







- 一、简介
- 二、spark原理
- 三、RDD
- 四、Spark Streaming
一、简介
为什么学spark?
Spark是一种快速、通用、可扩展的大数据分析引擎,是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
spark为什么比mr快?
1_基于内存
2_线程替代进程
spark的启动和web页面?
/export/servers/spark/sbin/start-all.sh
//若配置HA,backup节点需单独启动一下master
正常启动spark集群后,可以通过访问 http://node01:8080,查看spark的web界面,查看相关信息。
二、spark原理
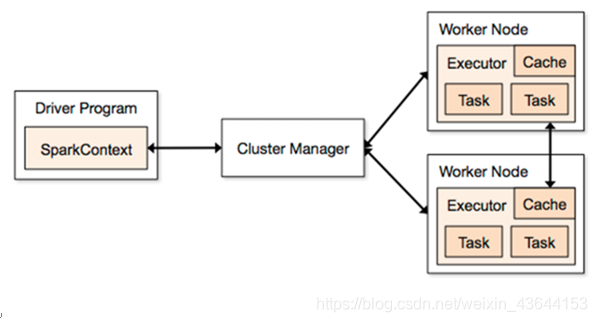
名词解释:
- Driver Program :运⾏main函数并且新建SparkContext的程序。
- Application:基于Spark的应用程序,包含了driver程序和集群上的executor。
- Cluster Manager:指的是在集群上获取资源的外部服务。目前有三种类型:
(1)Standalone: spark原生的资源管理,由Master负责资源的分配
(2)Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
(3)Hadoop Yarn: 主要是指Yarn中的ResourceManager - Worker Node:集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slaves文件配置的Worker节点,在Spark on Yarn模式下就是NodeManager节点。
- Executor:是在一个worker node上为某应用启动的⼀个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。每个应用都有各自独立的executor。
- Task :被送到某个executor上的工作单元。
任务调度
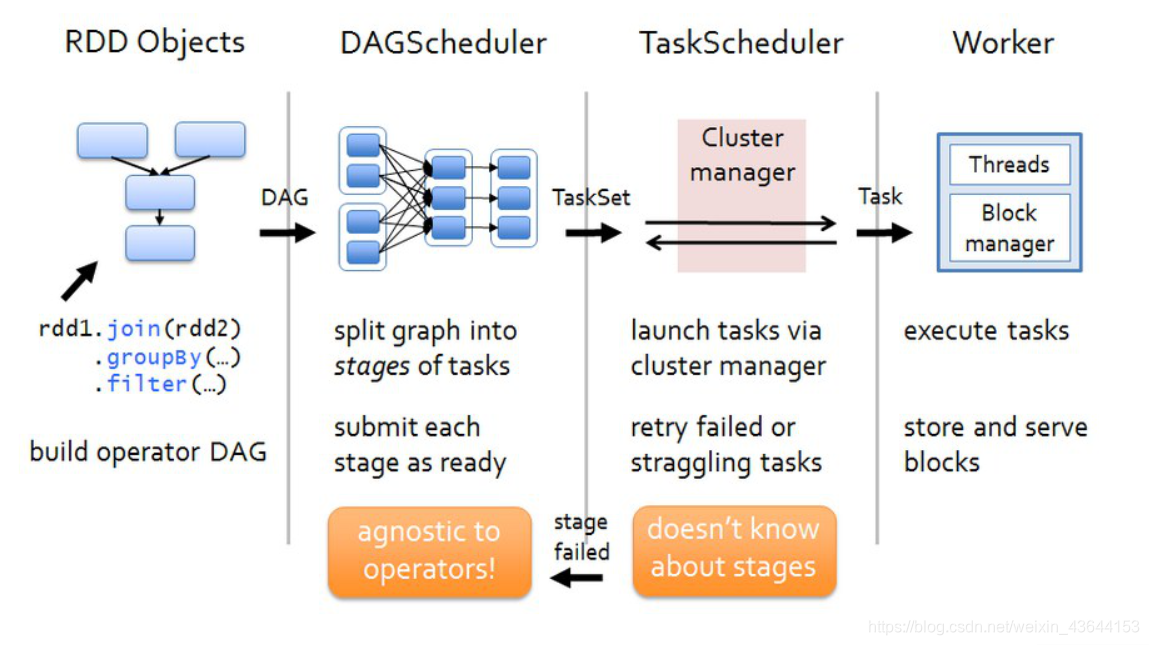
三、RDD
什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
怎么理解RDD的五大属性?
- A list of partitions:一个分区列表;
每一个RDD都有很多个分区,分区里面才是真正的数据,spark的任务是以分区为单位,一个分区后期就对应一个spark的task,也就是一个分区就对应一个线程。
通过val rdd1=sc.textFile("/a.txt"),该文件如果block个数小于等于2,产生的rdd的分区数就是为2;该文件如果block个数大于2,产生的rdd的分区数就是与文件的block个数相等。 - A function for computing each split:作用在每一个分区中函数
举例: val rdd2=rdd1.map(x=>(x,1))
在这里作用的每一个分区中的函数是:x=>(x,1) - A list of dependencies on other RDDs:一个rdd会依赖于其他多个rdd
spark任务的容错机制就是根据这个特性而来。 - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):(可选项)对于kv类型的RDD才会有分区函数这个概念(必须要产生shuffle),不是kv类型的rdd分区函数是None
spark中有2种分区函数:第一种是hashPartitioner(默认值),其本质key.hashcode % 分区数 = 分区号;第二种是RangePartitioner,它是基于一定的范围的分区函数。 - Optionally, a list of preferred locations to compute each split on(e.g. block locations for an HDFS file):(可选项)一组最优的分区位置,这里就涉及到数据的本地性和数据块位置最优
spark进行任务分配的时候,优先考虑存有数据的worker节点来进行任务的计算。
创建RDD的三种方式?
val rdd1 = sc.textFile("/a.txt")
val rdd2 = sc.parallelize(List(1,2,3))
val rdd3 = rdd1.flatMap(_.split(","))
RDD的常用算子?
强烈建议每个算子看一下scala源码,有助理解。

RDD的依赖关系?
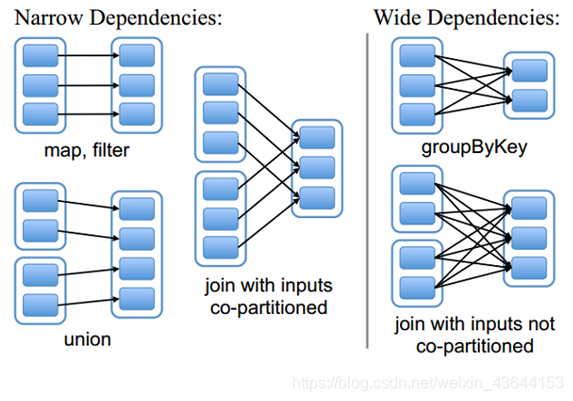
1、窄依赖
指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。
2、宽依赖
指的是多个子RDD的Partition会依赖同一个父RDD的Partition。
3、血统
RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
RDD的缓存机制
1、设置缓存的两种方式
rdd.cache
rdd.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)
实际上cache底层也是调用了persist方法,是将数据缓存在内存中。
2、什么时候需要设置缓存?
1)某个RDD后期被多次调用
2)某个RDD的结果计算逻辑很复杂
3、清除缓存的方式
1)自动清除:整个程序结束之后,缓存中的所有数据自动清除
2)手动清除:rdd.unpersist(true)
四、Spark Streaming
Spark Streaming简介
1、类似于storm,用于流式数据处理(以批做流),基本原理是把输出数据以某一个很小的时间间隔(秒级)批量处理;
2、高吞吐,容错能力强;
3、编程模型是DStream;
4、其批处理引擎是Spark Core,运算的时候将对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作。
Spark Streaming的数据源&输出
 DStream(Discretized Stream)介绍
DStream(Discretized Stream)介绍
是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。
示例代码
spark实现点击流日志分析(统计PV UV TOPN)

















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









