 用OpenCV+Selenium模拟QQ邮箱滑块验证
用OpenCV+Selenium模拟QQ邮箱滑块验证







 本文介绍用OpenCV和Selenium对QQ邮箱滑块进行模拟测试。先使用Selenium登录,处理iframe框进行账号密码登录;再通过Selenium获取图片src并保存到本地,用OpenCV进行图像缺口检测,计算滑块移动距离;最后使用Selenium的ActionChains进行鼠标移动操作,测试已能正确拖动滑块。
本文介绍用OpenCV和Selenium对QQ邮箱滑块进行模拟测试。先使用Selenium登录,处理iframe框进行账号密码登录;再通过Selenium获取图片src并保存到本地,用OpenCV进行图像缺口检测,计算滑块移动距离;最后使用Selenium的ActionChains进行鼠标移动操作,测试已能正确拖动滑块。
之前发了一个国航的滑块模拟操作,没有计算滑块到缺口的位置。
本篇则是用opencv+selenium来对QQ邮箱的滑块进行模拟测试。
QQ邮箱链接: https://mail.qq.com/
QQ邮箱这个登录机制,需要我们输入一个错误的账号或密码会有机会弹出滑块验证码,所以我下面就一直用错误的账号进行测试。
其实部分账号,或者说异地登录的QQ账号也都需要滑动解锁验证码才能继续登录。所以这个测试以后可能用的上。
首先是用selenium登录:
访问过来以后,看到的是一个如下图所示的页面。我们需要点击账号密码登录才能进行我们的模拟操作。
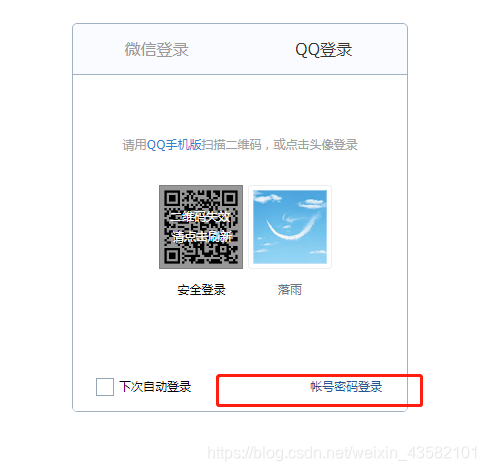
刚开始我直接用selenium获取ID点击账号登录,发现没什么作用。
后来仔细一看这是一个iframe框,我们直接是不能点击到的。
要进行frame切换。
selenium中有这样的操作:
driver.switch_to.frame("login_frame") # login_frame是该登录窗口iframe的id
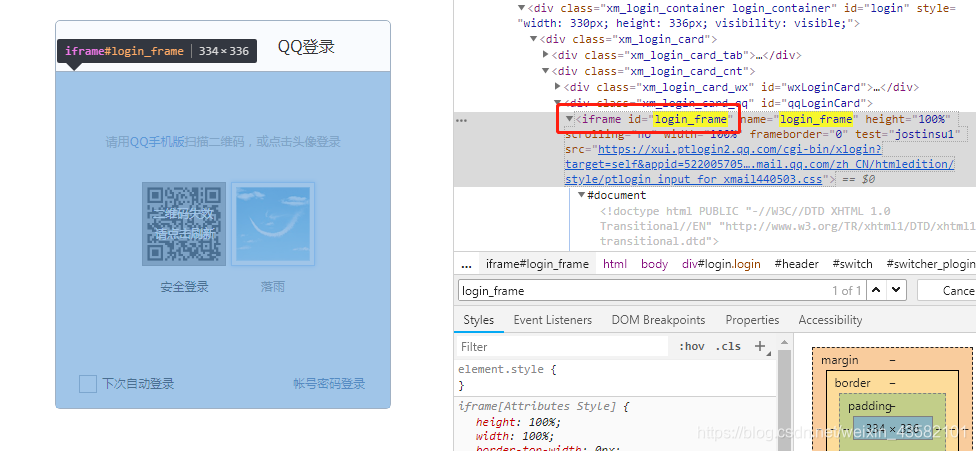
这样才能点击到。以供我们接下来的操作。
driver.get('https://mail.qq.com')
time.sleep(2)
driver.switch_to.frame("login_frame") # 切换frame。login_frame是该登录窗口id
time.sleep(1)
driver.find_element_by_id('switcher_plogin').click() #点击账号密码登录
time.sleep(1)
username = '1234567{}@qq.com'.format(random.randint(0,99)) #随机获取一个账号
driver.find_element_by_id("u").send_keys(username) #输入账号
time.sleep(1)
driver.find_element_by_id("p").send_keys('wwwwwwwwwwwww') #输入一个密码
time.sleep(1)
driver.find_element_by_id("login_button").click() #点击登录
time.sleep(1)
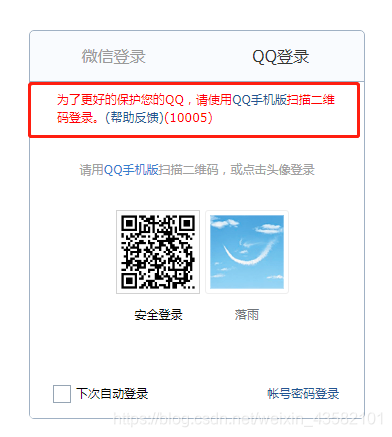
如果出现了这么个玩意,没有出现滑块。那你就再试一次=。=
正常情况出现滑块后:
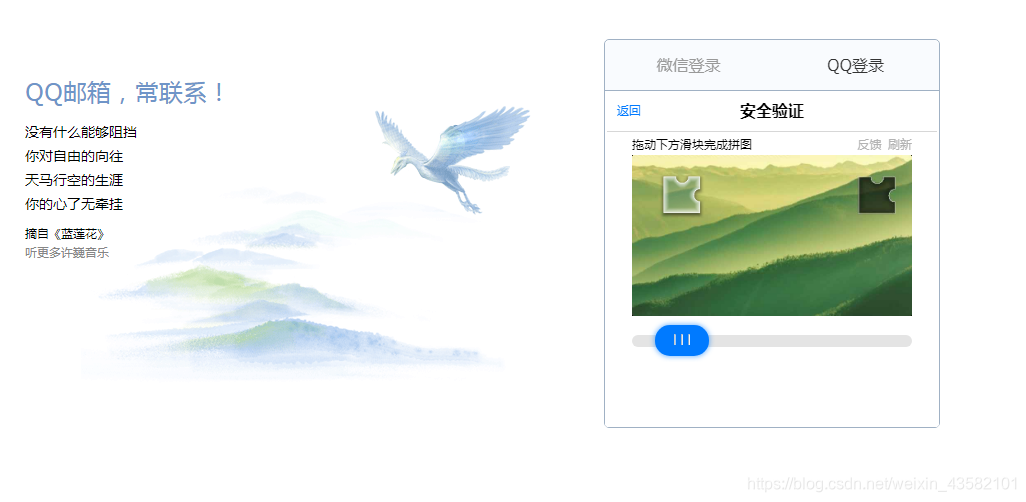
开始进行缺口位置识别:
我这里使用的方法,是通过selenium中的xpath把图片的src获取到,然后下载下来保存到本地。再通过opencv来进行图像缺口检测。
那我们先获取两个图片(滑块和验证图)的src:
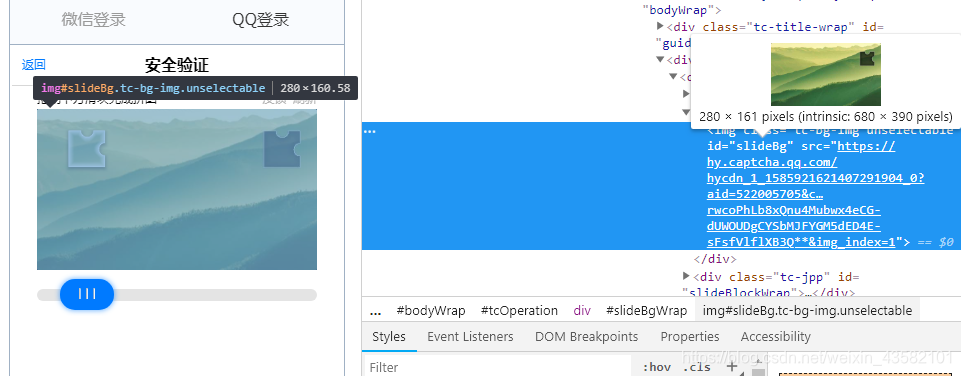
src_big = driver.find_element_by_xpath('//div[@id="slideBgWrap"]/img').get_attribute('src')
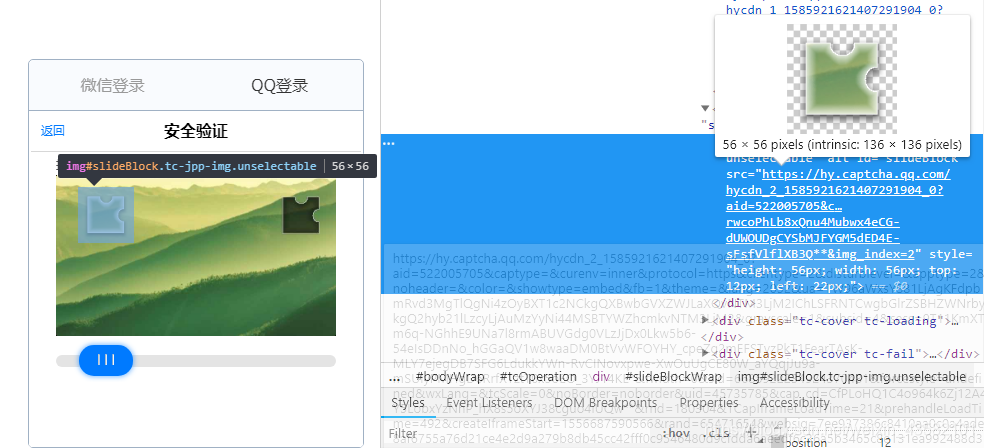
src_small = driver.find_element_by_xpath('//div[@id="slideBlockWrap"]/img').get_attribute('src')
然后保存到本地:
img_big = requests.get(src_big).content
img_small = requests.get(src_small).content
with open('yanzhengtu.jpg','wb') as f:
f.write(img_big)
with open('huakuai.png','wb') as f:
f.write(img_small)
开始识别图片缺口位置:
写一个shibie函数:
def shibie():
otemp = 'huakuai.png' #滑块
oblk = 'yanzhengtu.jpg' # 验证图
target = cv2.imread(otemp, 0) #读入图片
template = cv2.imread(oblk, 0)
w, h = target.shape[::-1] #获取数组转置后的结构
temp = 'temp.jpg'
targ = 'targ.jpg'
cv2.imwrite(temp, template)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
target = cv2.cvtColor(target, cv2.COLOR_BGR2GRAY) #图像颜色空间转换
target = abs(255 - target)
cv2.imwrite(targ, target)
target = cv2.imread(targ)
template = cv2.imread(temp)
result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED) #进行图像模板匹配
x, y = np.unravel_index(result.argmax(), result.shape) #获取一个/组int类型的索引值在一个多维数组中的位置
# 展示圈出来的区域
cv2.rectangle(template, (y, x), (y + w, x + h), (7, 249, 151), 3) #通过对角线画矩形
# print(y)
# show(template)
return y
然后调用我们写好的识别函数:
返回保存在本地的图片中0左标到缺口位置的距离:y
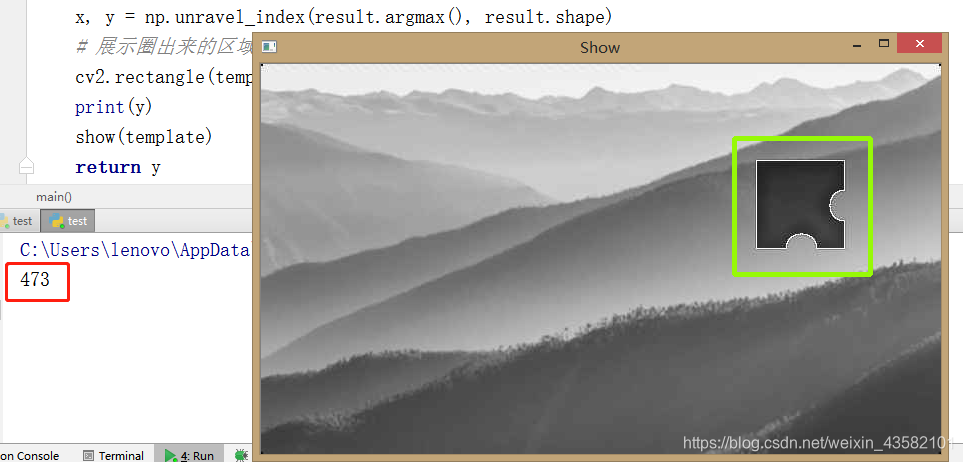
我们本地图片的宽是 680 像素
而QQ邮箱给的验证图的宽为 280 像素
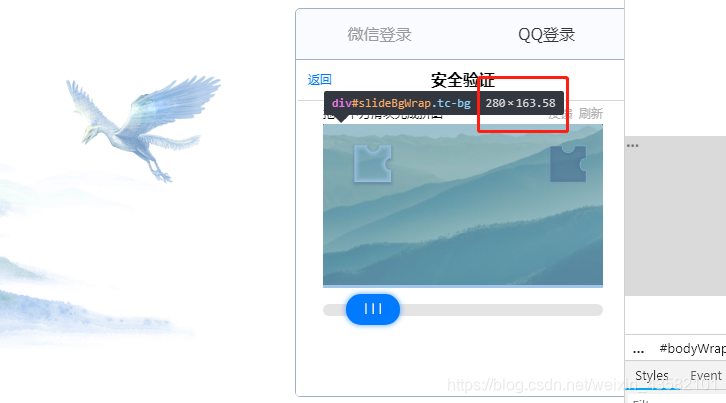
那我们移动的距离是: y = y/(680/280)
但是在浏览器上面显示的滑块起始位置不是为0的。
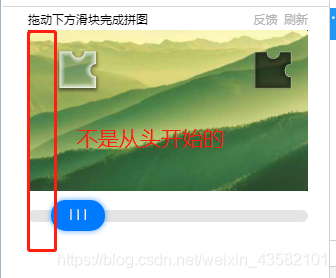
所以我们移动的距离应该是: y = (y+22.5)/(680/280)+k
当然可能存在有些许误差k,需要我们再观察并补充。
我们就可以使用selenium中的ActionChains来进行鼠标移动操作。
huakuai = driver.find_element_by_id('tcaptcha_drag_thumb')
action = ActionChains(driver)
action.click_and_hold(huakuai).perform()
y = (y+20)/(680/280)-27
try:
action.move_by_offset(y,0).perform()
time.sleep(0.5)
action.release(on_element=huakuai).perform() #松开鼠标左键,完成操作
time.sleep(1)
except:
pass
测试结果:
因为这里发不了视频。我用gif图来演示下:
图质量太烂了、不过不影响看结果。现在已经能识别并正确拖动到位置了。
完整代码:
2022-06-16更新
# -*- coding: utf-8 -*-
import re
from selenium import webdriver
import cv2, numpy as np, random, requests, time
from selenium.webdriver import ActionChains
import warnings
from PIL import Image
warnings.filterwarnings("ignore",category=DeprecationWarning)
from io import BytesIO
huakuai_path = 'huakuai.png'
yanzheng_path = 'yanzhengtu.jpg'
'''识别缺口位置、计算偏移值'''
class SlideCrack(object):
def __init__(self, gap, bg, out=None):
"""
init code
:param gap: 缺口图片
:param bg: 背景图片
:param out: 输出图片
"""
self.gap = gap
self.bg = bg
self.out = out
@staticmethod
def clear_white(img):
# 清除图片的空白区域,这里主要清除滑块的空白
img = cv2.imdecode(np.frombuffer(img,np.uint8), cv2.IMREAD_UNCHANGED)
rows, cols, channel = img.shape
min_x = 255
min_y = 255
max_x = 0
max_y = 0
for x in range(1, rows):
for y in range(1, cols):
t = set(img[x, y])
if len(t) >= 2:
if x <= min_x:
min_x = x
elif x >= max_x:
max_x = x
if y <= min_y:
min_y = y
elif y >= max_y:
max_y = y
img1 = img[min_x:max_x, min_y: max_y]
return img1
def template_match(self, tpl, target):
th, tw = tpl.shape[:2]
result = cv2.matchTemplate(target, tpl, cv2.TM_CCOEFF_NORMED)
# 寻找矩阵(一维数组当作向量,用Mat定义) 中最小值和最大值的位置
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
tl = max_loc
# br = (tl[0] + tw, tl[1] + th)
# 绘制矩形边框,将匹配区域标注出来
# target:目标图像
# tl:矩形定点
# br:矩形的宽高
# (0,0,255):矩形边框颜色
# 1:矩形边框大小
# cv2.rectangle(target, tl, br, (0, 0, 255), 2)
# if self.out:
# cv2.imwrite(self.out, target)
return tl[0]
@staticmethod
def image_edge_detection(img):
edges = cv2.Canny(img, 100, 200)
return edges
def discern(self):
img1 = self.clear_white(self.gap)
img1 = cv2.cvtColor(img1, cv2.COLOR_RGB2GRAY)
slide = self.image_edge_detection(img1)
back = cv2.cvtColor(np.asarray(Image.open(BytesIO(self.bg))), cv2.COLOR_RGB2GRAY)
back = self.image_edge_detection(back)
slide_pic = cv2.cvtColor(slide, cv2.COLOR_GRAY2RGB)
back_pic = cv2.cvtColor(back, cv2.COLOR_GRAY2RGB)
x = self.template_match(slide_pic, back_pic) # 滑块偏移值
# 输出横坐标, 即 滑块在图片上的位置
return x
def get_distance(gap, bg):
"""
计算滑动距离
"""
with open(gap,'rb') as f:
gap = f.read()
with open(bg,'rb') as f:
bg = f.read()
sc = SlideCrack(gap, bg, "33.png")
distance = int(sc.discern() // 2.4)
return distance
'''selenium模拟登陆 获取滑块'''
def main():
driver = webdriver.Chrome(executable_path= r'chromedriver.exe')
driver.get('https://mail.qq.com')
time.sleep(2)
driver.switch_to.frame("login_frame")
try:
driver.find_element_by_id('switcher_plogin').click()
except:
pass
username = '1234567{}@qq.com'.format(random.randint(0, 99))
driver.find_element_by_id("u").send_keys(username)
driver.find_element_by_id("p").send_keys('wwwwwwwww')
time.sleep(2)
driver.find_element_by_id("login_button").click()
time.sleep(2)
frame = driver.find_element_by_id('tcaptcha_iframe_dy')
driver.switch_to.frame(frame)
time.sleep(1)
if driver.find_element_by_id('slideBgWrap'):
time.sleep(0.5)
src_big = driver.find_element_by_id('slideBg').get_attribute('style')
src_big = 'https://t.captcha.qq.com'+''.join(re.findall('(/cap_union_new_getcapbysig\?.*?)"\);',src_big,re.S))
src_small = driver.find_element_by_xpath('//*[@id="tcOperation"]/div[8]').get_attribute('style')
src_small = 'https://t.captcha.qq.com'+''.join(re.findall('(/cap_union_new_getcapbysig\?.*?)"\);',src_small,re.S))
img_big = requests.get(src_big).content
img_small = requests.get(src_small).content
with open(yanzheng_path, 'wb') as f:
f.write(img_big)
with open(huakuai_path, 'wb') as f:
f.write(img_small)
# 切割图片 提取滑块
from PIL import Image
img = Image.open(huakuai_path)
region = img.crop((162, 514, 250, 588)) ## 0,0表示要裁剪的位置的左上角坐标,50,50表示右下角。
region.save(huakuai_path)
y = get_distance(huakuai_path,yanzheng_path)
huakuai = driver.find_element_by_xpath('//*[@id="tcOperation"]/div[6]')
action = ActionChains(driver)
action.click_and_hold(huakuai).perform()
action.move_by_offset(y-30, 0).perform()
action.release(on_element=huakuai).perform()
time.sleep(3)
driver.close()
if __name__ == '__main__':
main()


















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











