







Python网络爬虫基础
爬虫基础
请求与相应
在进行爬虫数据采集的过程中,往往是通过一个链接地址向服务器模拟发送请求,从而得到此地址在服务器中的数据。这个地址会遵循互联网数据传输协议:
协议
- 协议,意思是共同计议,协商,经过谈判、协商而定制的共同承认、共同遵守的文件。
- 协议,网络协议的简称,网络协议是通信计算机双方必须共同遵从的一组约定。如怎么样建立连接、怎么样互相识别等。只有遵守这个约定,计算机之间才能相互通信交流。
爬虫业务场景中最常见就是 http 协议
HTTP/HTTPS 协议
- HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法。
- HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
HTTP/HTTPS的优缺点
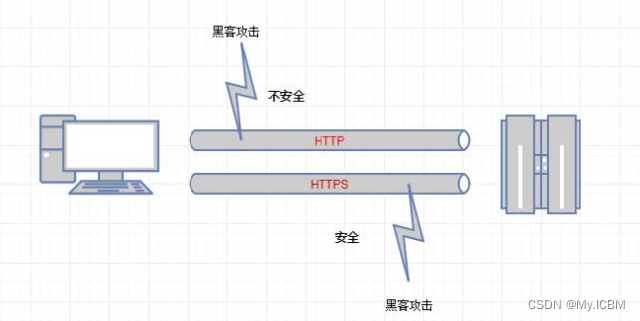
HTTP 的缺点
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
HTTPS的优点
为了解决 HTTP 协议的以上缺点,在上世纪90年代中期,由网景(NetScape)公司设计了 SSL 协议。SSL 是“Secure Sockets Layer”的缩写,中文叫做“安全套接层”。
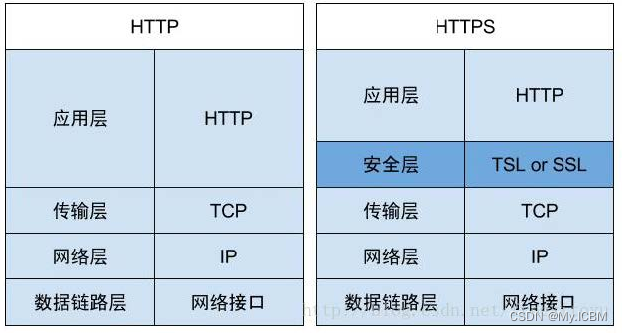
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
请求与响应概述
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
浏览器发送HTTP请求的过程:
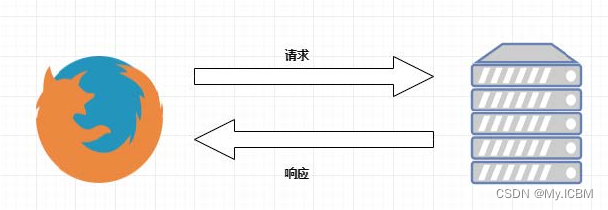
- 当我们在浏览器输入URL https://www.baidu.com 的时候,浏览器发送一个Request请求去获取 https://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
- 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
请求
请求目标(url)
URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于Windows的文件路径。
一个网址的组成:
1. http://:这

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











