







使用python的scrapy爬取文本保存为txt文件
编码工具
Visual Studio Code
实现步骤
1.创建scrapyTest项目
在vscode中新建终端并依次输入下列代码:
scrapy startproject scrapyTest
cd scrapyTest
code
打开项目scrapyTest(vscode自动生成下列文件)
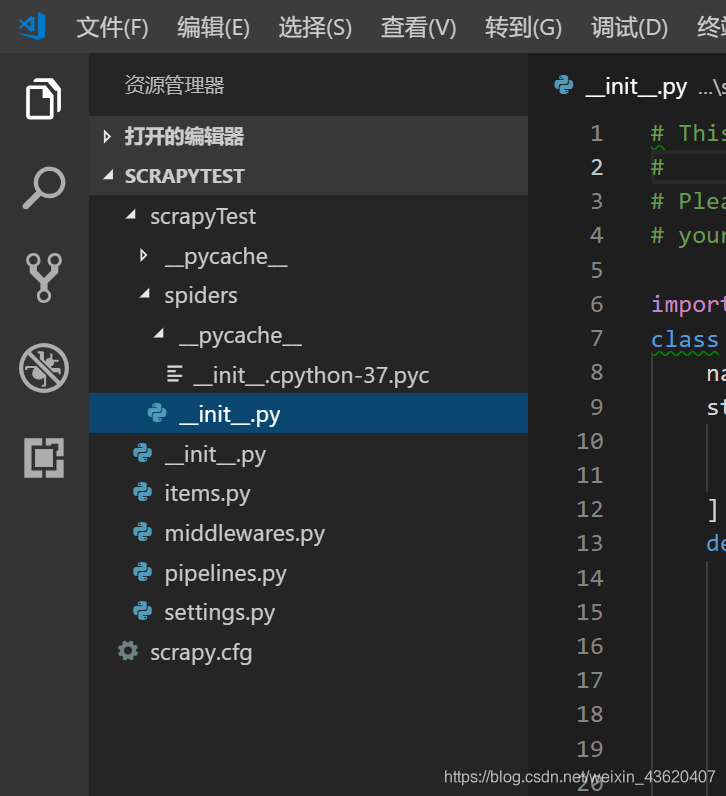
2.源代码
pipelines.py
class ScrapytestPipeline(object):
def open_spider(self,spider):
#创建my.txt文件,并将字符集设为utf-8
self.file = open('my.txt', 'w', encoding='utf-8')
def close_spider(self,spider):
self.file.close()
def process_item(self, item, spider):
#将爬取到的文本保存到my.txt中;当向txt中写入字典,list集合时,使用str()
self.file.write(str(item)+'\n')
settings.py
BOT_NAME = 'scrapyTest'
SPIDER_MODULES = ['scrapyTest.spiders']
NEWSPIDER_MODULE = 'scrapyTest.spiders'
ROBOTSTXT_OBEY = False
# 关键代码,没有这段无法实现保存
ITEM_PIPELINES = {
'scrapyTest.pipelines.ScrapytestPipeline': 300,
}
_ init_.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "scrapyTest"
#爬取的网站域名
allowed_domains=['book.zongheng.com']
#爬取的页面起始页
start_urls = [
'http://book.zongheng.com/chapter/48942/1202330.html',
]
def parse(self, response):
#css('div.content p::text')使用谷歌浏览器开发者工具查看所要爬取文本的具体位置
text=response.css('div.content p::text').getall()
dic={} #创建字典dic
dic['text']=text
yield dic #返回dic
# 读取下一页的内容并回调parse方法
# for a in response.css('a.nextchapter'):
# yield response.follow(a, callback=self.parse)
下面三个文件是创建项目自动生成,无需修改代码
items.py
import scrapy
class ScrapytestItem(scrapy.Item):
name = scrapy.Field()
pass
middlewares.py
from scrapy import signals
class ScrapytestSpiderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class ScrapytestDownloaderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
scrapy.cfg
[settings]
default = scrapyTest.settings
[deploy]
project = scrapyTest
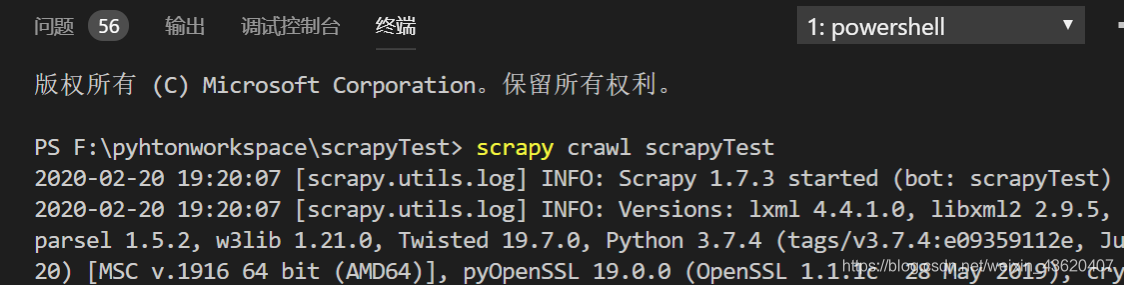
3.运行程序
打开终端,定位到scrapyTest项目路径下,输入下列代码运行程序。
scrapy crawl scrapyTest
4.运行截图
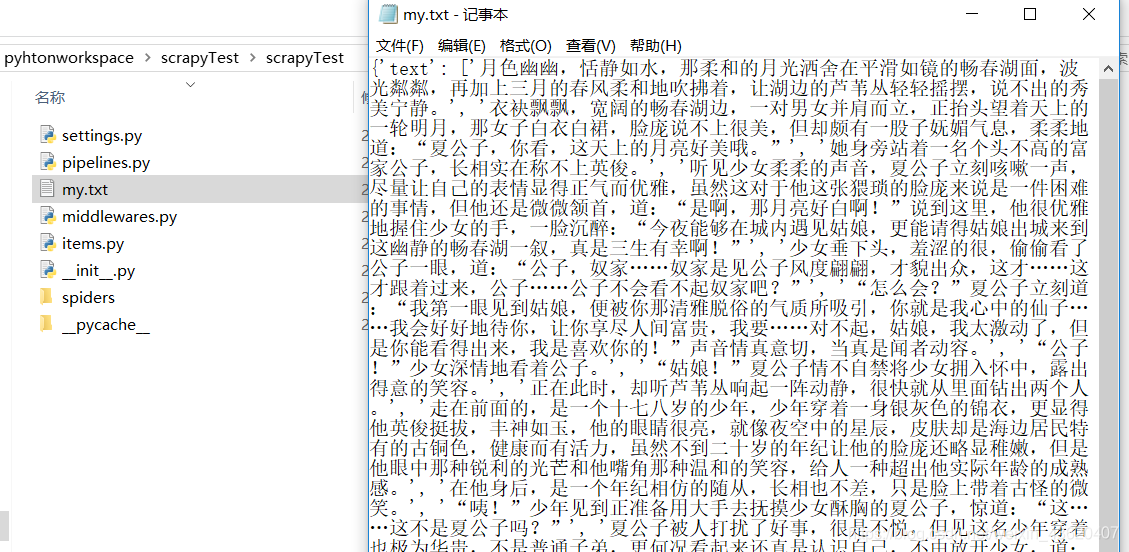

















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









