




 本文详细解释了TF-IDF算法的工作原理,包括词频(TF)和逆文档频率(IDF)的概念,并通过sklearn库的TfidfVectorizer实例展示了如何计算TF-IDF值,以及如何将文本转换为TF-IDF矩阵。
本文详细解释了TF-IDF算法的工作原理,包括词频(TF)和逆文档频率(IDF)的概念,并通过sklearn库的TfidfVectorizer实例展示了如何计算TF-IDF值,以及如何将文本转换为TF-IDF矩阵。
一. 什么是TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率).
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- 词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)

- 逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
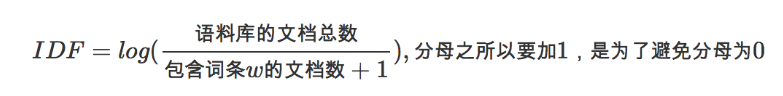
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
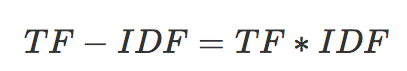
**二.sklearn中的TfidfVectorizer
#coding=utf-8
from sklearn.feature_extraction.text import TfidfVectorizer
document = ["I have a pen.",
"I have an apple."]
tfidf_model = TfidfVectorizer().fit(document)
sparse_result = tfidf_model.transform(document) # 得到tf-idf矩阵,稀疏矩阵表示法
print(sparse_result)
# (0, 3) 0.814802474667
# (0, 2) 0.579738671538
# (1, 2) 0.449436416524
# (1, 1) 0.631667201738
# (1, 0) 0.631667201738
print(sparse_result.todense()) # 转化为更直观的一般矩阵
# [[ 0. 0. 0.57973867 0.81480247]
# [ 0.6316672 0.6316672 0.44943642 0. ]]
print(tfidf_model.vocabulary_) # 词语与列的对应关系
# {'have': 2, 'pen': 3, 'an': 0, 'apple': 1}

















 2731
2731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









