







 本文介绍了如何使用Python的re模块解析网页数据,特别是在国防科技大学2016年录取分数统计网页上,通过查找< table >和< td >标签来定位和提取数据,避免了依赖数据的规律性。
本文介绍了如何使用Python的re模块解析网页数据,特别是在国防科技大学2016年录取分数统计网页上,通过查找< table >和< td >标签来定位和提取数据,避免了依赖数据的规律性。
尽管我们使用urllib.request可以获取到网页的所有数据,但是要获取我们想要的数据还需要进一步进行数据处理。本篇主要介绍如何使用python的re模块进行数据定位及获取。
1、目标网页源码观察
-
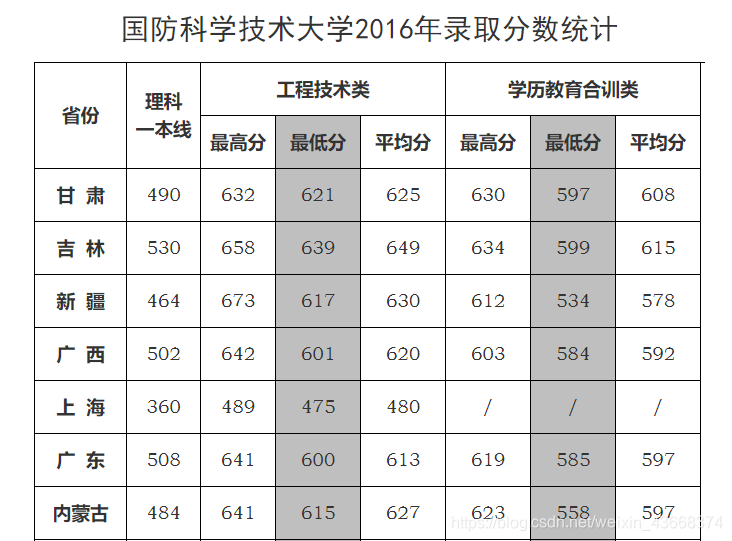
首先来到我们的目标网页之一:国防科技大学2016年录取分数统计,观察其网页结构
-
可以看到网页中用一个表格进行数据的显示,因此我们只需要获取表格的数据。右键点击“查看网页源代码”
-
查看到的网页源代码大致如下

-
在网页源代码中找到我们需要的数据内容是保存在源代码中的< table > 标签中

2、确定数据定位方法
- 从源代码中可以看出我们需要的各地录取分数线存放在< table >标签中的< td >单元格中,仔细观察可以直接定位到< td >中的 < span >标签的位置
<td colspan="3" style="border-style: solid solid solid none; padding: 0cm 5.4pt; width: 246px; height: 34px; border-top-color: windowtext; border-right-color: windowtext; border-bottom-color: windowtext; border-top-width: 1pt; border-right-width: 1pt; border-bottom-width: 1pt;">
<p align="center" style="text-align: center;">
<strong><span style="font-family: 楷体_gb2312;"><span style="font-size: 14pt;">工程技术类</span></span></strong></p>
</td>
<span style="font-size: 14pt;">工程技术类</span>
-
在前一篇文章中我们提到了使用关键字的index进行定位,这里并不适用。使用index进行定位比较适用于所需数据的形式(字符数、间隔)有规律的情况下,因此在这里我们并不使用index进行定位。
-
1、首先需要定位并获取到表格的内容
table = re.findall(r'<table(.*?)</table>', data, re.S)
firsttable = table[0] # 取网页中的第一个表格
- 2、按tr标签对获取表格中所有行,保存在列表rows中
score = []
s=''
for i in firsttable:
s=s+str(i)
rows=re.findall(r'<tr(.*?)</tr>',s,re.S)
- 3、 迭代rows中的所有元素,获取每一行的td标签内的数据,添加到score列表
for i in rows:
td=re.findall(r'<spanstyle="font-size:14pt;">(.*?)</span>',i,re.S)
score.append(td)
score=score[2:]
3、代码部分
import urllib.request as req
import re
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html'
def GetData(url):
webpage = req.urlopen(url) # 根据超链访问链接的网页
data = webpage.< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









