







1 背景
虽然AB测试(AB实验)的统计基础已经有一个世纪的历史了,但大规模地构建一个正确可靠的A/B测试平台仍然是一个巨大的挑战:不仅要在实验设计环节应对溢出效应和小样本的双重挑战,平衡好实验偏差与方差以确定合适的实验单元、分组方法和分析方法,给出合理的实验设计,而且要在分析环节应对方差计算、P值计算、多重比较、混淆因素、假阴性(实际策略有效果,但是检测显示无效果)等多种统计陷阱。因此,要获得高质量的结果需要对实验和统计有专家级的理解,这无疑增加了实验门槛,难以达成任何人进行实验都可得出可信结论的目标。
本文将从实验方法和平台建设的两个视角,分别介绍如何正确地使用统计方法避免统计陷阱,以及输出什么样的平台能力,从而确保任何人使用该平台时都可得出可信结论。同时,我们也积累了如何进行更好的实验,以及如何利用实验来做出更好的决策,希望能给从事相关工作的同学有所帮助,也真诚地希望欢迎大家给出反馈或者建议,不断优化我们的工作。
2 走进AB测试
哪个线上选项会更好?我们经常需要做出这样的选择。当我们想要在两个策略之间做出决定时,理想的方案是面向同一拨用户,在两个平行时空,平行时空1体验原策略A,平行时空2体验新策略B,然后根据观测到的事实进行比较,以决定哪个策略胜出。然而在现实世界中,不存在两个平行时空,针对同一用户,我们只能观察到其接受策略A或策略B的一种效果,即反事实结果是观测不到的。
因此,在现实世界中,我们通常采用实验的方法做出决策。它将用户分配到不同的组,同一组内的用户在实验期间使用相同的策略,不同组的用户使用不同的策略。同时,日志系统根据实验系统为用户打标记,用于记录用户的行为,然后根据带有标记的日志计算度量差异,并进行统计分析以排除由于噪声导致的任何差异。实验者通过这些指标去理解和分析不同的策略对用户起了什么样的作用,是否符合实验预先假设。
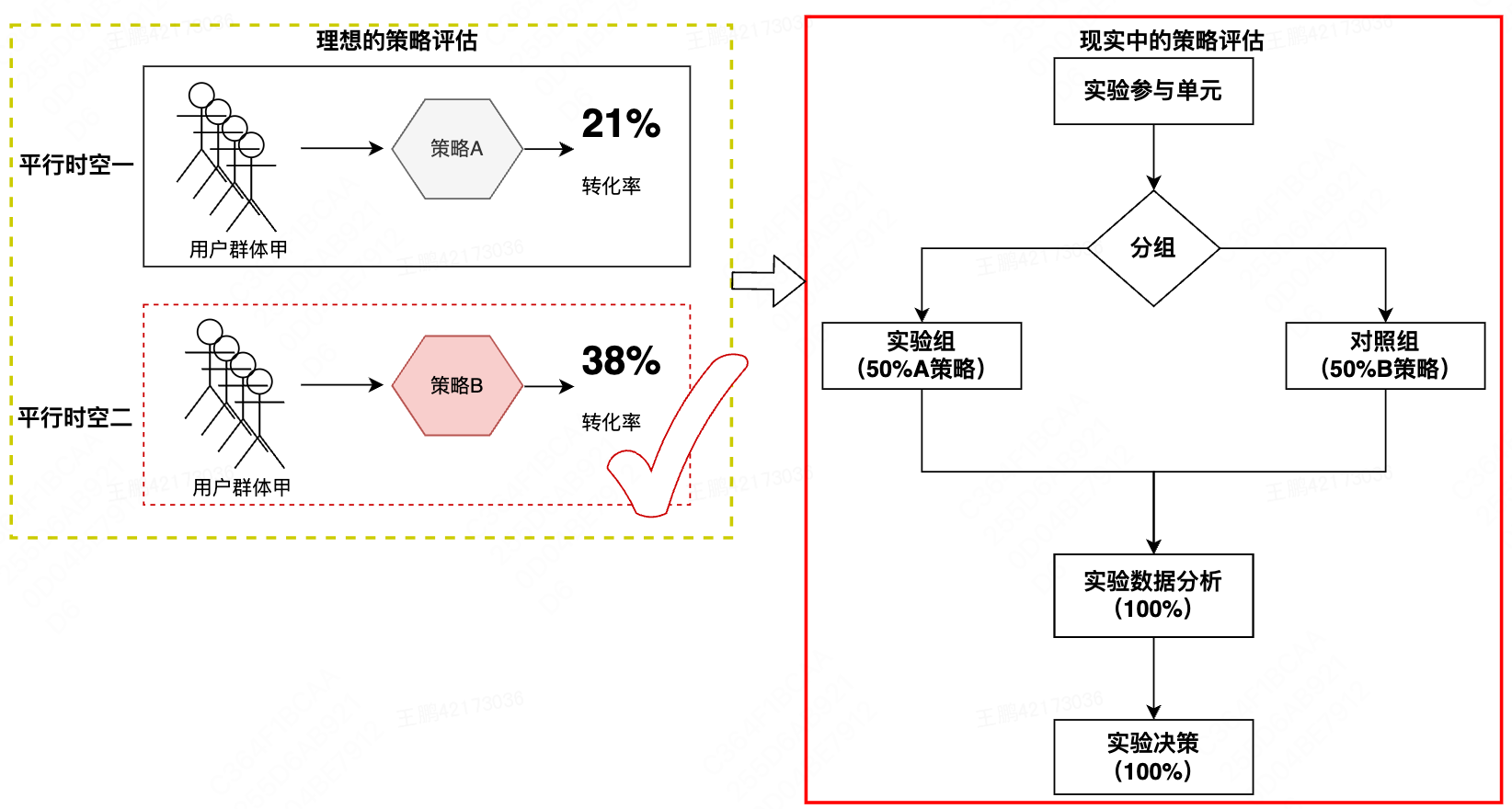
图1 理想和现实中的策略评估
2.1 AB测试概述
实证中由于不可能同时观测到同一群体在不同策略下的两种潜在结果,无法决定哪个策略胜出,需要构建一个反事实(Counterfactual)用来代表接受策略B的群体在接受A策略时的潜在结果。
具体来讲,构建一个与实验组群体特征均值无差异的对照组,用其观测结果代表实验组群体在施加A策略时的潜在结果,此时两种结果的均值差便是策略效应大小。由于是基于样本的观测数据得出的结论,需要通过显著性分析(Significance Test),以证明结论具有统计意义,这便是策略评估的完整路径。
根据能否在实验前控制策略的分配,我们将实验分为AB实验和观察性研究(Observational Studies),在AB实验分支下,根据能否控制策略的随机分配,又将AB实验分为随机对照实验(Randomized Experiments)和准实验(Quasi Experiments)。不同的实验类型使用不同的分组方法,在一定程度上影响着实验后分析数据的表现形式,实验后选择与实验类型匹配的分析方法尤为重要,直接制约着我们能否统计意义上的科学结论。具体分类如下:
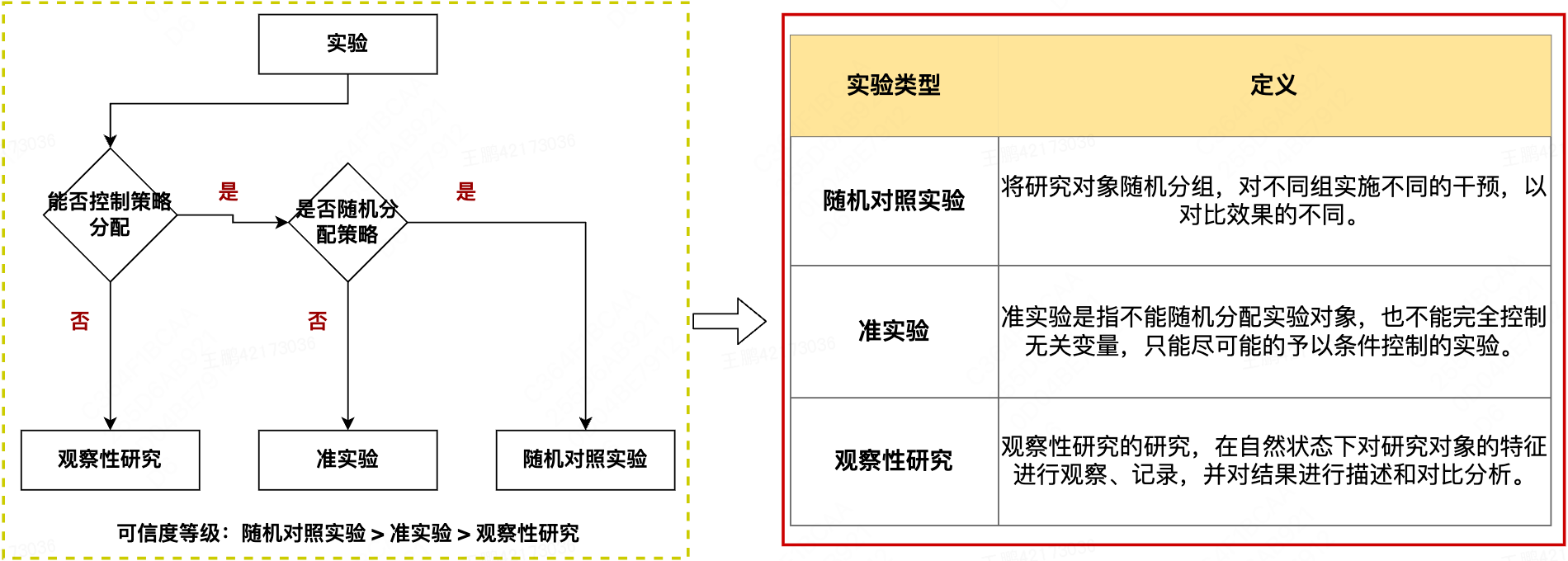
图2 履约业务下的三种实验类型
对于大部分的实验场景,我们可以在实验前控制对不同的实验对象分配不同的策略,然而在有些场景下,如:①测试线上演唱会活动对短视频平台的影响,考虑到用户公平,需要给全部用户施加演唱会活动策略;②在测试不同的营销邮件策略对用户影响的场景中,我们无法控制哪些用户会最终接受策略。我们要么不能控制策略分配,要么不能控制策略在对应的人群生效,只能采用观察性研究,即在自然状态下对研究对象的特征进行观察、记录,并对结果进行描述和分析。
在我们可以控制对实验对象施加策略的场景,如①测试不同的产品UI对用户的影响,进而决定使用哪种UI;②快速验证首页商品列表图素材对转化率的影响。这些典型的C端实验场景,不仅有海量用户且用户在实验组、对照组间的行为不会相互影响,可以通过随机分组的方式找到同质且独立的实验组和对照组,这类实验称之为随机对照实验,是业界衡量策略效应的黄金标准。
然而在美团履约业务场景中,如调度场景,要测试不同的调度策略对区域内用户体验的影响,策略施加单位是区域,由于区域数量少,同时区域之间各项指标(商家、运力、消费者)差异较大,采用随机分组难以得出同质的实验组、对照组,而且由于区域之间可以共享运力,施加不同策略的实验组、对照组区域之间相互影响,不满足实验单位独立的条件。在这种场景下,我们不能对实验对象进行随机分配,只能有选择的进行实验组和对照组的分配,这种虽然能够控制策略分配但不能控制策略随机分配的实验,我们称之为准实验,常用的准实验方法如双重差分。
随机对照实验,因为其能够保证实验组、对照组两组的特征均值相同,不会因为分组差异干扰对真实效应的衡量,是业界衡量策略效应的黄金标准。在不满足随机对照实验约束的业务场景下衡量策略效应,我们采用准实验的方法,通过改进分组方法消除实验组、对照组可观测特征的差异或使其保持恒定差异,分析环节采用适配准实验场景的分析方法。
如果由于场景约束,只能基于实验后得到的数据来进行实验的话,就只能采用适用于观察性研究的方法。准实验和观察性研究虽然不是衡量策略效应的金标准,但是如果使用得当,也可以得出相对科学可信的分析结论。在学界,三种不同实验类型的可信度等级如下:
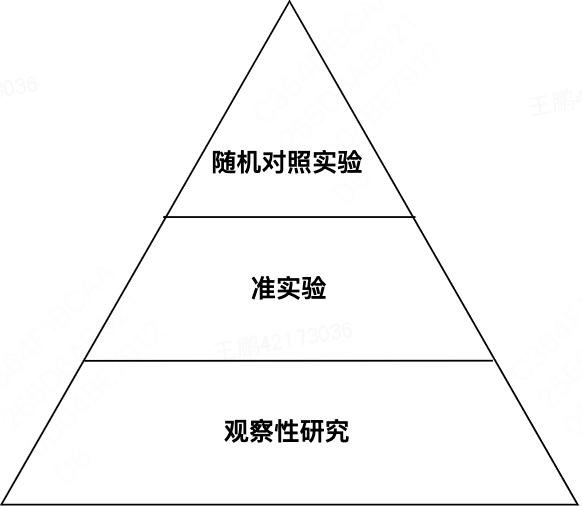
图3 用于评估AB测试质量的可信度等级
2.2 AB测试的关键问题
不管何种类型的AB实验,都符合分流->实验->数据分析->决策的基本流程,以及需要满足AB实验的3个基本要素。分流是实验平台的顶层设计,它规范和约束了不同实验者如何在平台上独立运行各自实验而不相互影响,运行实验,看似简单,但是成功运行不同类型实验的前提是实验场景要满足其理论假设。
AB实验主要是通过观察抽样的样本来推断总体的行为,属于预测型结论,数据分析涉及大量的统计学理论,稍有不慎,容易掉入统计陷阱。上述流程,任一环节出错,都可能导致错误的结论,因此,AB实验统计一个数字容易,得到可靠可信的统计结论并不容易。
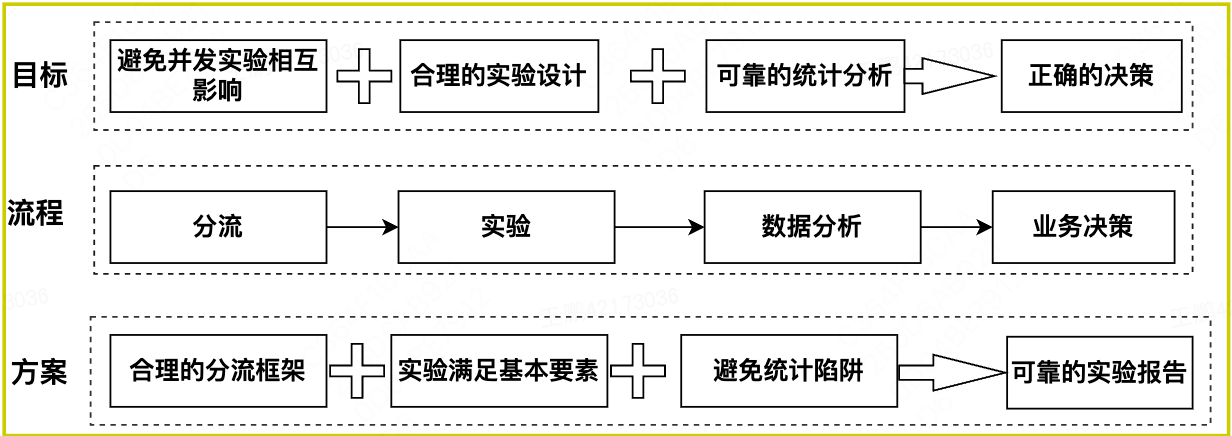
图4 构建可信AB测试的关键要素
2.2.1 AB测试的分流框架
在履约技术平台,我们通过实验衡量真实的用户反应,以确定新产品功能的效果,如果无法同时运行多个并行实验,将会大大减慢迭代速度。扩大同时运行实验的数量对于实现更快的迭代是必不可少的。为了增加可以同时运行的实验数量,提高并行性,并允许同时运行多个互斥实验,业界出现了两种分流框架,一种是像谷歌、微软、脸书这种单边业务形态的公司,采用层、域嵌套的分流框架;另一种是像Uber、DoorDash这种多边业务形态的公司,采用基于约束的分流框架。具体如下图所示:
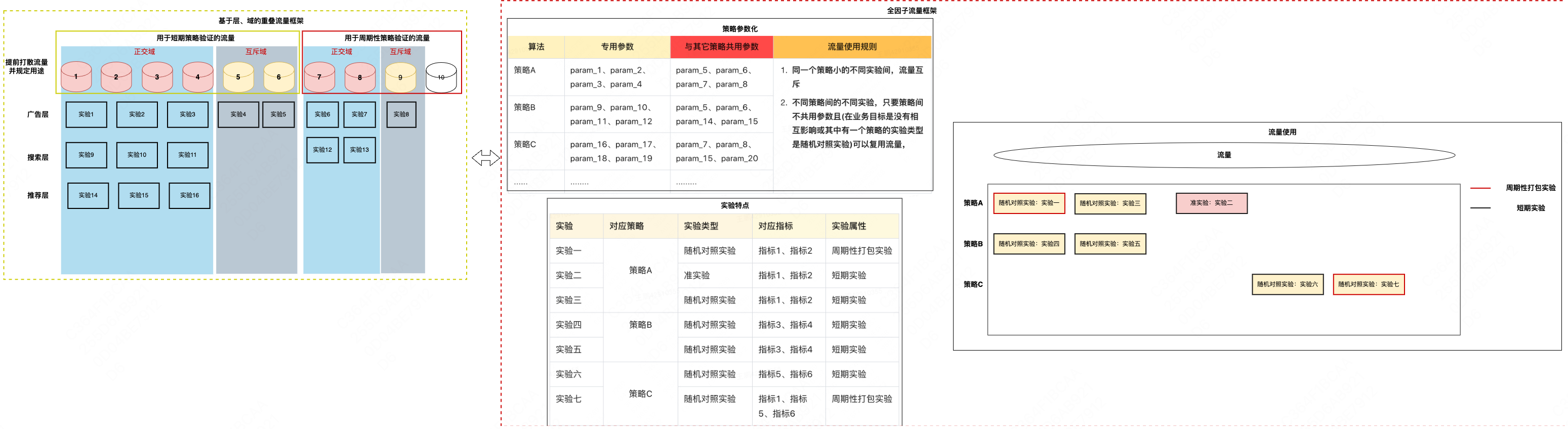
图5 业界流行的两种分流框架
基于层、域嵌套的重叠分流框架<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











