







 本文介绍了如何使用Kafka Stream进行实时数据清洗,针对带有">>>"前缀的单词进行处理,将"atguigu>>>ximenqing"等输入转化为"ximenqing"。文章详细讲解了需求分析、maven依赖、主类创建、业务逻辑实现、程序运行以及生产者和消费者的启动步骤,提供了一套完整的实操案例。
本文介绍了如何使用Kafka Stream进行实时数据清洗,针对带有">>>"前缀的单词进行处理,将"atguigu>>>ximenqing"等输入转化为"ximenqing"。文章详细讲解了需求分析、maven依赖、主类创建、业务逻辑实现、程序运行以及生产者和消费者的启动步骤,提供了一套完整的实操案例。
0)需求:
实时处理单词带有”>>>”前缀的内容。例如输入”atguigu>>>ximenqing”,最终处理成“ximenqing”
1)需求分析:
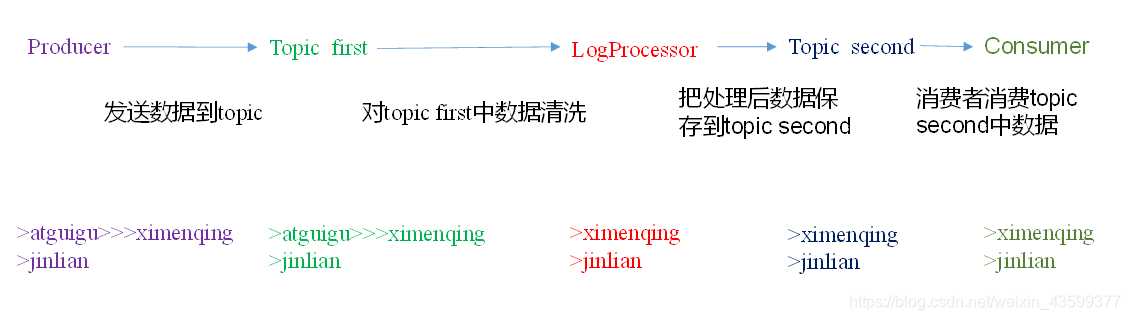
2)案例实操
需要的maven包:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.sheng.hbase</groupId>
<artifactId>HbaseMaven</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<!-- Winodws下提交至Yarn上运行,改客户端是2.6.1s
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.1</version>
</dependency>
-->
<dependency>
<groupId>junit</groupId>
<artifactId 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









