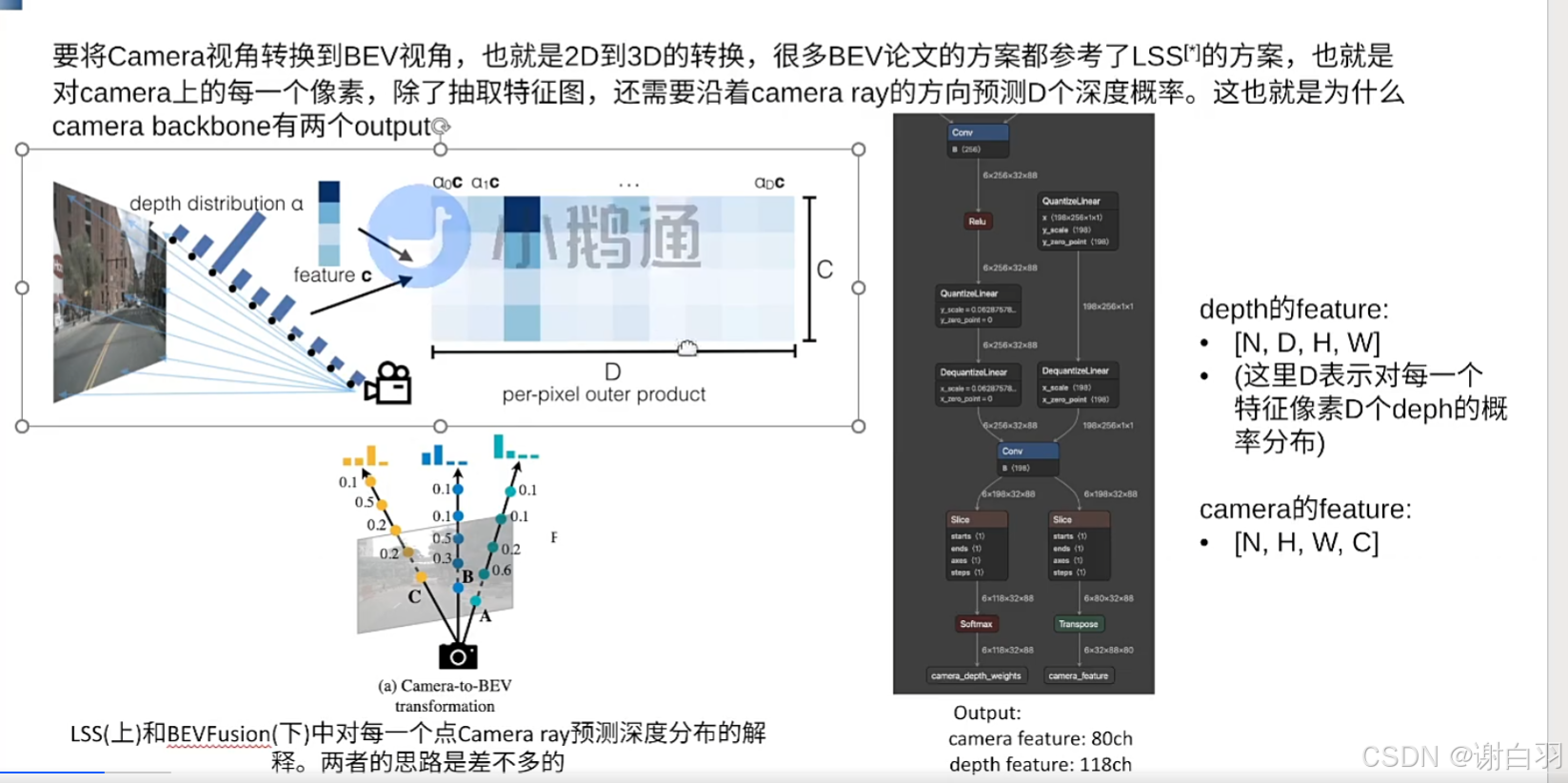
-
在camera方向上模拟预测点云的信息
-
投影介绍(多个点可能投影到同一个grid,然后同一个grid做相加)
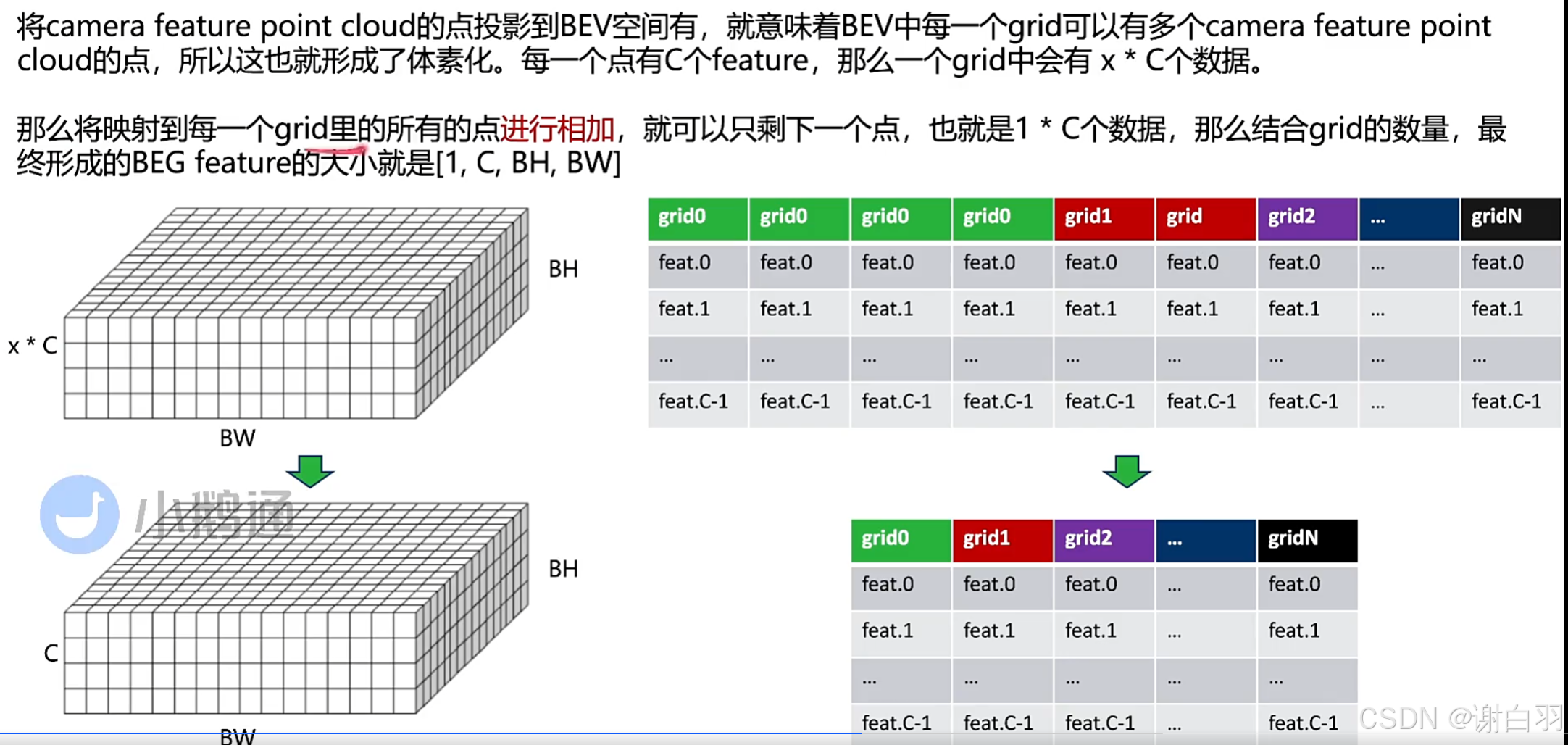
投影的方法可以通过相机内外参算出来
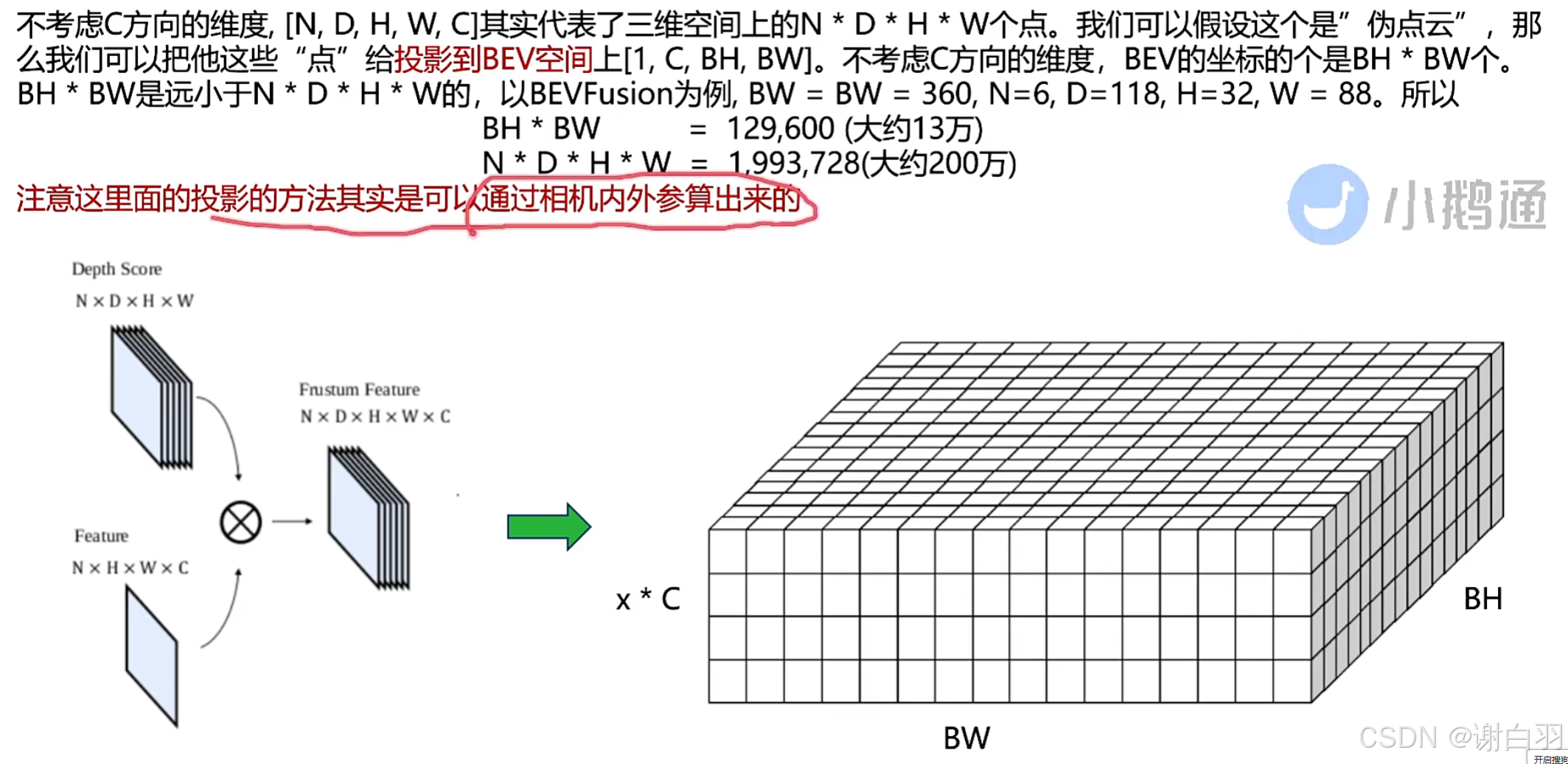
(3)BEVPool流程
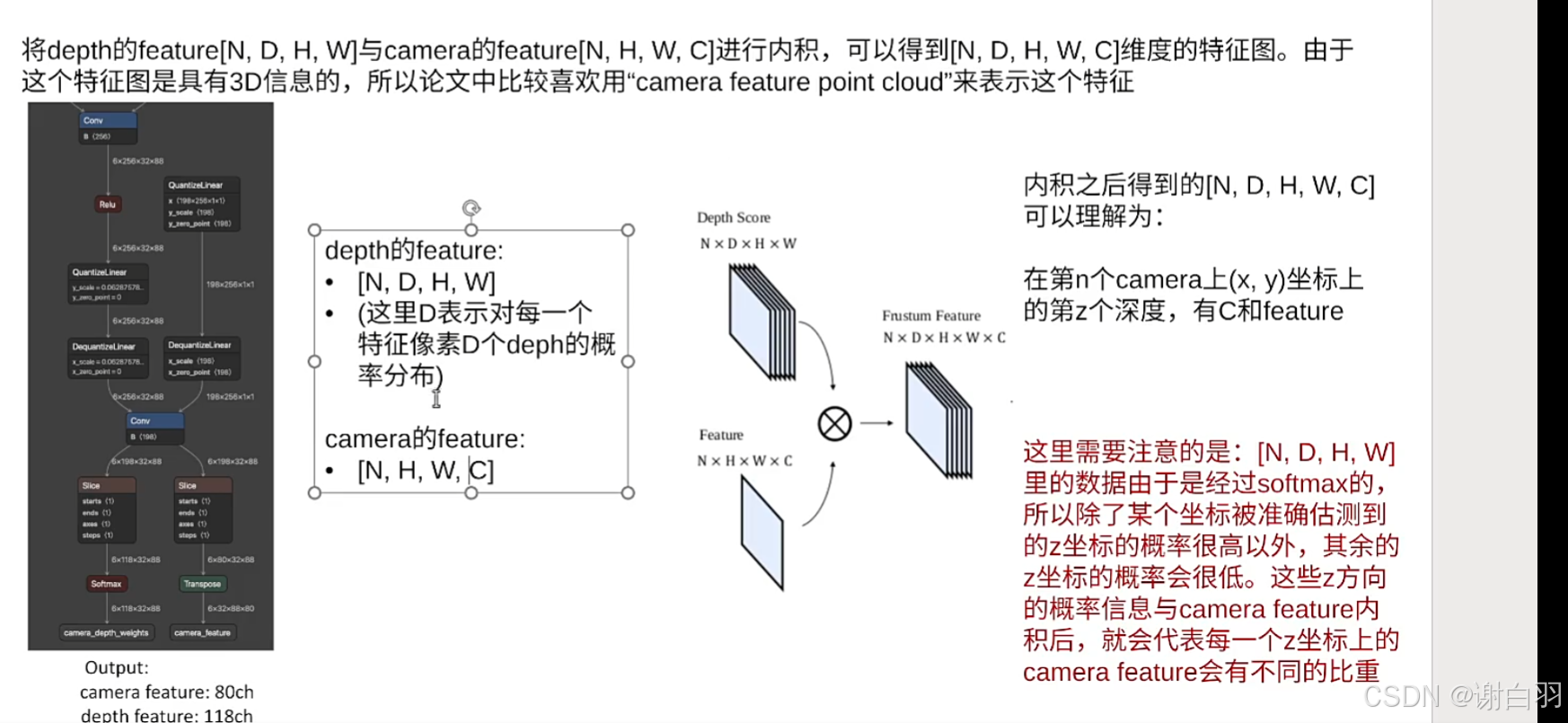
①将camera feature和depfeature内积,得到点阵云(camera feature point cloud)
②将camera feature point cloud里的所有点project到BEV grid(越界不投影)
③将同一个BEV gird里面所有点累加
④最终得到[1,C,BH,BW]维度的BEV feature,可以用于后续处理
- 计算点(这里指200W点)

(4)CUDA-BEVFusion针对BEV做的加速方法
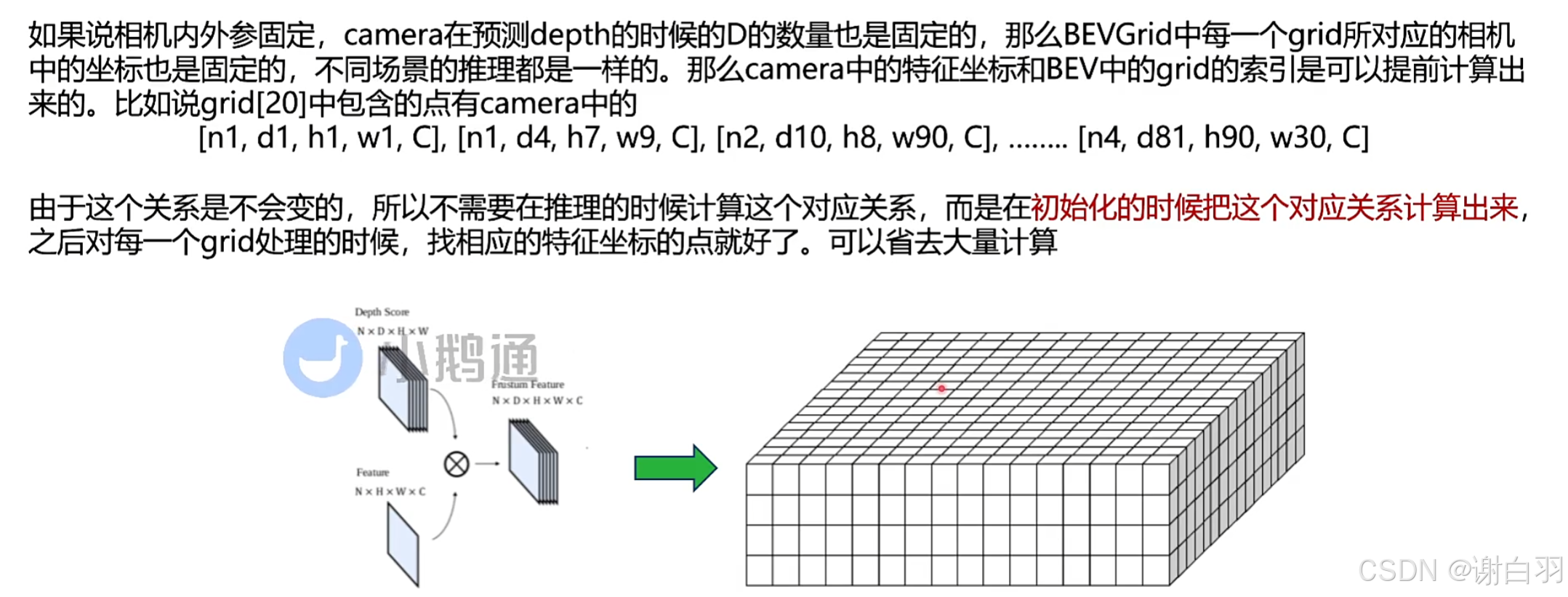
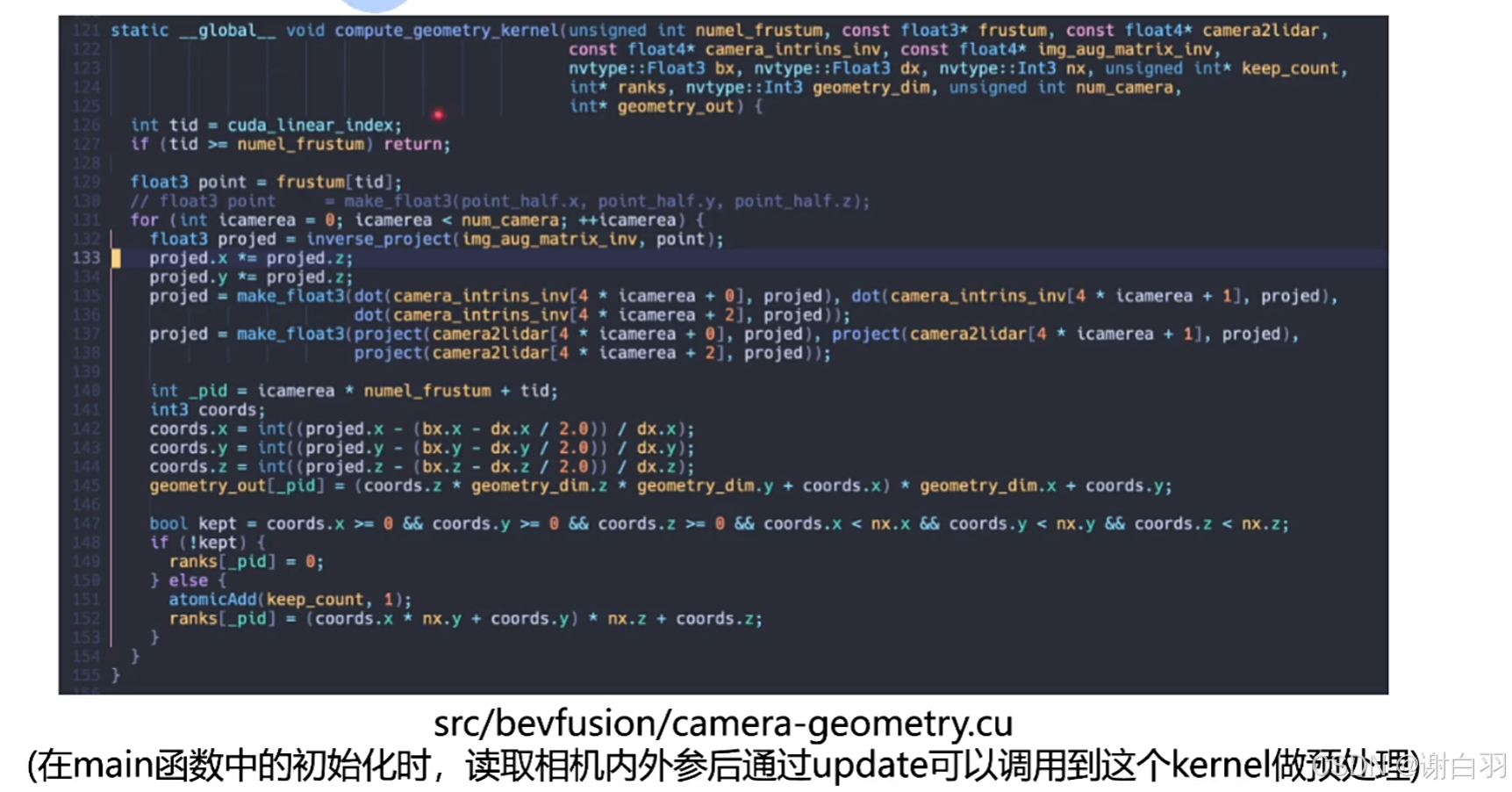
1)Precomputation(内外参固定,然后对应关系就可以算出来,初始化的时候做的预处理)
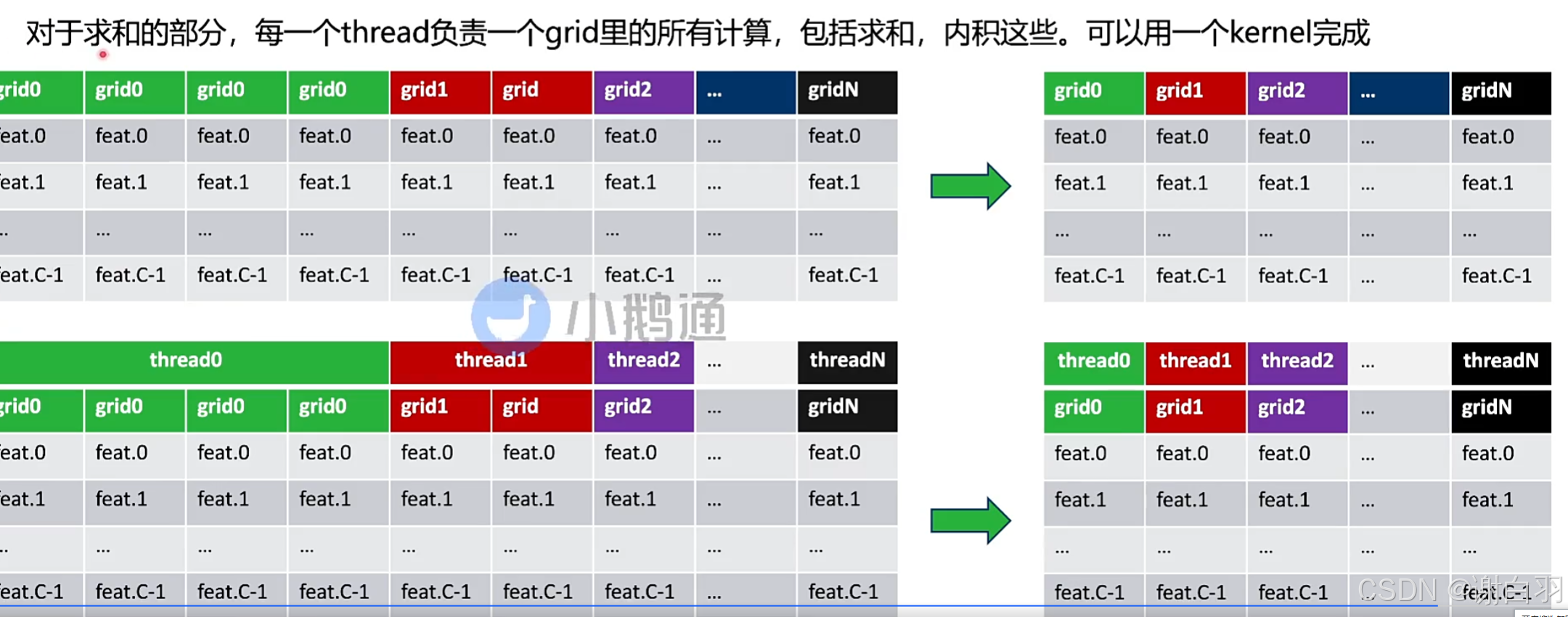
2)Interval Reduction(每一个thread负责一个grid的计算,包括求和还有内积)

7)Analyze-each-onnx(分析BEVFusion中各个onnx)
- 学习目标
①分析CUDA-BEVFusion中各个onnx的输入输出,以及网络架构
(1)模型目录文件介绍
-
项目model目录

-
包含的onnx和其他文件
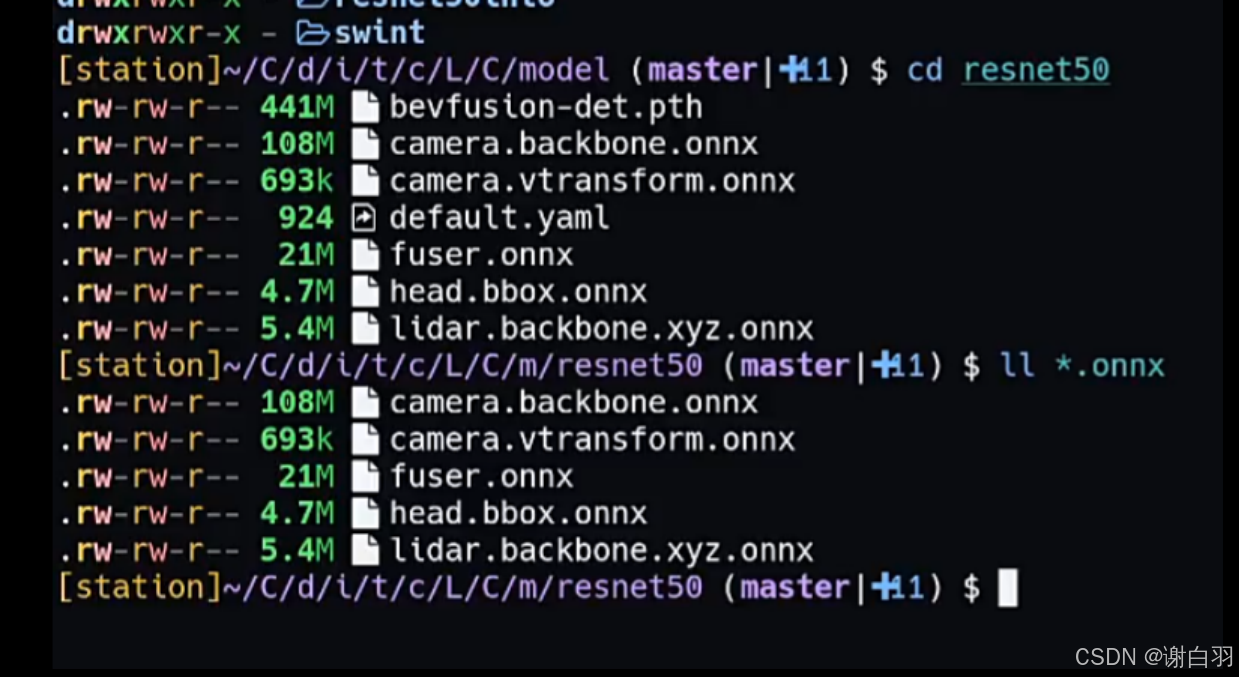
①camera.backbone.onnx:作为相机图像特征提取的骨干网络,用于对输入的相机图像数据进行初步的特征提取,提取出图像中的高级语义特征,为后续的处理提供基础。
②camera.vtransform.onnx:主要负责对相机图像进行视图变换,将相机坐标系下的图像特征投影project到BEV(鸟瞰图)坐标系下,使得不同视角的图像特征能够在统一的坐标系中进行融合和处理。
③fuser.onnx:承担着将相机图像特征和激光雷达点云特征进行融合的任务,通过特定的融合算法,将两种不同传感器的特征进行有效融合,充分利用多传感器信息,提高目标检测和感知的准确性。
④head.bbox.onnx:用于对融合后的特征进行目标检测和边界框回归,根据特征信息预测出目标物体的位置和类别,并生成相应的边界框,为后续的任务提供目标位置和类别信息。
⑤lidar.backbone.xyz.onn:针对激光雷达点云数据进行特征提取,提取出点云数据中的空间结构和语义特征,为与相机图像特征的融合以及后续的目标检测等任务提供点云方面的特征支持。
⑥bevfusion-det.pth:它存储了经过训练的BEVFusion检测模型的参数。在模型训练过程中,模型的权重等参数会不断调整和优化,训练完成后,这些最优参数会被保存下来以便后续使用。
⑦default.yaml:用于存储BEVFusion模型的各种配置参数,如模型结构相关参数、训练和推理过程中的超参数等。例如,它可能包含输入数据的格式和预处理方式、模型的层数和卷积核大小、训练的学习率、批次大小、迭代次数等
(2)各个onnx分析
(1)camera.backbone.onnx
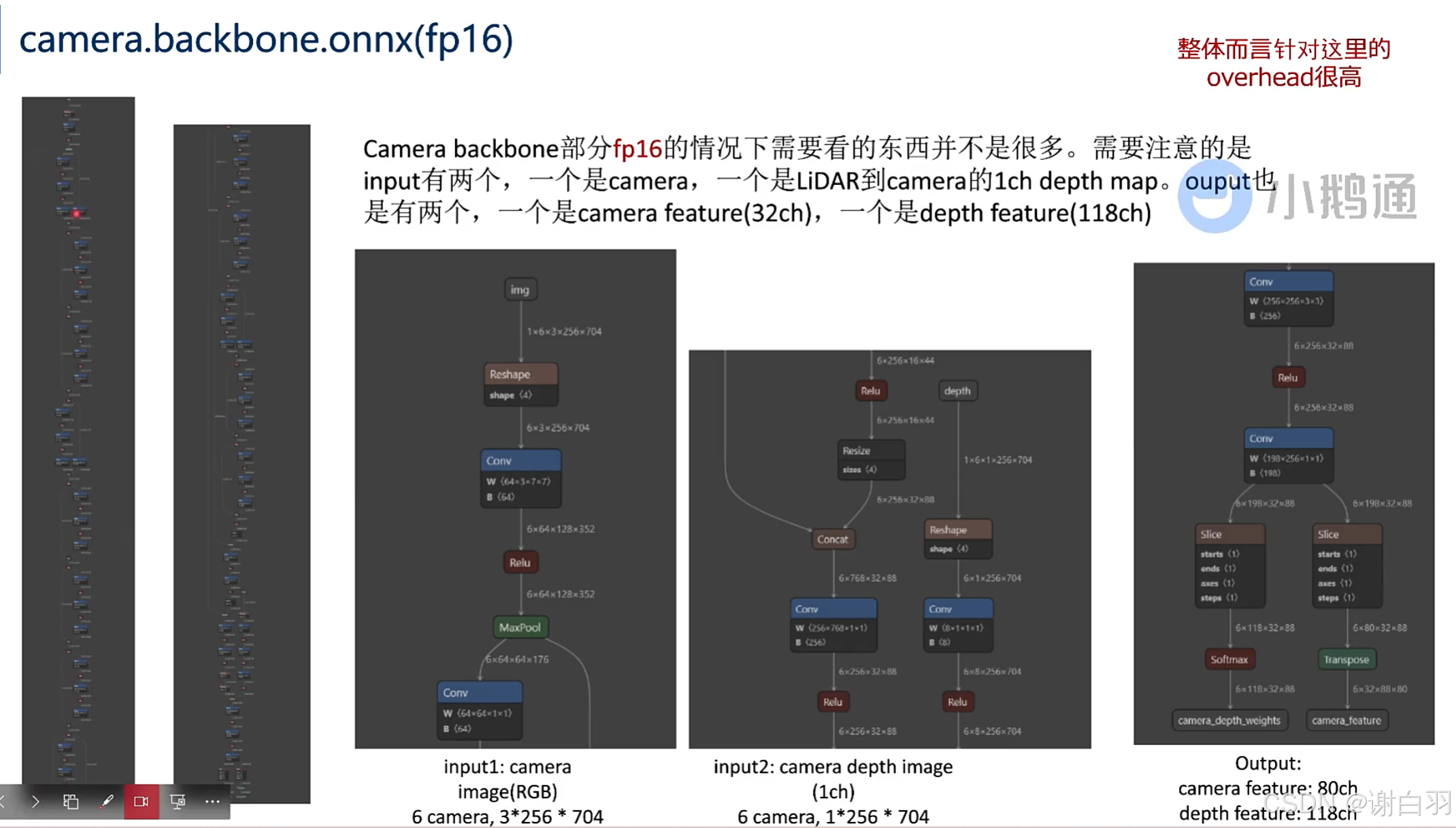
输入:①camera;②camera.vtransform.onnx的输出信息,也就是点阵云投影的坐标信息,预估距离,最后用softmax排序
输出:①可以给fuser.onnx融合的摄像机特征和点阵云特征
- int8量化版本(增加了QDQ节点)
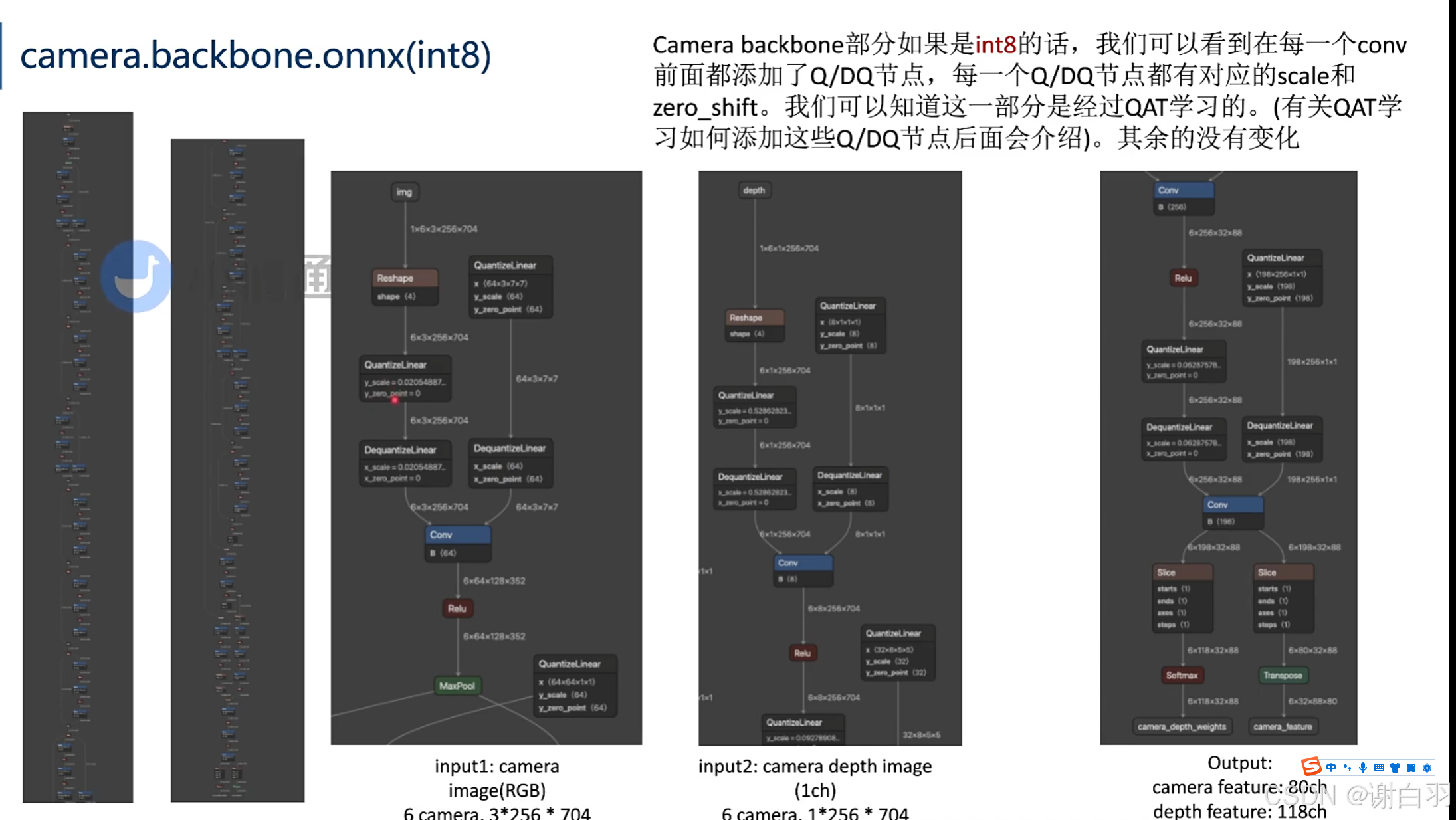
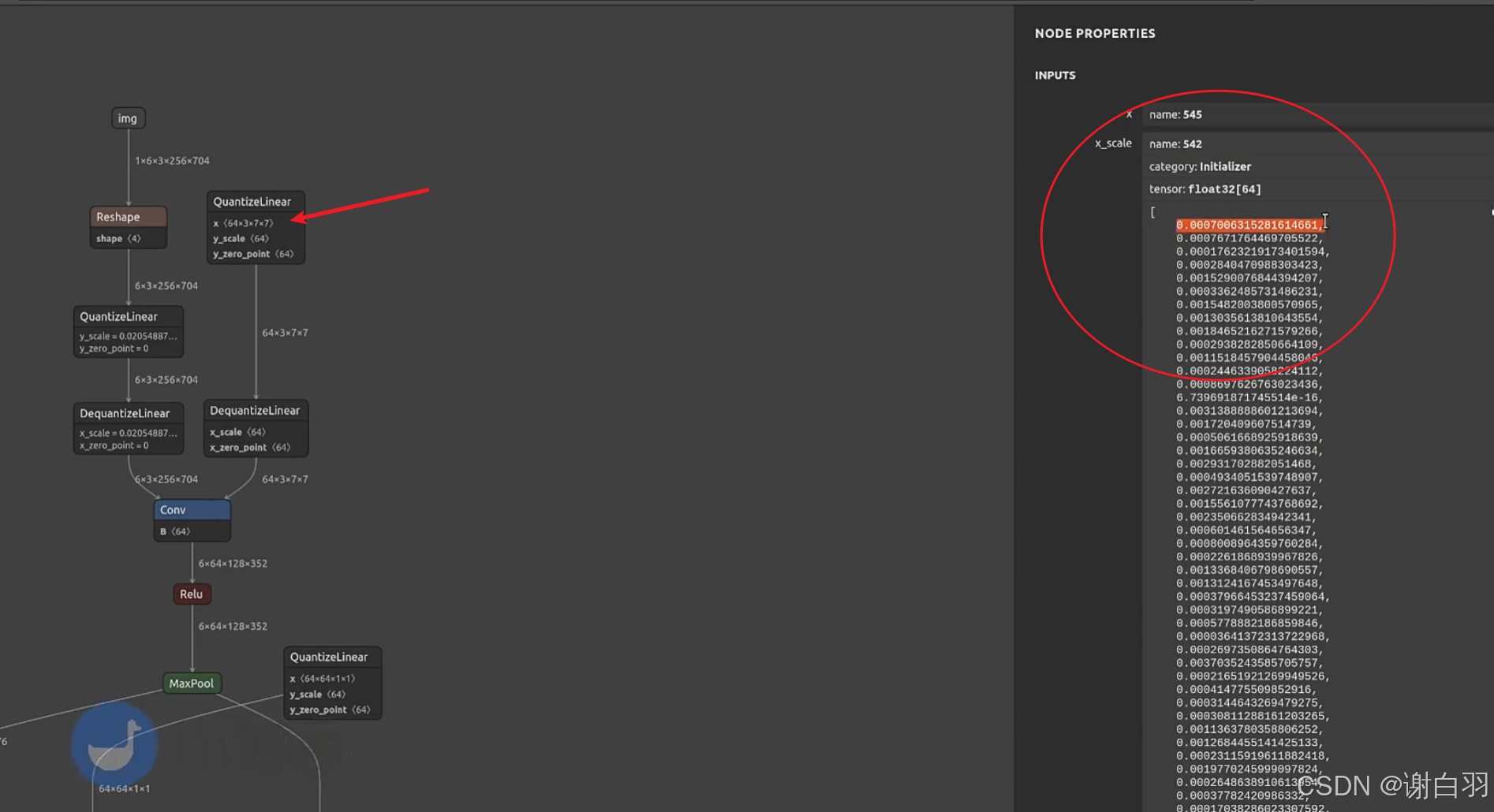
- 特点
①每一个Conv之前都有QDQ节点
②右边QDQ是weight权重,是per-channel的,是64个channel,每个channel都有自己的scale
③左边是输出,per-tensor级别的
(2)camera.vtransform.onnx

(3)fuser.onnx
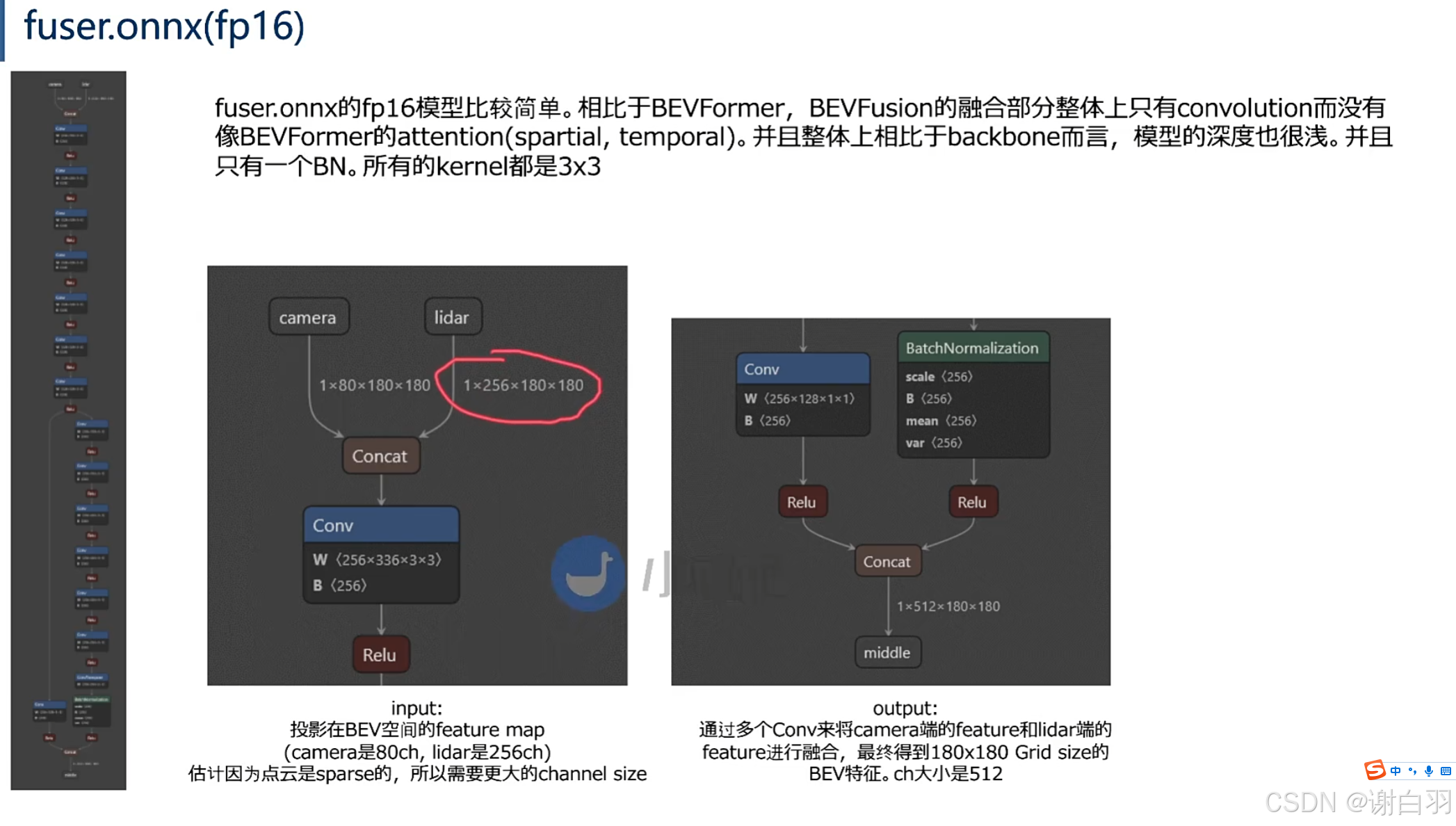
(4)head.bbox.onnx

score:各个物体,比如人体、汽车等的分类信心
(5)lidar.backbone.xyz.onn
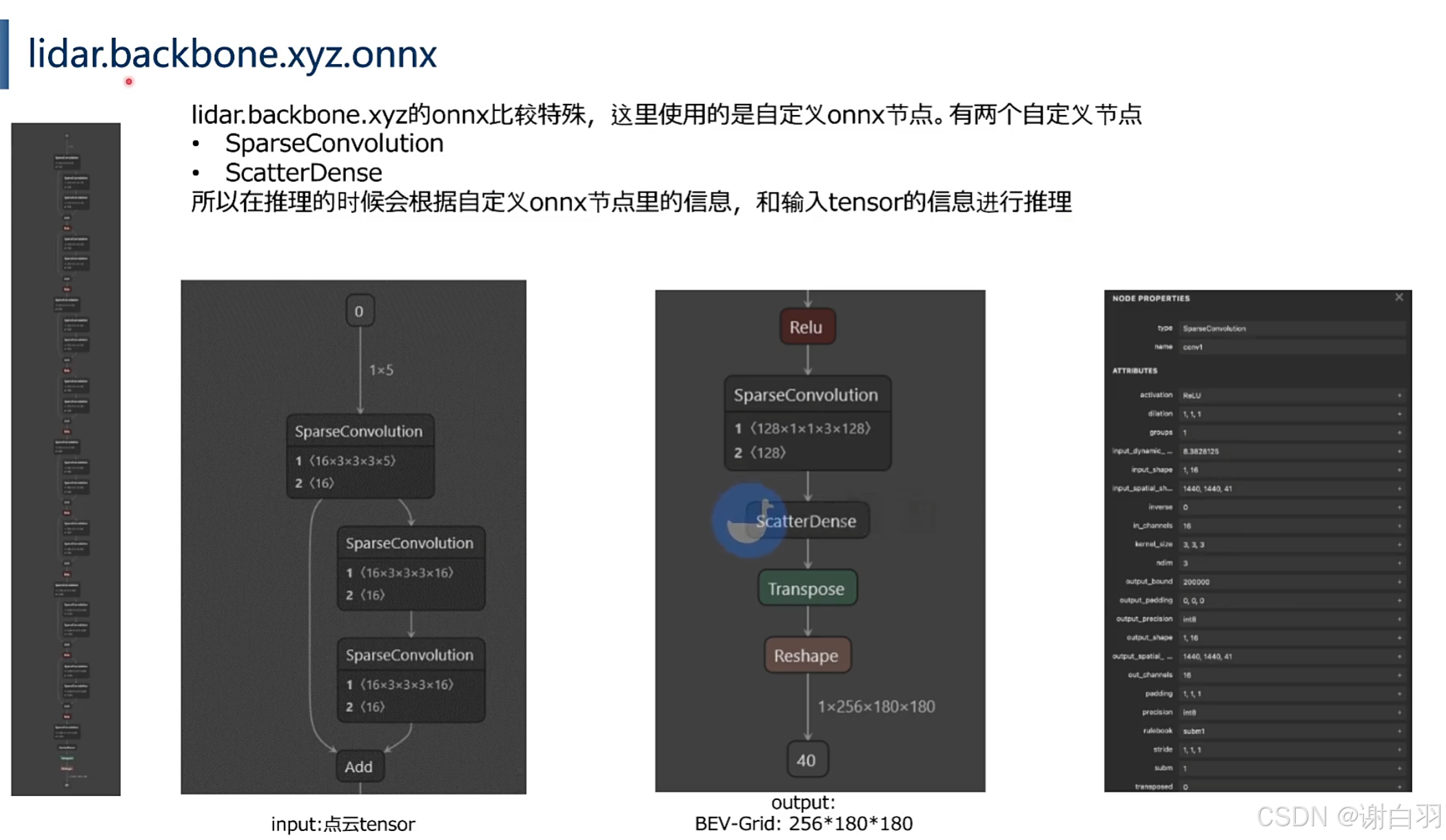
8)CUDA-BEVusion-Framework-Design(推理框架设计模式)
- 学习目标
①理解大项目C++推理框架阅读代码的技巧
②cuda-bevfusion中的设计模式
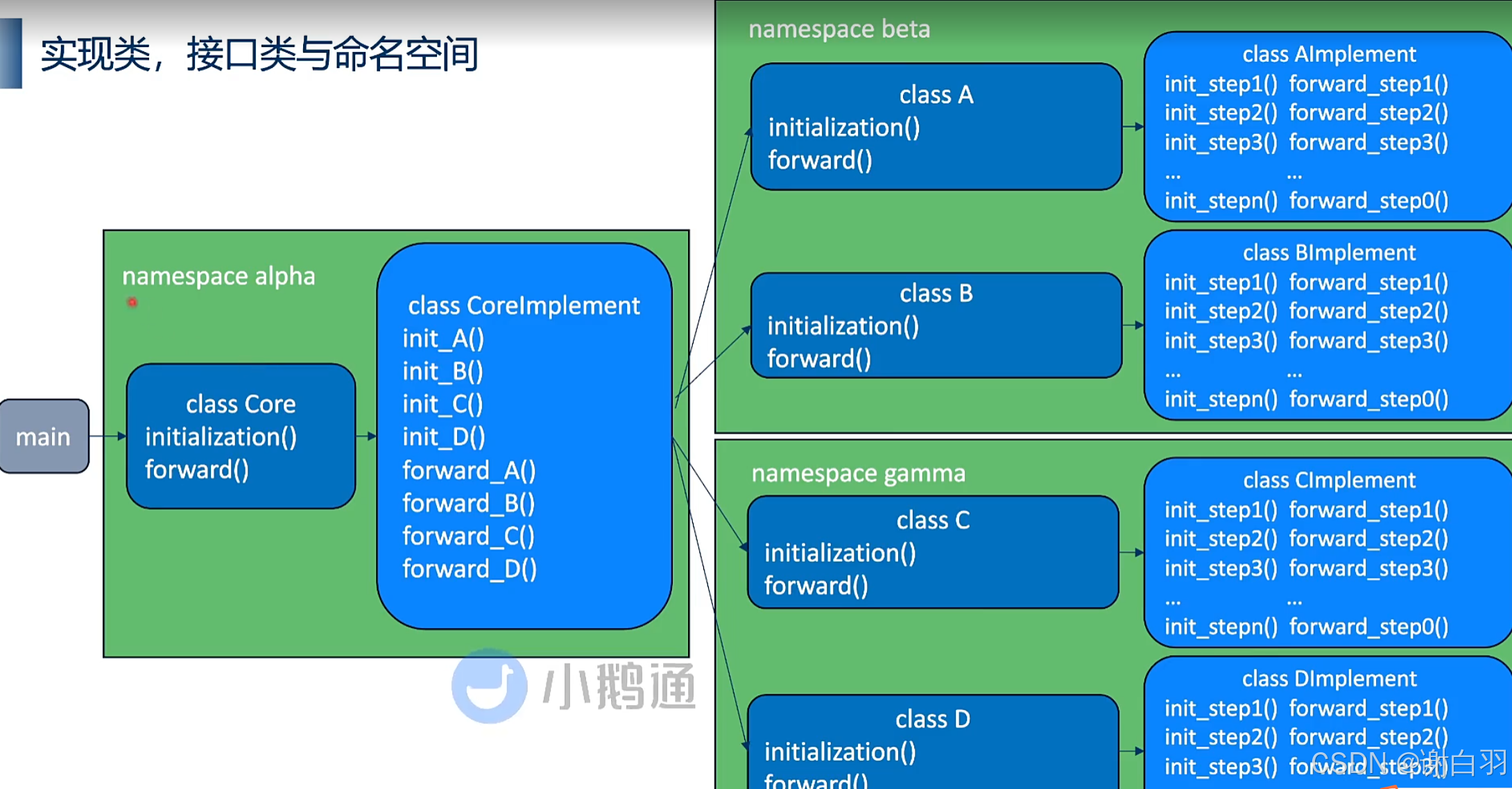
③命名空间/接口类/实现类的设计用意
实现类是接口类的子类
(1)BEVFusion接口类
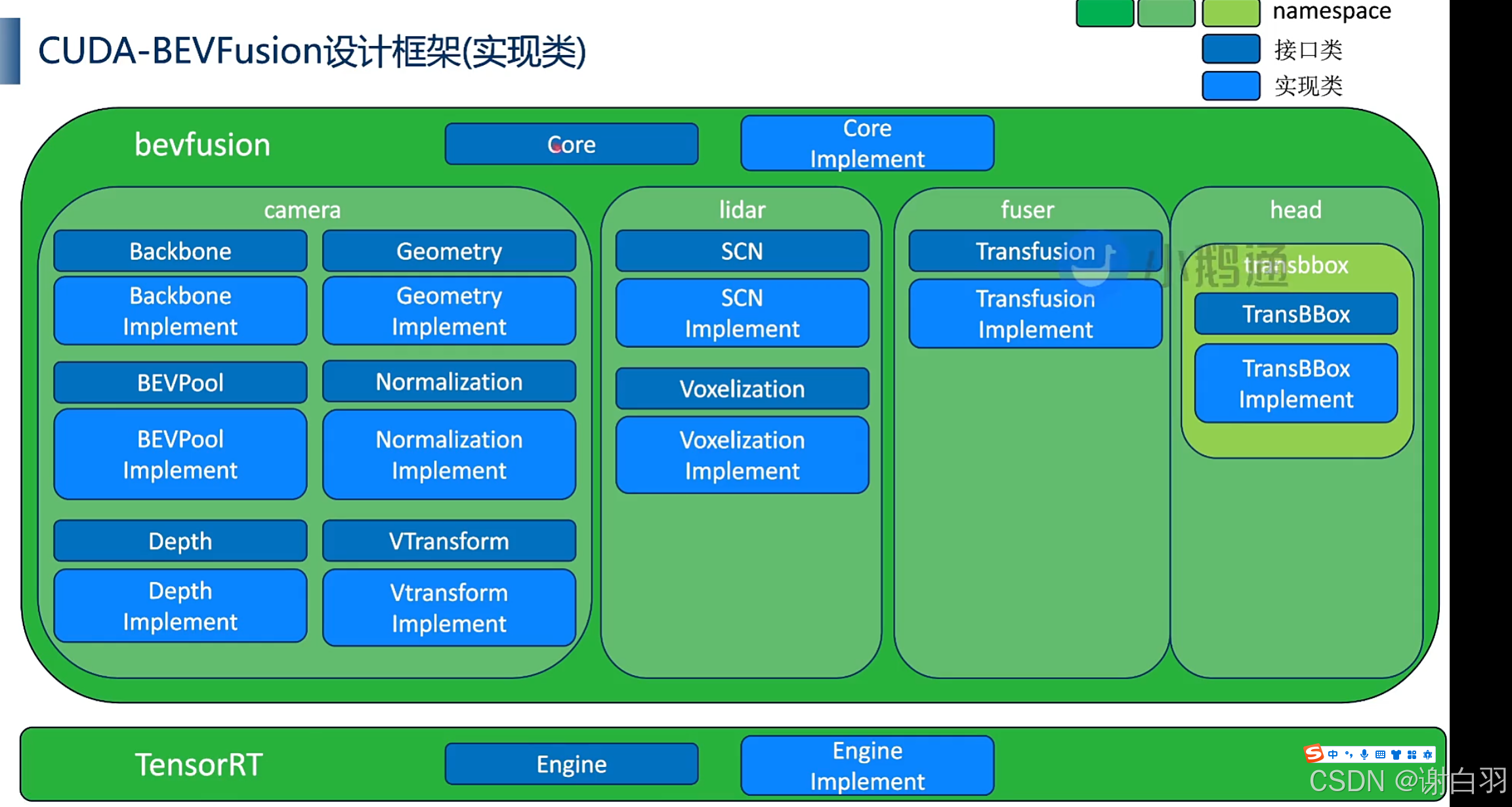
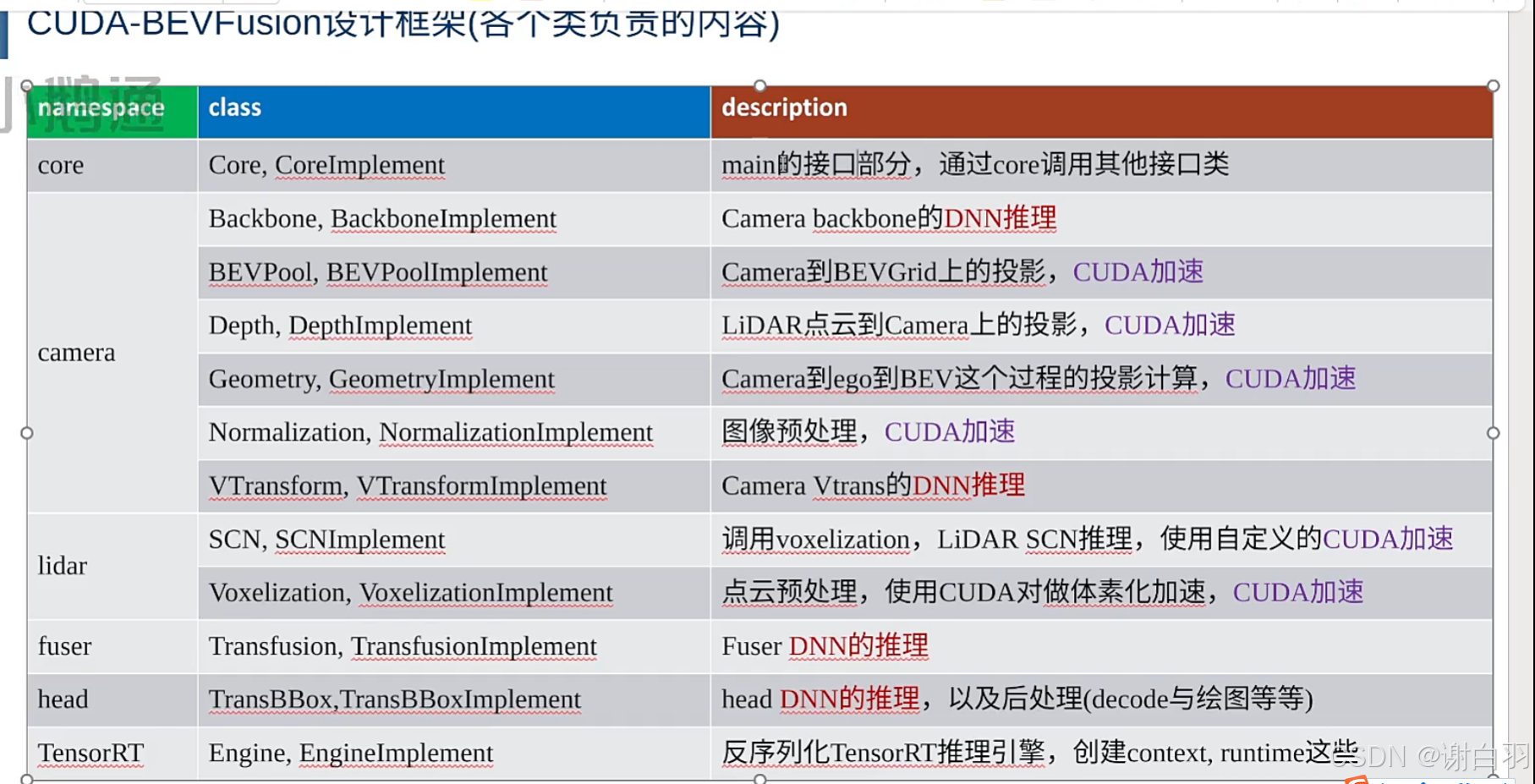
①camera的backbone DNN加速是tensorRT加速
②camera到BEVGrid上的投影是cuda核函数加速
- 接口具体调用
①init初始化
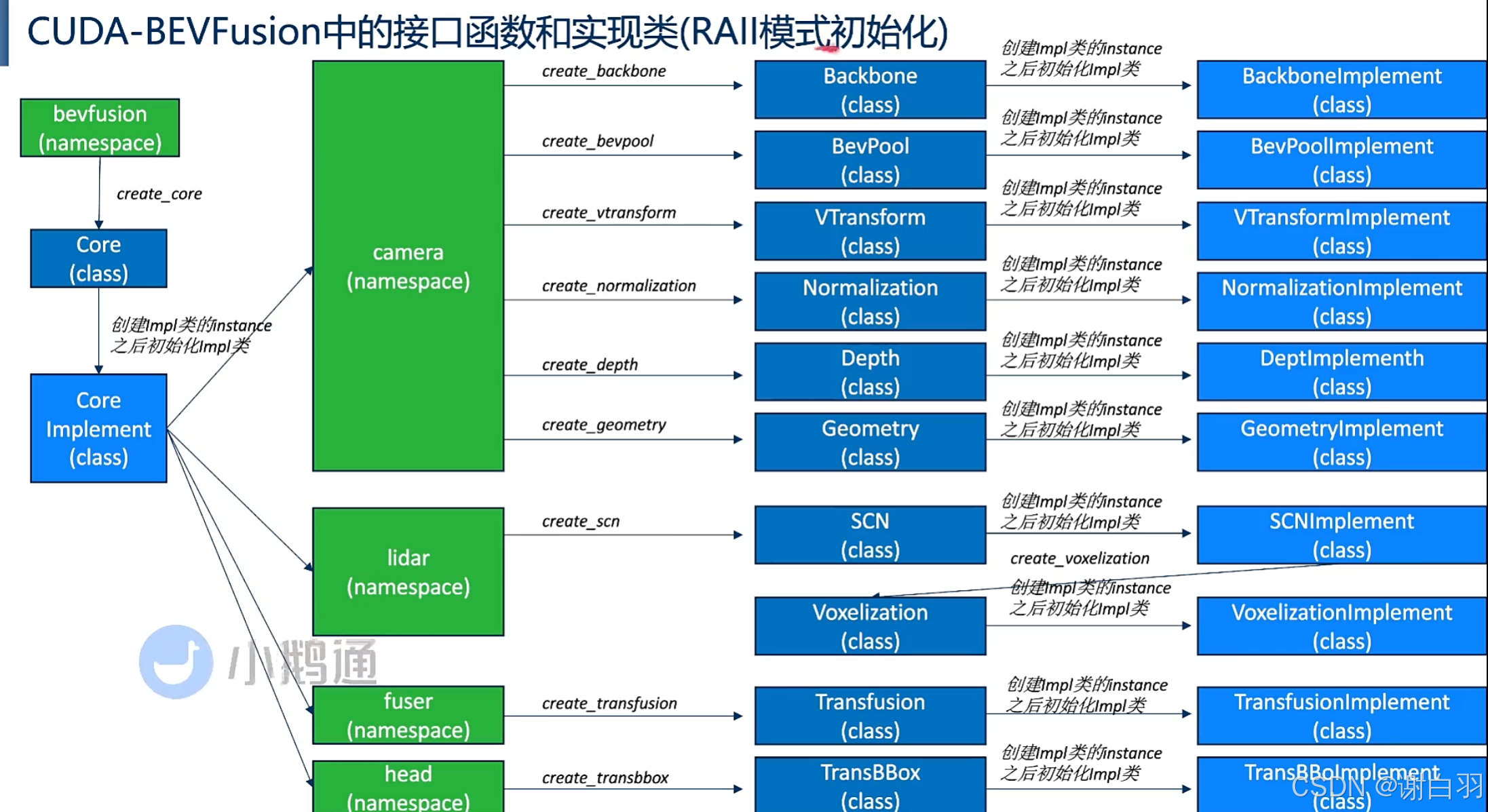
②接口类
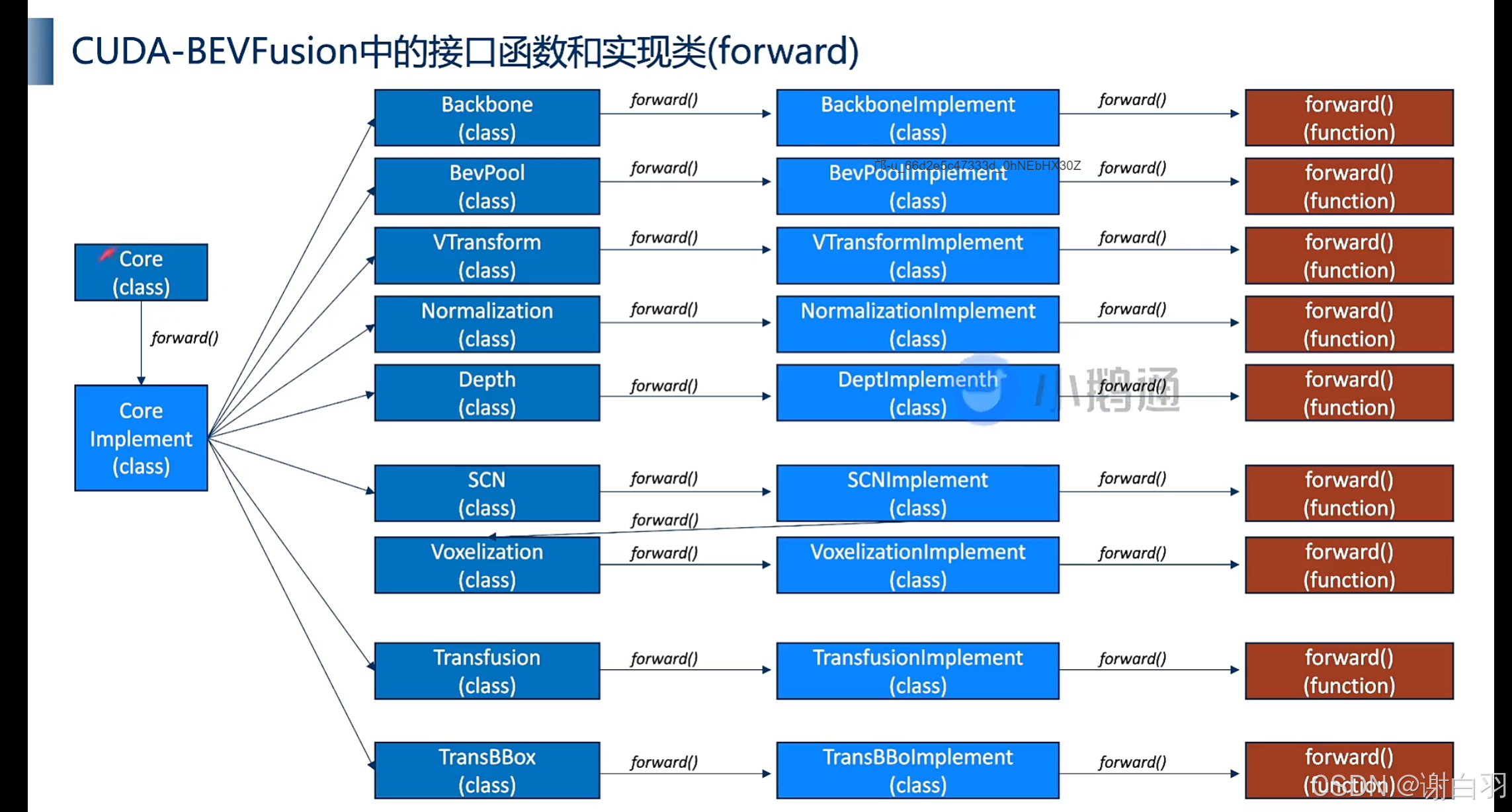
前向推导
9)BEVFusion initialization
- 步骤
①运行程序
②main函数主要步骤
(1)运行程序

(2)main函数步骤
①做一些DNN和cuda加速部分的初始化工作

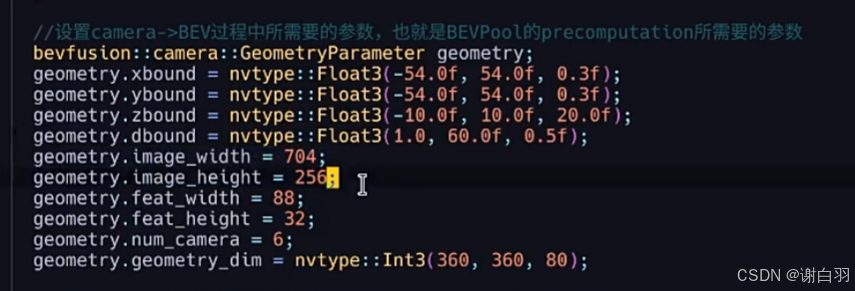
②设置一些camera的参数
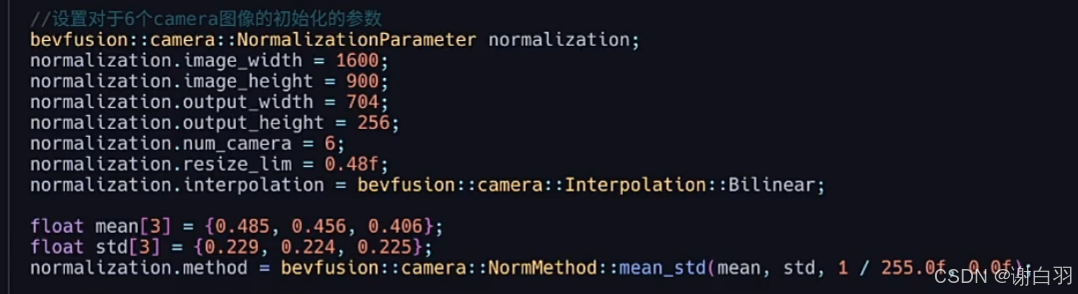
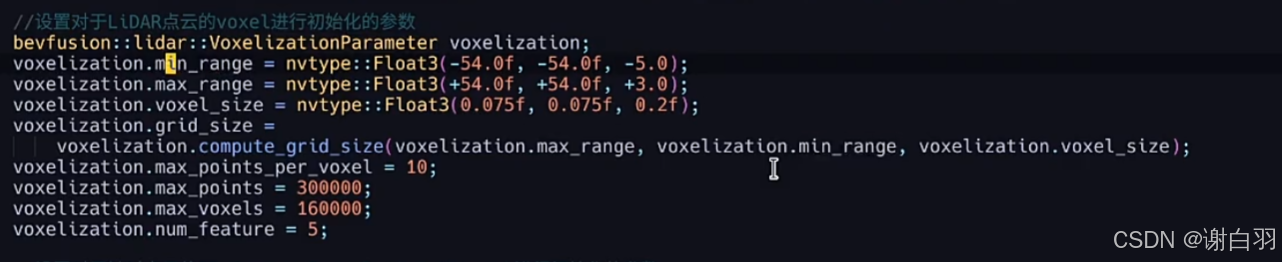
③设置Lidar点云的voxel进行初始化的参数
④bevpool的precomputation提前记录好坐标的映射关系,能有效提高时间
bevpool其实就2点:一是precomputation,二是interval reduction(推理的时候做的)
- 代码
int main(int argc, char** argv) {
const char* data = "example-data";
const char* model = "resnet50int8";
const char* precision = "int8";
if (argc > 1) data = argv[1];
if (argc > 2) model = argv[2];
if (argc > 3) precision = argv[3];
dlopen("libcustom_layernorm.so", RTLD_NOW);
auto core = create_core(model, precision);
if (core == nullptr) {
printf("Core has been failed.\n");
return -1;
}
cudaStream_t stream;
cudaStreamCreate(&stream);
core->print();
core->set_timer(true);
// Load matrix to host
auto camera2lidar = nv::Tensor::load(nv::format("%s/camera2lidar.tensor", data), false);
auto camera_intrinsics = nv::Tensor::load(nv::format("%s/camera_intrinsics.tensor", data), false);
auto lidar2image = nv::Tensor::load(nv::format("%s/lidar2image.tensor", data), false);
auto img_aug_matrix = nv::Tensor::load(nv::format("%s/img_aug_matrix.tensor", data), false);
core->update(camera2lidar.ptr<float>(), camera_intrinsics.ptr<float>(), lidar2image.ptr<float>(), img_aug_matrix.ptr<float>(),
stream);
// core->free_excess_memory();
// Load image and lidar to host
auto images = load_images(data);
auto lidar_points = nv::Tensor::load(nv::format("%s/points.tensor", data), false);
// warmup
auto bboxes =
core->forward((const unsigned char**)images.data(), lidar_points.ptr<nvtype::half>(), lidar_points.size(0), stream);
// evaluate inference time
for (int i = 0; i < 5; ++i) {
core->forward((const unsigned char**)images.data(), lidar_points.ptr<nvtype::half>(), lidar_points.size(0), stream);
}
// visualize and save to jpg
visualize(bboxes, lidar_points, images, lidar2image, "build/cuda-bevfusion.jpg", stream);
// destroy memory
free_images(images);
checkRuntime(cudaStreamDestroy(stream));
printf("[Warning]: If you got an inaccurate boundingbox result please turn on the layernormplugin plan. (main.cpp:207)\n");
return 0;
}

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









