




原题出处:Lambda OJ 201804
问题描述
随着科技的发展,通信的手段日新月异。然而不得不说,至今都没有比鸿雁传书更为深情浪漫的通信方式出现。
两个迷恋地球文明&中华文化的【三体人】出于浪漫主义需求,决定以后通过鸿雁传书的方式来进行通信。为了方便起见,我们姑且叫他们大刘和大白。鸿雁传书,情真意切,大刘和大白的感情也一日比一日深厚。
两人的私密通信,自然是“不足为外人道”的。为此大刘煞费苦心地设计了一套用01比特来表示每个三体文字的方式,称为“鸿雁传书字典”。其巧妙之处在于,任何一个01比特串都不会是其他串的前缀串。于是收到一大堆01比特的大白对照着“鸿雁传书字典”,就能原样知道大刘想写的是什么三体文字了。而别人手中没有这个字典,自然不知道这些比特的含义。
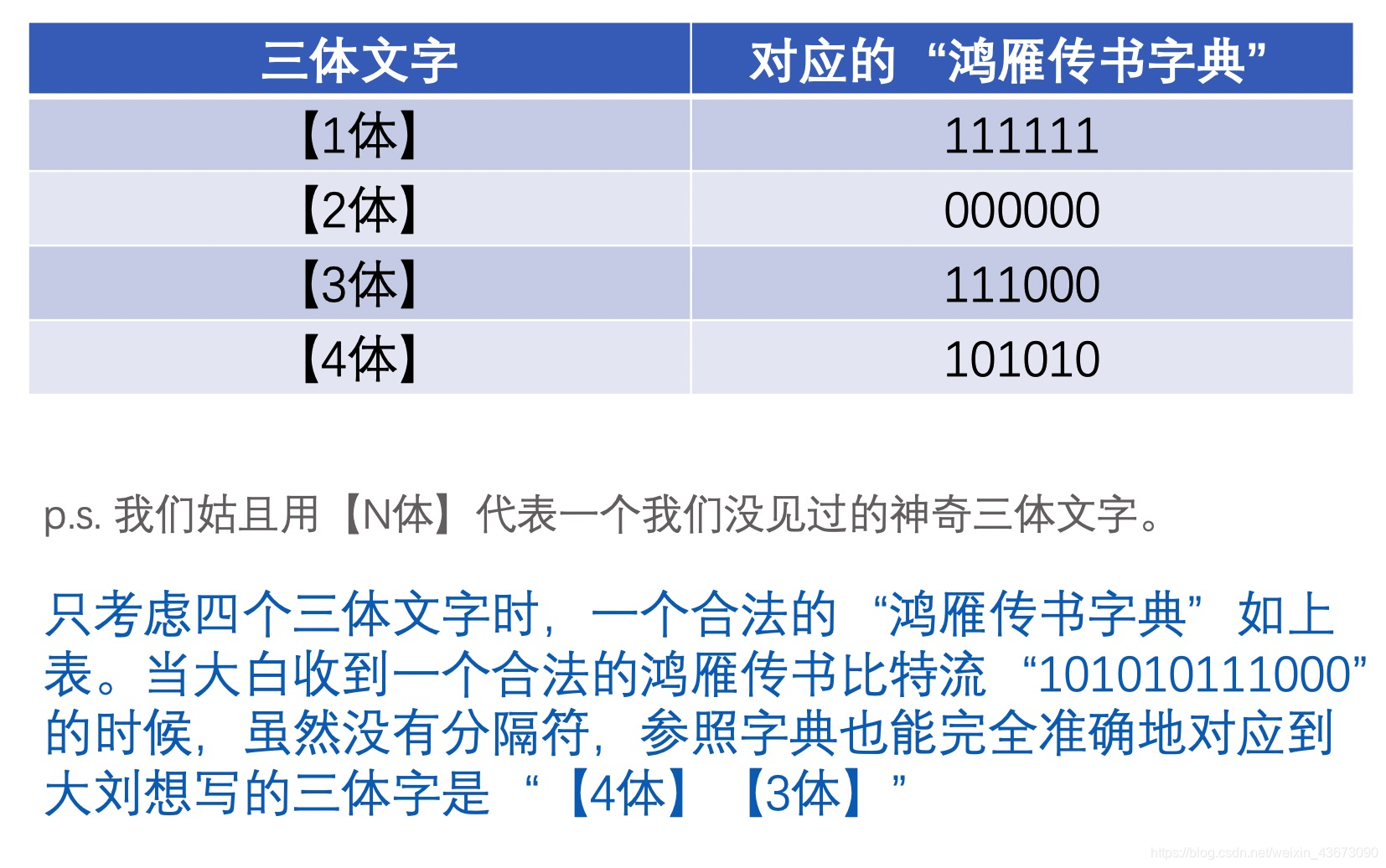
好景不长,由于三体文字实在是博大精深,有成千上万个。原本的“鸿雁传书字典”是大刘随手设计的,每个三体字都要用好多好多比特来描述。大刘有一次问大白“你吃了没”竟然用了23333个比特,写了一大叠纸,鸿雁送到一半累得吐血掉进黑暗森林再没飞起来。
大白得知后伤心地哭了很久(●—●),大刘也十分难过。他和大白保证会设计出新的、最好的“鸿雁传书字典”,为此他把自己和大白的所有传书都搜集了起来,并统计出了其中每一个三体文字的出现次数。
做完这一切后,大刘对着这个统计表犯了难,该怎么设计出一个最好的“鸿雁传书字典”,使得平均意义上表示一个三体文字需要的比特数最少呢?你能帮帮大刘么?
输入格式
输入共有 N+1 行。
第 1 行包含一个整数N,代表大刘统计出的不同三体文字的数量。
第 2 行到第 N+1 行每行有一个整数,代表大刘统计的所有书信里,这行对应的三体文字出现的总次数。
注意:
-
大刘为了请你帮忙,已经把所有三体字按照【1体】-【2体】-【3体】- …… -【N体】的顺序进行了排列,也即第 k 行代表 “【k-1体】” 这个字出现的总次数。
-
N不超过300,000。
输入样例
5
2
1
2
2
3
输出格式
输出共有 N+1 行。
第 1 行包含一个浮点数F,代表你设计的最优“鸿雁传书字典”中,表示每个三体字需要的平均比特数。保留6位小数。
第 2 行到第 N+1 行每行有一个“01”比特串,代表你设计的最优“鸿雁传书字典”中,表示这行对应三体字的01比特编码。
注意:
-
输出“鸿雁传书字典”中编码方案的时候,必须也按照【1体】-【2体】-【3体】- …… -【N体】的顺序进行输出,也即和输入文件中的顺序匹配。
-
表示“鸿雁传书字典”中的编码方案必须使用“0”和“1”来表示,例如“0101”。不接受别的等价描述,例如“2323”。
-
严格保证输出是N+1行,并且每行中不能有和编码比特无关的空格或其他字符。
输出样例
2.300000
111
110
01
00
10
时间限制: 1000 ms 内存限制: 80000 KB
解题
基本思路为构造Huffman树,使得其所有叶子对应一个文字;遍历获取编码时,一般从根节点出发,向左、向右分别对应0、1,最终为一套前缀编码。
1
简要转载 78个星天外的方法:
构造长为n的结构体数组,其余Huffman树的节点在建树时才new即可,尽量保证不要产生额外的节点
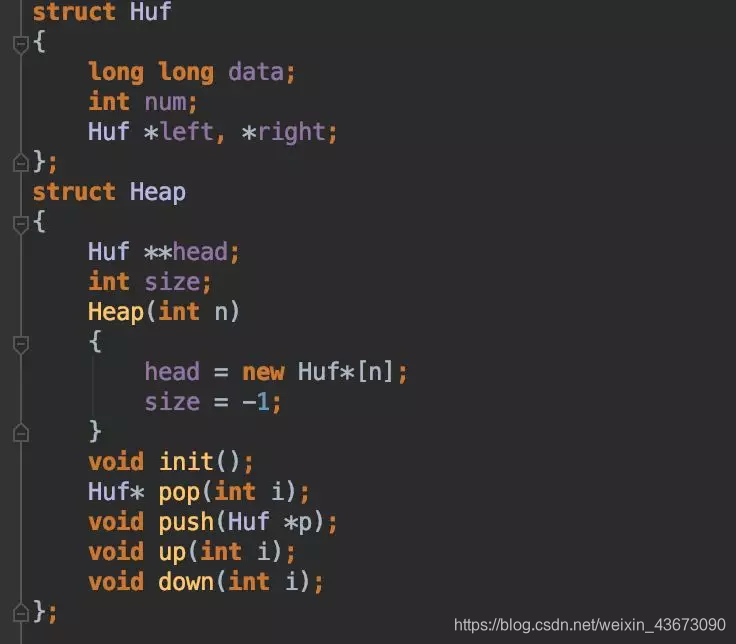
由于构造Huffman 树时,每次选取两个权值最小的根节点,考虑使用最小堆。
为获取编码,遍历时直到叶子才记录,采用二进制long long表示,同时还要记录编码长度。
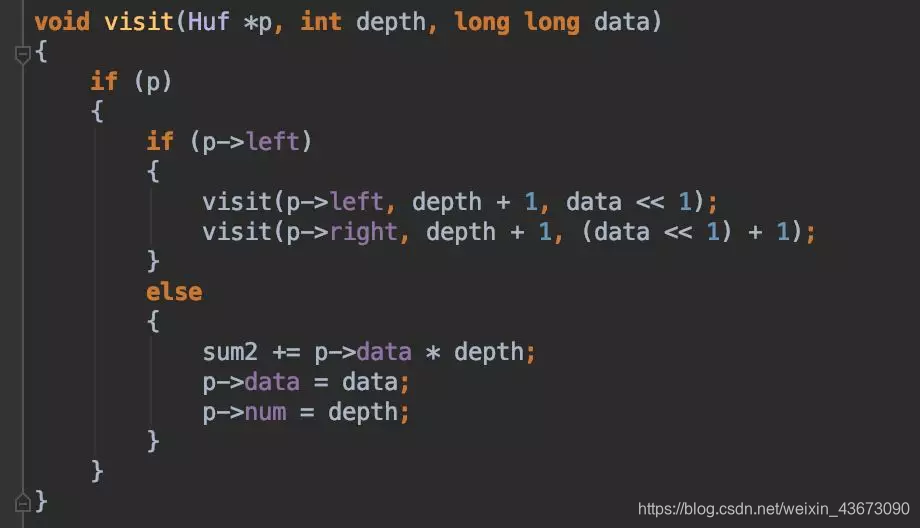
最后还要按照原顺序输出。
显然数据量很大的情况下,复杂度主要在于如何最快找到两个权值最小的头结点,以及最后遍历时如何保证原顺序输出;双队列实现与代码见 原帖。
如果可以使用STL,直接使用priority_queue也可。
2
某些改进
1.由于n个文字作为叶子的Huffman树,结点个数必然是2n-1,因此可以直接在读取权值前构造好一个数组来存储结点,其0~n-1号依次对应各个文字,剩余的必定作为父母结点,最后一个为根节点。
结点不用index+权值+left指针+right指针,而是采用 权值+parent指针,以减少空间占用;index值表示文字的序号,直接用上述数组的自然序号即可代表。
2.计算平均码长的方法:因为权值总和(即所统计的文章中的字数)是根结点的weight,码长总和(文章所需的编码量)恰好也是除了根结点以外所有结点权值之和,这样后者除以前者即可,省去了n步乘法运算。
3.输出时为了区分左右孩子,parent指针使用int数组序号,正值为左、负值为右。这样的好处是不必从根节点向下遍历再用一个容器储存全部编码,只需从0到n-1对每个文字向上回溯、把0或者1压栈,每次只要存储一个文字的编码,输出的时候依次出栈即可,栈可以简单地用数组实现。
再考虑到计算完平均码长,2n-1个结点的weight已经无用,可以直接拿来当做这个栈的容器(显然每个文字的码长不会超过n)。
代码
实测在数据量300,000时内存占用大约10MB、316ms。
#include<stdio.h>
#include<stdlib.h>
#include<algorithm>
#include<queue>
using namespace std;
typedef unsigned long long big_size;
class Huff_nodes{
public:
union{
big_size wei;
int v;
};
int parent;
};
Huff_nodes *hf;
int hfn;
struct cmp{
bool operator()(size_t a,size_t b){
return hf[a].wei>hf[b].wei;
}
};
priority_queue<size_t,vector<size_t>,cmp> qu;
int main(){
scanf("%u",&(hfn));//n个文字
if(hfn==1){//只有一个
scanf("%llu",&hfn);
printf("1.000000\n0");
}
else{
int hfn2=2*hfn-1;
//一次性申请内存,calloc可以初始化,不过建议new+memset
hf=(Huff_nodes*)calloc(hfn2,sizeof(Huff_nodes));
for(int i=0;i<hfn;i++){
scanf("%llu",&(hf[i].wei));
qu.push(i);//用stl的priority_queue存储权值
}
/*
开始构造Huffman树
*/
for(int i=hfn;i<hfn2;i++){
size_t min=qu.top();
qu.pop();
size_t dmin=qu.top();
qu.pop();
hf[min].parent=i;
hf[dmin].parent=-i;
hf[i].wei=hf[min].wei+hf[dmin].wei;
qu.push(i);
}
big_size h=0;
//这里除了根节点以外的权值加起来,顾虑int不够大用longlong
for(int i=hfn2-2;i>=0;i--){
h+=hf[i].wei;
}
printf("%.6f\n",h*1.0/hf[hfn2-1].wei);
//现在根节点就是优先队列里唯一的指针对象hfn2-1
int root=qu.top();
for(int i=0;i<hfn;i++){
int llen=0;
int x=i;
while(x!=root && x!=-root){
if(hf[x].parent>0){//left,0
hf[llen].v=(int)'0';//复用存储空间...
llen++;
x=hf[x].parent;
}
else{//right 1
hf[llen].v=(int)'1';//同理...
llen++;
x=-hf[x].parent;
}
}
for(llen--;llen>=0;llen--){
putchar(hf[llen].v);
}
putchar('\n');
}
free(hf);
}
//getchar();getchar();
}

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









