



分布式编程
今天我将就我个人的经验和网上的资料对分布式编程进行自己的描述。
分布式应用程序就是指应用程序分布在不同计算机上,通过网络来共同完成一项任务,通常为服务器/客户端模式。更广义上理解“分布”,不只是应用程序,还包括数据库等,分布在不同计算机,完成同一个任务。之所以要把一个应用程序分布在不同的计算机上,主要有两个目的:
- 分散服务器的压力
大型系统中,模块众多,并发量大,仅用一个服务器承载往往会发生压力过大而导致系统瘫痪的情况。可以在横向和纵向两方面来进行拆分,把这些模块部署到不同的服务器上。这样整个系统的压力就分布到了不同的服务器上。
l 横向:按功能划分。
l 纵向:N层架构,其中的一些层分布到不同的服务器上。 - 提供服务,功能重用
使用服务进行功能重用比使用组件进行代码重用更进一层。举例来说,如果在一个系统中的三个模块都需要用到报表功能,一种方法是把报表功能做成一个单独的组件,然后让三个模块都引用这个组件,计算操作由三个模块各自进行;另一种方法是把报表功能做成单独的服务,让这三个模块直接使用这个服务来获取数据,所有的计算操作都在一处进行,很明显后者的方案会比前者好得多。
服务不仅能对内提供还能对外提供,如果其他合作伙伴需要使用我们的报表服务,我们又不想直接把所有的信息都公开给它们。在这种情况下组件方式就不是很合理了,通过公开服务并对服务的使用方做授权和验证,那么我们既能保证合作伙伴能得到他们需要的数据,又能保证核心的数据不公开。
为了进一步加深对分布式编程的理解,我使用IDEA编辑器构建了一个基本骨架,并使用Maven和spring-MVC对一个简单的网页进行了分布式开发,我使用的是分层架构,将数据持久层,业务层和控制层分成三个子项目,建立在一个父项目下,还建立了一个基本类的项目来存储基本类具体结构目录如下图
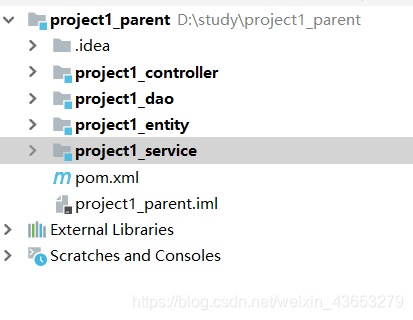
这就是一个基本骨架,然后在相应的pom.xml配置文件中设置相应的依赖关系就可以完成基本骨架的创建,接着便可以进行具体功能以及类的实现,还有控制层网页的设计。
对于依赖关系的处理要注意controller控制层是最后会进行相应部署的文件,所以应该打包成war包并且依赖service业务层和dao数据持久层,然后service业务层和dao数据持久层都打包成jar供controller控制层使用,并且service业务层依赖于dao数据持久层,在设计依赖关系的时候还要特别注意不要设计循环依赖,仔细检查一旦出现循环依赖会导致程序出错无法运行。
以上便是我今天学习以及实践所运用的知识,我希望我的这些经验能够帮助读者更加了解分布式编程,或者是能够让大家对分布式编程有一个初步的了解,希望本篇博客能对大家有所帮助!

















 5508
5508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









