







首先有张表
CREATE TABLE `person` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`type` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
表里很简单三条数据:
INSERT INTO `apollo`.`person`(`id`, `name`, `type`) VALUES (1, 'zhangsan', 1);
INSERT INTO `apollo`.`person`(`id`, `name`, `type`) VALUES (2, 'lisi', 1);
INSERT INTO `apollo`.`person`(`id`, `name`, `type`) VALUES (3, 'jarvis', 2);
type 为1 的是: zhangsan,lisi 。type 为2 的是: jarvis
场景1:
统计type 类型为 1,为2的条数:
SELECT
type,
count( * )
FROM
`person`
WHERE
type IN ( 1, 2 )
GROUP BY
type
运行结果:
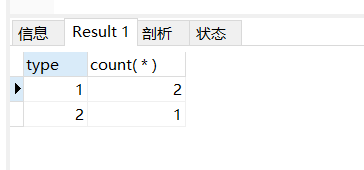
是我们想要的。
如果场景变更,我还要统计 type为3 的条数:
显然type为3的条数我们肉眼看出来了,没有,那如果我们想在查询条件里展示处理,没有的话就 为0
此时,以前的 SQL 就做不到了,因为 Where 条件里面的命中数据没有 type 为3的,无法做数据分组以及统计了,所以我们需要更改一下我们的 SQL 思路
临时表的思路:
SQL 构建一张 type 为 1、2、3的 临时表
SELECT 1 AS `condition` UNION SELECT 2 UNION SELECT 3
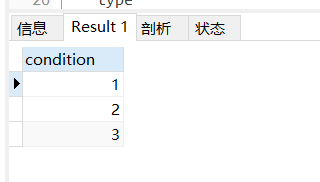
(可以是临时表,也可以实际去建一张表,都可以,但开发场景中为了 构建返回数据的一个场景而去建一张表,有没有必要就根据实际的开发场景自己去衡量了)
最终的 SQL
SELECT
t.`condition`,
IFNULL( p.count, 0 ) AS totalCount
FROM
( SELECT 1 AS `condition` UNION SELECT 2 UNION SELECT 3 ) t
LEFT JOIN (
SELECT
`type` AS t,
count( * ) AS count
FROM
person
WHERE
`type` IN ( 1, 2, 3 )
GROUP BY
`type`
)
AS p
ON t.`condition` = p.t
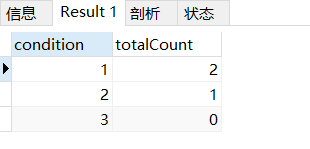
这就是我们想要的了…!!
但是实际工作开发中,这个 type 可不会让你刚好这么巧, 1、2、3,能让你写死,它可以变化的,可能 是 1、2, 或者是 1,3,4,5,6,7,9…
那么这个时候我们的SQL就在 Mapper.xml 文件里手动去拼凑你的SQL了:
可以把 types 作为 Dao层的一个入参:
SELECT
t.`condition` AS type,
IFNULL( p.count, 0 ) AS totalCount
FROM
(
<foreach collection="types" item="type" separator=" UNION ">
SELECT #{type} AS `condition`
</foreach>
) t
LEFT JOIN (
SELECT
`type` AS t,
count( * ) AS count
FROM
person
WHERE
1=1
<if test="types != null and types.size() > 0">
AND `type` IN
<foreach collection="types" item="type" separator=" , " open="(" close=")">
#{type}
</foreach>
</if>
(AND 你的一些查询条件)
GROUP BY `type`
) AS p ON t.`condition` = p.t



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









