







 本文探讨了在数据建模中特征提取的重要性,尤其是无监督学习下特征选择的挑战。作者提出了一种基于向量距离运算的简单有效特征提取方法,通过计算两组数据间的相对距离,对特征进行排序,从而选取关键特征。实验结果显示,该方法能够较好地匹配实际业务场景,并与监督学习算法的特征贡献度相吻合。
本文探讨了在数据建模中特征提取的重要性,尤其是无监督学习下特征选择的挑战。作者提出了一种基于向量距离运算的简单有效特征提取方法,通过计算两组数据间的相对距离,对特征进行排序,从而选取关键特征。实验结果显示,该方法能够较好地匹配实际业务场景,并与监督学习算法的特征贡献度相吻合。
无监督学习下的便捷有效特征提取手段

第一次创作的简单自我介绍
大家好,我叫冯太涛,很高兴认识大家。本人硕士毕业于概率论与数理统计专业,并在数据挖掘、数据建模方面有很大的兴趣。这是我第一次在知乎这类平台写作文章,在未来我会利用此平台跟大家分享和交流一些我在挖掘实践中的一些心得。这些心得都是从自己的认识出发并加以实践得出,仅一家之言,目的是抛砖引玉,以期各位添彩,相互取长补短!
PS:这是本人在知乎平台地址,望朋友们多多支持和交流!O(∩_∩)O哈哈~

前言
数据特征的提取在数据建模中是举足轻重的地位,往往监督学习提取特征需要理解算法的底层含义才能运用的得心应手,降维算法得到的主成分只是原始数据的线性组合,不容易观察具体的筛选特征。鉴于此,本文核心利用向量距离运算设计了一种便捷有效特征的筛选方法。
一:数据特征介绍
机器学习工程,其本质就是特征工程,数据工程上的 “特征” ,对应数学上叫 “变量” 或者 “维” ,统计上可以称为 “属性” 。对于特征的有关任务,在数据建模分析中可谓是非常重要的内容。在海量数据维度中如何提取明显的有效特征,一直是个棘手热门问题。如果处理好,那对后面的具体建模起到事半功倍的效果。
- 具体场景介绍
在生产实践中,如医学上关于健康人群和高血压人群,究其原因是两种人群在相关蛋白质表达量的差异性造成的,这么多蛋白种类到底哪些蛋白在这两组人群中是有差异性甚至特异性的,这就涉及差异蛋白质的提取;又比如在信用卡逾期分析方面,哪些因素导致违约概率大?是负债,学历,还是收入等等,如果我们能找到其中的非常敏感的特征,对后面违约情况的预测建模会起到很重要的作用,这不仅降低了计算机计算资源,同时能有效降低模型的过拟合情况,提高模型的泛化能力。
- 简单概括常见特征提取方法
监督学习:回归模型,Xgboost,随机森林(决策树)等等。
无监督:相关性分析、方差性分析,常见降维技术(Pca,Kpca,Tsne)等等。
二:常见方法的简单分析
在初始学习机器学习算法中,如果想深入理解和深度运用,相应的数学知识是必不可少的,如加权最小二乘法,信息熵,条件期望,马尔科夫过程,傅里叶变换等等等等,所以运用高级算法提取特征“门槛”比较高;运用降维技术往往得到的是跟原始数据有关的线性组合结果,不是很明了具体涉及的哪些特征是真的需要剔除和保留的;关于“低方差高相关性”的特征提取,意思是组内低方差的维度数据剔除,组间高相关的维度数据剔除,这往往是一种“后验检验”意义的存在,举个栗子某两组人员收入为 V 1 = [ 1 , 2 , 3 , 4 , 5 , 6 ] , V 2 = [ 100 , 200 , 300 , 400 , 500 , 600 ] , V1=[1,2,3,4,5,6],V2=[100,200,300,400,500,600], V1=[1,2,3,4,5,6],V2=[100,200,300,400,500,600],元素值差了100倍,直观上“差异性”很大,应该保留此特征,因为很好区分了低收入和高收入,但相关值计算都是1,高相关性要求我们剔除这一特征数据。方差分析同样也有此问题存在。
print(v1.corr(v2,method='pearson'))### 1
print(v1.corr(v2,method='kendall'))### 1
print(v1.corr(v2,method='spearman'))### 1
df = pd.DataFrame([v1,v2])
print(cosine_similarity(df))### [1,1;1,1]
三:基于距离运算的便捷有效特征提取方法
鉴于以上分析,本文基于向量间距离运算,提出一种易理解易实现且有实际效果的方法来解决数据特征提取问题。本文先只涉及两组数据间且不涉及异常点情况的有效特征提取,同时会联系监督算法和实际结果做综合分析。
- 具体分析步骤如下:
-
当两组数据样本量相等时,设样本 A A A和 B B B是 m ∗ n m*n m∗n, m m m是样本量大小, n n n是维度大小,两组数据第 i i i个特征之间距离定义为
D ( A i , B i ) = ( ∑ j = 1 m ∣ A i j − B i j ∣ p ) 1 p , p ∈ Z + , D(A_i,B_i)=(\displaystyle\sum_{j=1}^{m} |A_{ij}-B_{ij}|^p)^\frac{1}{p},p \in Z^+, D(Ai,Bi)=(j=1∑m∣Aij−Bij∣p)p1,p∈Z+, -
由于维度数据存在数据量级的差异,我们把距离映射在 [ 0 , 1 ] [0,1] [0,1]之内。设样本内第 i i i维数据之和 S A i = ∑ j = 1 m A i j , S B i = ∑ j = 1 m B i j , S_{Ai}=\displaystyle\sum_{j=1}^{m}A_{ij},S_{Bi}=\displaystyle\sum_{j=1}^{m}B_{ij}, SAi=j=1∑mAij,SBi=j=1∑mBij,它们中的大值设为 M a x i , Max_i, Maxi,小值设为 M i n i , Min_i, Mini,设修正数 R i = w ∗ M a x i + ( 1 − w ) ∗ M i n i , R_i=w*Max_i+(1-w)*Min_i, Ri=w∗Maxi+(1−w)∗Mini,权重 w w w的选择会让修正值有偏向,
-
最终相对距离 R D ( A i , B i ) = D ( A i , B i ) / R i , RD(A_i,B_i)=D(A_i,B_i)/R_i, RD(Ai,Bi)=D(Ai,Bi)/Ri,
-
对最终相对距离值进行排序,进而得出哪些特征排名靠前,根据需求选取排名靠前的特征。
(PS:)当两组数据样本量不等时,以少量数据样本为参考,在多的数据样本中随机取量,以达到两组向量长度相等,这里可以参考机器学习常用的训练集和测试集划分方法:
from sklearn.model_selection import train_test_split
A = train_test_split(A, test_size=B.shape[0]/A.shape[0], random_state=311)
四:实验验证
本文设计了两个实验来说明此方法的简便有效。
- 手动设计验证数据集如下图1,此数据集有6个特征,其中索引0-7为第一组数据
A
A
A ,8-15为第二组数据
B
B
B,都是8组数据。
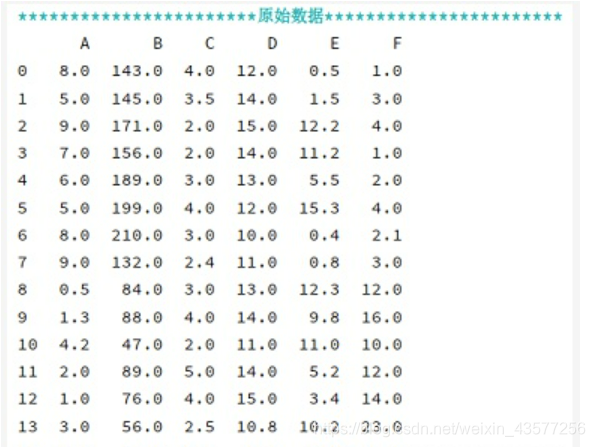
图1
先可视化这些数据分布如下图2,在图2中,很明显发现特征A、B、F在两组中表现异常于剩下3个特征。
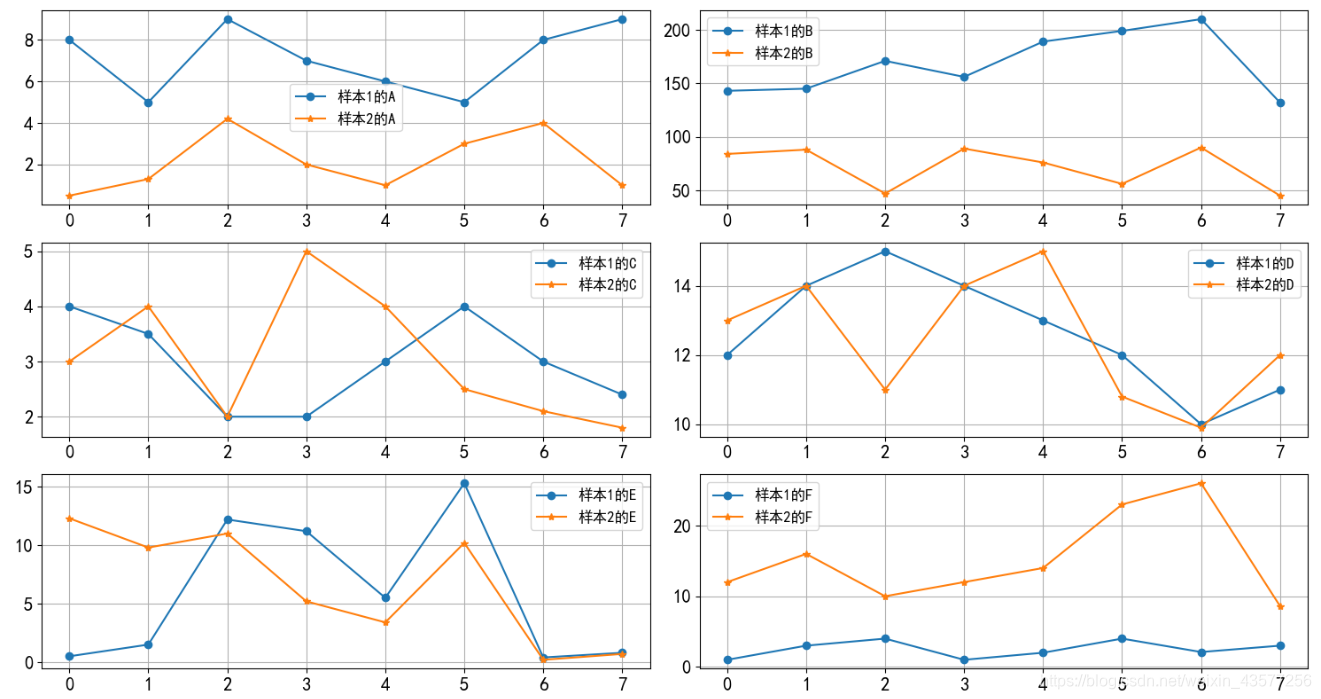
接着我们基于第三节步骤设计代码(节选)来计算验证。
import pandas as pd
import numpy as np
import pylab as mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif']=['SimHei']##中文乱码问题!
plt.rcParams['axes.unicode_minus']=False#横坐标负号显示问题!
def basedist(v1,v2,w,n=4):
...
dist = np.power(sum(np.power(d_t,n)),1 / n)
dfdist = pd.DataFrame([absdist ,reldist.tolist()[0]],index=['绝对距离','相对距离']).T
...
print(v1.columns[sort_id])
basedist(df1,df2,0.4)
*********************距离运算法结果**********************
绝对距离 相对距离
0 15.065855 0.519512
1 285.975523 0.354808
2 3.830144 0.159258
3 4.842520 0.048382
4 16.614452 0.338932
5 39.428036 0.779981
最后按照特征在两组数据表现的差异性降序结果为:['F', 'A', 'B', 'E', 'C', 'D']
为了提高计算效率,所有涉及运算的代码尽量使用矩阵运算代替for循环运算。从程序运算结果可以看出,排名前3的属性特征确实符合图2展示的结果,从实际意义出发,我们选择特征’F’, 'A’和’B’就能完全区分两组数据。
- 如下图3(节选)是关于人群银行卡违约的实际数据,其中涉及8个有效维度数据(剔除了姓名、血型等等无关属性数据),违约0代表不违约人群,1代表违约人群,但这两组人群人数并不相等,违约人群数是180,不违约涉及500人。
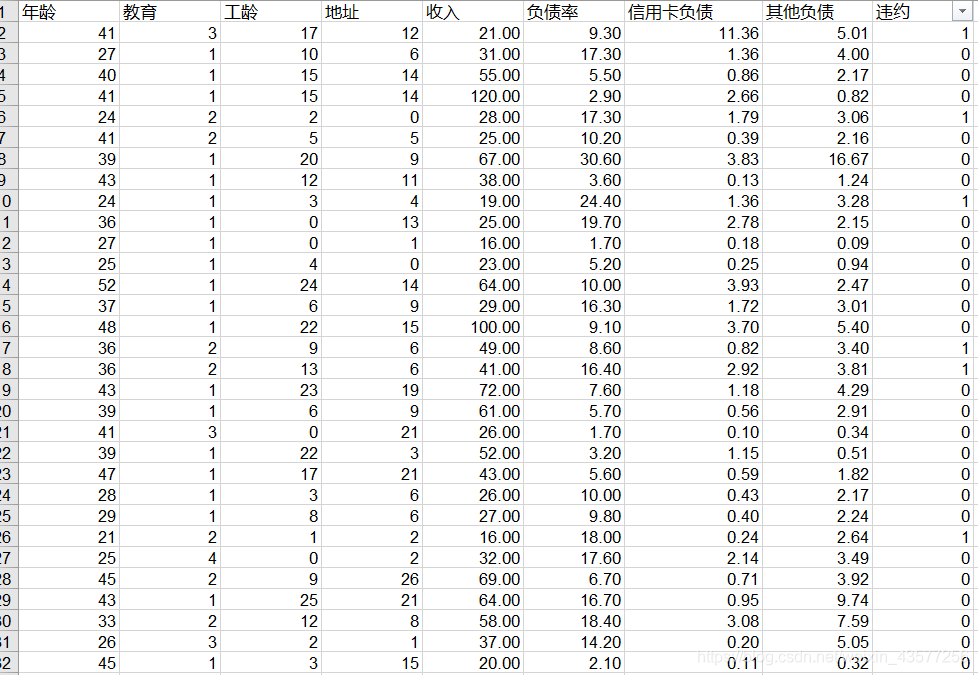
df1 = data_loan[data_loan.违约 == 0]
df2 = data_loan[data_loan.违约 == 1]
print(len(df1),len(df2))###500,180
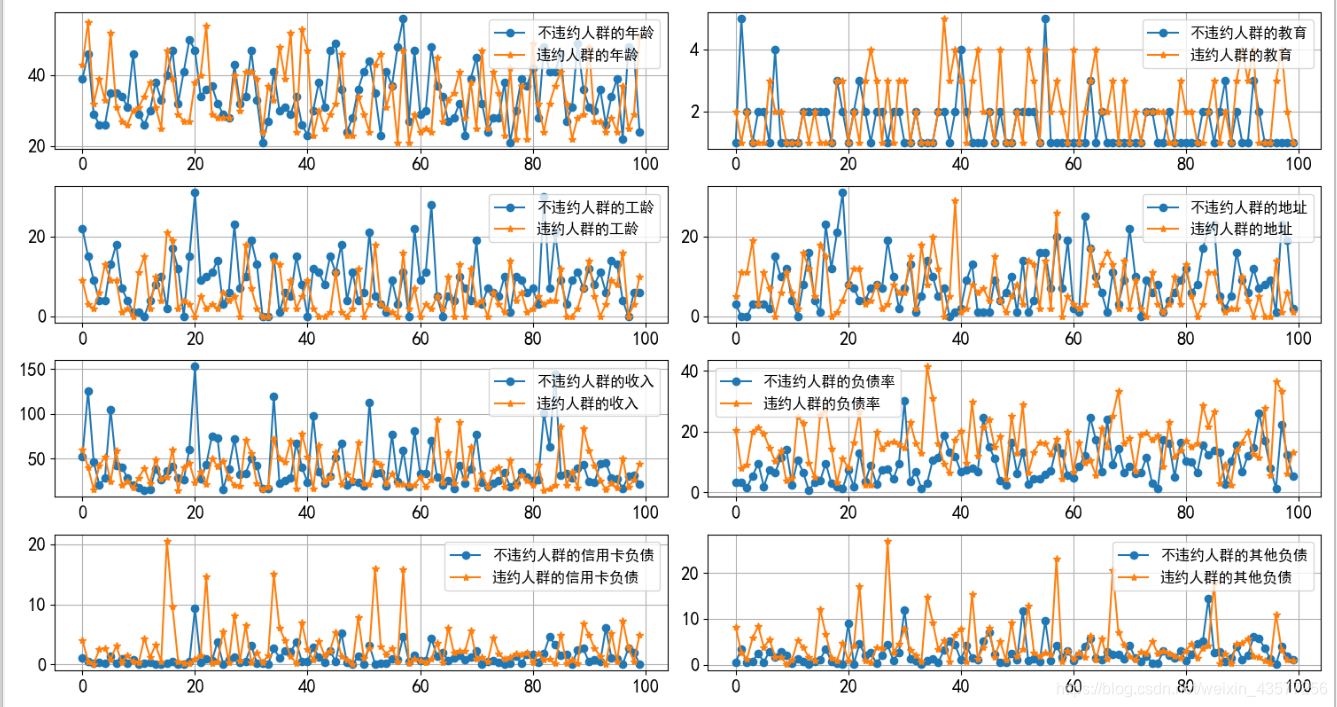
由于数据量比较多,从随机选取的样本中我们直观能感受到 “信用卡负债”、“其他负债”,**“工龄”**等会是比较明显区分两种人群的特征属性。同理再用程序观察计算结果,在不违约人群中随机选取180个数据,保持两组人群数量一致,然后调用basedist函数得到如下结果
绝对距离 相对距离
0 37.316390 0.006141
1 4.183467 0.013447
2 34.922718 0.034986
3 30.069817 0.024849
4 177.749433 0.027302
5 35.735796 0.020763
6 20.915434 0.082989
7 27.495856 0.052101
降序排序结果:['信用卡负债', '其他负债', '工龄', '收入', '地址', '负债率', '教育', '年龄']
从计算结果上看,跟我们主观得到的印象比较符合,尤其是 “年龄” 特征,在图中两组数据目测观察重合度还是比较高的,很难作为敏感特征来区分两种人群。
由于图3展示的带标签数据,我们用监督算法观察相应的特征贡献度是否和我们上面分析的结果相似,我们选取其中的随机森林(RF)算法(本文暂不涉及算法底层推导和参数解释),从机器学习库调取RF模型,选择分类预测方法。
from sklearn import ensemble
itrees = 200
depth = None
maxfeat = 8
res = ensemble.RandomForestRegressor(n_estimators=itrees,max_depth=depth,max_features=maxfeat,oob_score=False,random_state=233)
res .fit(x1,x2)
featureimportance = winerfm.feature_importances_
featureimportance = featureimportance / featureimportance.max()
sort_id = np.argsort(-featureimportance)
print(x1.columns[sort_id])
降序排序结果:[ '信用卡负债', '工龄','负债率', '其他负债','地址', '教育', '收入', '年龄']
从结果上分析,监督算法结果跟我们以上分析出入不大,明显特征都涉及“信用卡负债”,“工龄”和“其他负债”,在“教育”和“年龄”上,都认为是不敏感特征(看来相关负债情况对违约影响蛮大的,不在乎是否是年轻人还是中年人,哈哈哈!)比较有争议的是特征是“负债率”,所以最终的特征选择也许还要结合实际业务场景。
五:总结
本文涉及的方法原则是便捷有效,但还是会涉及一些问题:
- 本方法暂时是处理二分类问题,对多组数据(多分类)问题如何制定规则选取它们的共同敏感特征来区分它们?
- 如果数据样本中涉及异常点怎么处理来加强此方法的鲁棒性?

















 2037
2037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









