







 本文介绍了Python中的协程概念,针对C10k问题,对比了同步和异步回调的优缺点,强调异步协程兼顾效率和代码可读性。通过asyncio库,展示了从入门到进阶的协程使用,包括asyncio.run()、asyncio.create_task()等关键函数。同时,阐述了asyncio在服务器端实现高并发的优势,以及如何在不同Python版本中实现协程并发。最后提到了asyncio在TCP、UDP、SSL及HTTP框架aiohttp中的应用。
本文介绍了Python中的协程概念,针对C10k问题,对比了同步和异步回调的优缺点,强调异步协程兼顾效率和代码可读性。通过asyncio库,展示了从入门到进阶的协程使用,包括asyncio.run()、asyncio.create_task()等关键函数。同时,阐述了asyncio在服务器端实现高并发的优势,以及如何在不同Python版本中实现协程并发。最后提到了asyncio在TCP、UDP、SSL及HTTP框架aiohttp中的应用。
1.什么是C10k瓶颈?
https://www.cnblogs.com/jjzd/p/6540205.html
2.关于协程虽然是用户态调度,实际上还是需要调度的,既然调度就会存在上下文切换。所以协程虽然比操作系统进程性能要好,但总还是有额外消耗的。而异步回调是没有切换开销的,它等同于顺序执行代码。所以异步回调程序的性能是要优于协程模型的。提问:什么是异步回调?(对比协程)
https://www.cnblogs.com/xybaby/p/6406191.html
简单总结一下,同步比较直观,编码和维护都比较容易,但是效率低,绝大多数时间都是不能忍的。异步效率高,对于callback这种形式逻辑容易被代码割裂,代码不直观,而异步协程的方式既看起来直观,又在效率上有保证。
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
# asyncio.run(main())
await main()
Hello ...
World!
- asyncio.run(main())产生异常:
RuntimeError:asyncio.run() cannot be called from a running event loop传送
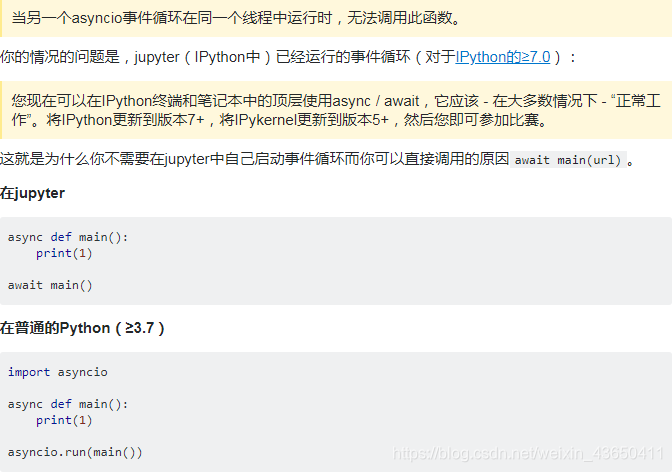
4.py3.7运行协程,asyncio的三种机制
- asyncio.run()运行最高级别的入口点 main()
- 等待一个协程执行完毕
# 等待1s输出hello,再等待2s输入world
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello') # 阻塞在此,直到执行完
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
#asyncio.run(main())
await main()
started at 16:37:22
hello
world
finished at 16:37:25
- asyncio.create_task()并发执行
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
task1 = asyncio.create_task(
say_after(1, 'Hello'))
task2 = asyncio.create_task(
say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
# Wait until both tasks are completed
await task1
await task2
print(f"finished at {time.strftime('%X')}")
# asyncio.run(main())
await main()
started at 16:48:31
Hello
world
finished at 16:48:33 # 时间比上例快了1s
5.练习代码
- 一般代码
import time
def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
time.sleep(sleep_time)
print('OK {}'.format(url))
def main(urls):
for url in urls:
crawl_page(url)
%time main(['url_1', 'url_2', 'url_3', 'url_4'])
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
Wall time: 10 s
- 修改为协程
import time
import asyncio
# < py 3.7 同步
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
r = await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
for url in urls:
await crawl_page(url)
star = time.perf_counter()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(['url_1', 'url_2', 'url_3', 'url_4']))
loop.close()
# await main(['url_1', 'url_2', 'url_3', 'url_4'])
print(time.perf_counter() - star)
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
10.003888006104894
[Finished in 10.5s]
# py < 3.7 异步
import time
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
for url in urls:
await crawl_page(url)
star = time.perf_counter()
loop = asyncio.get_event_loop()
ls = ['url_1', 'url_2', 'url_3', 'url_4']
tasks = [crawl_page(url) for url in ls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
print(time.perf_counter() - star)
crawling url_2
crawling url_3
crawling url_4
crawling url_1
OK url_1
OK url_2
OK url_3
OK url_4
[Finished in 4.5s]
# vs --py 3.7
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
for url in urls:
await crawl_page(url)
star = time.perf_counter()
await main(['url_1', 'url_2', 'url_3', 'url_4'])
print(time.perf_counter() - star)
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
10.006893363000927
# 并发
import time
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
for task in tasks:
await task
star = time.perf_counter()
await main(['url_1', 'url_2', 'url_3', 'url_4'])
print(time.perf_counter() - star)
crawling url_1
crawling url_2
crawling url_3
crawling url_4
OK url_1
OK url_2
OK url_3
OK url_4
3.9993491820005147
# 多线程threading 并发
import time
import threading
def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
time.sleep(sleep_time)
print('OK {}'.format(url))
print('耗时:{:.2f}'.format(time.perf_counter() - star))
def main(urls):
tasks = [threading.Thread(target=crawl_page, name=url, args=(url,)) for url in urls]
for t in tasks:
t.start()
print(threading.current_thread().name)
star = time.perf_counter()
main(['url_1', 'url_2', 'url_3', 'url_4'])
crawling url_1MainThread
crawling url_2MainThread
crawling url_3MainThread
crawling url_4MainThread
OK url_1
耗时:1.03
OK url_2
耗时:2.06
OK url_3
耗时:3.08
OK url_4
耗时:4.11
# -*- coding:utf-8 -*-
'''
sublime
py -3.6
asyncio.gather(*args) 并发
'''
import time
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
star = time.perf_counter()
loop = asyncio.get_event_loop()
tasks = (crawl_page(url) for url in ['url_1', 'url_2', 'url_3', 'url_4'])
loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
print('Wall time: {:.2f}'.format(time.perf_counter() - star))
crawling url_4
crawling url_1
crawling url_2
crawling url_3
OK url_1
OK url_2
OK url_3
OK url_4
Wall time: 4.00
[Finished in 4.5s]
6.Others
asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
asyncio实现了TCP、UDP、SSL等协议,aiohttp则是基于asyncio实现的HTTP框架。
- py3.7版本 协程并发
- asyncio
pip install asyncio
import asyncio
asyncio.run(func())
# await func()
asyncio.create_task(func())
asyncio.gather(*tasks)
- py3.6版本 协程并发
- asyncio
import asyncio
# async / await
loop = asyncio.get_event_loop()
loop.run_until_complete(func(*args, **kw))
loop.close()
# 并发
tasks = [task1, task2]
loop.run_until_complete(asyncio.wait(tasks))
loop.run_until_complete(asyncio.gather(*tasks))
- 多线程 并发
- threading
import threading
#
t = threading.Thread(target=func, name='', args=())
t.start()
t.join()

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









