






复制
复制内容实现很简单,创建一个textarea标签,将textArea的值设为要复制的内容,document.execCommand(‘copy’)执行复制操作,尝试将选中的文本复制到剪切板,如果操作成功返回true,否则返回false。操作完成后删除textarea标签
const handleCopy = value => {
let success
var textArea = document.createElement('textarea')
textArea.value = value
document.body.appendChild(textArea)
textArea.select()
success = document.execCommand('copy')
document.body.removeChild(textArea)
if (success) {
toast.show('复制成功')
} else {
toast.show('复制失败')
}
}
文字转语音播放
大致流程是: 用户触发播放→预处理文本→ 分段→ 转换每段为音频→ 按顺序播放
要实现的功能:文本智能分段处理、基于Web Audio API的播放控制、语音片段缓存机制、播放状态管理和错误处理、支持随时中断播放
实现详解
基础架构设计
audioContext 首次播放时初始化
messageStates采用Map结构存储各消息的独立状态
currentPlayingId确保同一时间只能有一个播放实列
// 音频上下文单例(全局唯一)
const audioContext = ref(null)
// 消息状态存储器
const messageStates = ref(new Map())
// 当前播放中的消息ID
const currentPlayingId = ref(null)
播放状态
为什么使用Map而不是普通对象?
| 对比项 | Map | 普通对象 |
|---|---|---|
| 键类型 | 支持任何类型,如对象 | 支持字符串/Symbol |
| 顺序保证 | 插入的顺序 | ES6保留字符串顺序 |
| 性能 | 大数据量时更高效 | 小数据量无差别 |
| 内置方法 | size属性、forEach | 需要Object.keys |
const getMessageState = message => {
if (!messageStates.value.has(message.id)) {
messageStates.value.set(message.id, {
isPlaying: false,//当前消息的播放状态,是否在播放,一开始生成chatRecordList就添加了
audioQueue: [],//待播放队列
audioSource: null,//当前音频源,Web Audio API的音频源对象
abortController: null,//中断控制器
convertedSegments: new Map()//已转换片段缓存,已转换的文本-音频映射缓存
})
}
return messageStates.value.get(message.id)
}
核心播放流程
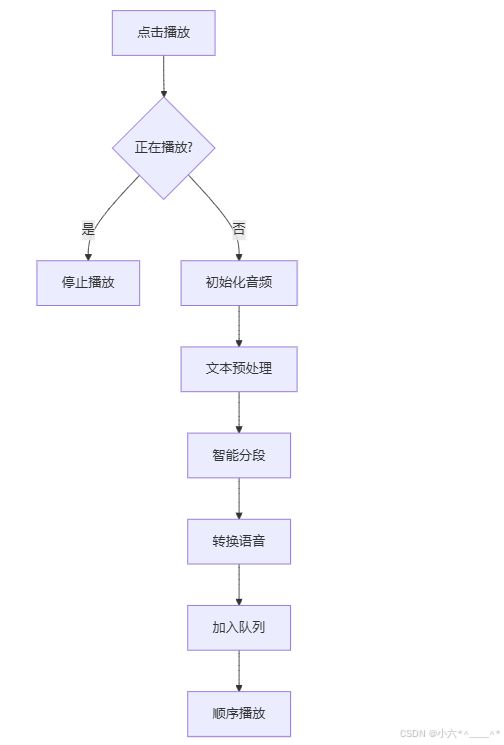
const handlePlay = async message => {
emit('isClickThought', true)
// 获取当前的状态对象
const state = getMessageState(message)
try {
// 切换播放状态
if (state.isPlaying) {
await stopMessagePlayback(message)
return
}
// 停止其他正在播放的消息
await stopAllPlayback()
// 初始化音频上下文
if (!(await initAudioContext())) return
// 设置播放状态
state.isPlaying = true
currentPlayingId.value = message.id
state.abortController = new AbortController()
// 文本处理
const text = stripHtmlTags(message.content)
const segments = splitText(preprocessText(text))
// 开始转换和播放流程
for (const [index, segment] of segments.entries()) {
if (!state.isPlaying) break//中断检查
// 转换文本为语音
const audioData = await convertSegment(segment, state.abortController.signal, message)
if (audioData) {
state.audioQueue.push({ audioData, index })
await playAudioQueue(message)
}
}
} catch (error) {
if (error.name !== 'AbortError') {
console.error('播放失败:', error)
toast.show('播放失败,请重试')
}
} finally {
state.isPlaying = false
currentPlayingId.value = null
}
}
文本预处理
1、HTML标签处理
因为流式返回的渲染数据是有样式带标签的,所以在调用文字转语音的接口之前还是先把标签去掉的好
const stripHtmlTags = htmlContent => {
// 使用正则表达式去除所有的HTML标签
let tempDiv = document.createElement('div')
tempDiv.innerHTML = htmlContent
let text = tempDiv.textContent || tempDiv.innerText || ''
// 返回纯文本内容
return text.trim()
}
2、文本规范化处理
因为返回的数据会含有文献引用标记、连续的空格等,为了语音播放的流畅,需要做规范化文本处理
const preprocessText = text => {
return (
text
// 清理特殊字符
.replace(/\[\d+\]/g, '') // 删除[1][2]类文献标记
.replace(/\*\*/g, '') // 删除加粗符号
.replace(/[""]/g, '"') // 统一引号
.replace(/['']/g, "'") // 统一单引号
.replace(/(\s*\n\s*)+/g, ' ') // 合并换行和空白为单空格
.replace(/\s+/g, ' ') // 合并连续空格
.trim()
)
}
3、对文本进行分段
分段是因为后端接口最长只能传150个字符,首先尝试按句子分割文本,并确保每个分割后的断立长度不超过设置的最大长度,这里我设置了80个字符,如果句子超过了这个长度限制,则进一步更加标点符号将其细分为更小的部分
const splitText = processedText => {
// 更合理的分段逻辑:优先按句子分割,兼顾长度限制
const sentenceRegex = /[^。!?;\n]+[。!?;\n]*/g//找到以句号、感叹号、问号、分号或换行符结尾的句子
let sentences = processedText.match(sentenceRegex) || []//提取所有匹配的句子,如果没有匹配的返回空数组
//
return sentences.reduce((segments, sentence) => {
sentence = sentence.trim()
if (!sentence) return segments
const MAX_LENGTH = 80//设置最大长度为80个字符
if (sentence.length <= MAX_LENGTH) {
segments.push(sentence)//长度小于或等于最大长度,则直接将该句子添加到段落列表 segments 中
} else {
//如果超过最大长度则进行二次分割
// 对长句子进行二次分割
let currentChunk = ''//存储当前正在构建的段落部分
// split(/([,,]|\.\s+)/) 方法将句子按逗号、中文逗号或句号加空格进行分割。遍历后逐个添加到currentChunk
sentence.split(/([,,]|\.\s+)/).forEach(part => {
if ((currentChunk + part).length > MAX_LENGTH) {
// 如果添加part后长度超过最大长度,则将currentChunk添加到segments,并重置currentChunk为part
segments.push(currentChunk.trim())
currentChunk = part
} else {
currentChunk += part
}
})
// 如果最后还有剩余的currentChunk,则添加到segments
if (currentChunk) segments.push(currentChunk.trim())
}
return segments //返回
}, [])
}
初始化音频
这里主要目的是确保 AudioContext 被正确初始化,并在需要时恢复其状态。这对于处理音频数据是非常重要的,因为 AudioContext 是 Web Audio API 的核心。
const initAudioContext = async () => {
try {
//是否已存在audioContext,如果不存在,则创建一个新的AudioContext 实例
if (!audioContext.value) {
audioContext.value = new (window.AudioContext || window.webkitAudioContext)()//区别不同浏览器对AudioContext 的支持肯能有所不同,这里这样写是为了保持兼容性
}
// 检查AudioContext 的状态是否为suspended,在某些情况下,浏览器自动挂起策略可能会导致AudioContext 被挂起,因此需要用resume方法来恢复其状态
if (audioContext.value.state === 'suspended') {
await audioContext.value.resume()
}
return true //初始化成功返回true
} catch (error) {
console.error('初始化AudioContext失败:', error)
return false
}
}
关于AudioContext :AudioContext 是Web Audio API的核心组件之一,它提供了一个强大的、模块化的且基于可复用组件的系统来合成音频,通过AudioContext ,开发者可以在网页或应用中创建、控制以及处理音频资源
自动播放策略:现代浏览器为了改善用户体验、实施了严格的自动播放政策,这意味着需要用户交互,比如点击才能播放音频
文本转语音
segment:要转换的文本片段
signal 用于中断请求信号
message包含转换状态的信息对象
使用缓存机制可以避免重复请求;请求中断在用户取消操作或需要理解停止的转换的时候有用
// 处理单个文本片段的转换
const convertSegment = async (segment, signal, message) => {
try {
const state = getMessageState(message)//获取消息状态
// 缓存检查
if (state.convertedSegments.has(segment)) {
return state.convertedSegments.get(segment) //如果有缓存,直接使用缓存
}
// signal中断信号
const response = await api.chat.TextToVoice({ text: segment }, { signal })
const audioData = response?.data?.Response?.Audio
if (audioData) {//缓存结果
state.convertedSegments.set(segment, audioData)
return audioData
}
} catch (error) {
if (error.name !== 'AbortError') {
console.error('语音转换失败:', error)
}
return null
}
}
播放队列管理
前面调用文字转语音的接口返回了多个音频片段,函数通过检查audioQueue的当都和当前这段音频的播放状态进行while循环,这样确保了只有在允许播放的情况下才会继续播放音频;通过使用shift方法从队列中取出音频对象,确保每次只播放一个音频并且是按顺序播放的
}
// 播放音频队列管理
const playAudioQueue = async message => {
const state = getMessageState(message)//获取消息状态
// 确保按顺序播放,根据每个音频的index属性排序
state.audioQueue.sort((a, b) => a.index - b.index)
//循环播放音频
while (state.audioQueue.length > 0 && state.isPlaying) {
const { audioData } = state.audioQueue.shift()//获取并移除队列中的第一个音频,并提取音频数据
await playAudioData(audioData, message) //播放音频数据
}
}
decodeAudioData:异步解码音频文件
支持格式:MP3、WAV、OGG等
自动检测音频格式
返回AudioBuffer供播放使用
createBufferSource:创建可控音频源
可以设置播放速度
支持循环播放
精确控制播放时间
为什么要将Base64转为arrayBuffer?
音频数据通常以Base64字符串传输,但是Web Audio API需要二进制数据,所以需要转。base64ToArrayBuffer 函数通过atob解码,再转为Unit8Array
audioContext.value.decodeAudioData(arrayBuffer)将二进制数据解码为音频缓冲区AudioBuffer
const playAudioData = async (audioData, message) => {
const state = getMessageState(message)//获取消息状态
try {
const arrayBuffer = base64ToArrayBuffer(audioData)//将base64字符串转换为ArrayBuffer
const audioBuffer = await audioContext.value.decodeAudioData(arrayBuffer)//异步解码音频数据
const source = audioContext.value.createBufferSource()//创建一个新的音频源
source.buffer = audioBuffer//将解码后的音频数据赋值给音频源
source.connect(audioContext.value.destination)//将音频源连接到音频上下文的目标节点(通常是扬声器)
state.audioSource = source//将音频源保存到消息状态中,以便稍后可以停止它
await new Promise(resolve => {
source.onended = resolve//当音频播放结束时,解决Promise
source.start(0)//开始播放音频
})
} catch (error) {
if (error.name !== 'AbortError') {
console.error('播放失败:', error)
}
} finally {
state.audioSource = null
}
}
// 示例:base64字符串 "ABC" → 二进制数据 [0x00, 0x01, 0x02]
const base64ToArrayBuffer = (base64) => {
const binaryString = atob(base64) // 解码base64
const bytes = new Uint8Array(binaryString.length)
for (let i = 0; i < binaryString.length; i++) {
bytes[i] = binaryString.charCodeAt(i) // 转为ASCII码
}
return bytes.buffer
}
停止机制
const stopMessagePlayback = async message => {
const state = getMessageState(message)
state.isPlaying = false
state.abortController?.abort()//中止当前正在进行的转换和播放操作
if (state.audioSource) {
state.audioSource.stop()//停止音频播放
state.audioSource.disconnect()//断开音频源与音频上下文的连接
}
state.audioQueue = []//清空待播放的音频队列
}
//停止所有正在播放的音频
const stopAllPlayback = async () => {
for (const [id, state] of messageStates.value) {
if (state.isPlaying) {
await stopMessagePlayback({ id })
}
}
}

















 1503
1503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









