







 本文介绍了Selenium的基本使用,包括环境配置、驱动安装、浏览器自动化操作实例,如打开高德地图获取经纬度,以及在京东搜索后的页面元素定位。详细讲解了如何通过id、name和class属性查找并操作页面元素。
本文介绍了Selenium的基本使用,包括环境配置、驱动安装、浏览器自动化操作实例,如打开高德地图获取经纬度,以及在京东搜索后的页面元素定位。详细讲解了如何通过id、name和class属性查找并操作页面元素。
Selenium是一个用电脑模拟人操作浏览器网页,可以实现自动化,用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
环境:
windows
python3.8
谷歌浏览器
安装
pip install selenium
安装驱动
以谷歌浏览器为例:
https://sites.google.com/a/chromium.org/chromedriver/downloads
地址栏输入:Chrome://version,查看浏览器版本并下载相应版本,同时我们也可以看到浏览器的安装路径,下面会用到:
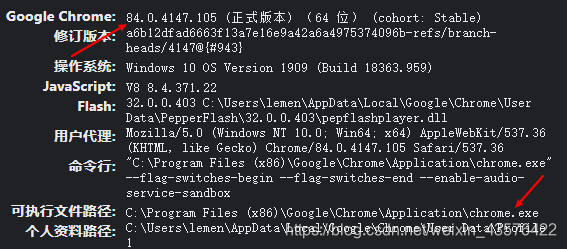
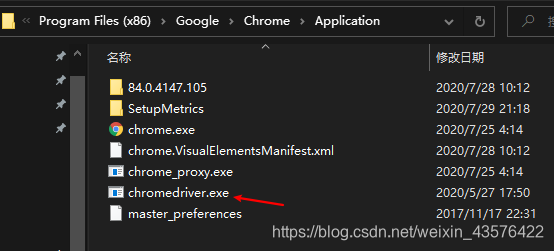
解压得到一个chromedriver.exe文件,将其放置在浏览器的安装目录之下
根据上面得到路径是(“C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe”)
其他浏览器:
edge(新版,旧版):https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
火狐:https://github.com/mozilla/geckodriver/releases
实例
下面是模拟浏览器的操作,打开高德地图,获取相应城市的经纬度。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pyperclip #实现粘贴
city = [
'北京',
'广州',
'上海',
'乌鲁木齐'
]
data = []
browser = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
#打开谷歌浏览器
for i in city:
browser.get("https://lbs.amap.com/console/show/picker") #打开网页
inputLocation=browser.find_element_by_xpath('//*[@id="txtSearch"]') #定位输入框
inputLocation.send_keys(i) #输入城市名称
inputLocation.send_keys(Keys.ENTER) #使用回车代替“点击搜索”
copylocation=browser.find_element_by_xpath('//*[@id="myPageTop"]/table/tbody/tr[2]/td[2]/a')
#定位复制按钮
copylocation.send_keys(Keys.ENTER)#回车复制
copylocation.click() #点击复制也是可以的
time.sleep(1) #避免操作过快,复制后暂停1秒
result = pyperclip.paste() #粘贴复制的经纬度数据
print(result) #打印出来监控数据是否正常
data.append(result) #存到列表
browser.close() #关闭浏览器
运行结果:

案例2-获取京东搜索页面后的页面代码
(1)打开浏览器
(2)找到搜索框,输入字符串,点击enter
(3)等待搜索页面显示
(4)或者页面特定内容
其中等待搜索结果显示可以通过F12查看搜索商品结果的元素是什么:这里是id=“J_main”

完整代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
browser = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
try:
#打开京东首页
browser.get('https://www.jd.com')
#根据id属性id='key'查找搜索框
input = browser.find_element_by_id("key")
#发送文本
input.send_keys('python')
#按下enter键
input.send_keys(Keys.ENTER)
#创建webDriverWait对象,最长等待4秒
wait = WebDriverWait(browser,4)
#等待搜索页面显示,查找是否出现//*[@id="J_main"]/div[1]
'''Expected Conditions的使用场景有2种
直接在断言中使用
与WebDriverWait配合使用,动态等待页面上元素出现或者消失
presence_of_element_located: 判断某个元素是否被加到了dom树里,并不代表该元素一定可见
'''
locator = (By.ID,"J_main")
wait.until(ec.presence_of_all_elements_located(locator))
print(browser.title)
#显示搜索页面的代码
print(browser.page_source)
browser.close()
except Exception as e:
print(e)
browser.close()
运行结果:
下面是获取的部分HTML,可以利用xpath或者beautifulsoup提取需要的数据:
<div class="p-price">
<strong class="J_12353915" data-done="1">
<em>¥</em><i>69.80</i>
</strong>
</div>
<div class="p-name">
<a target="_blank" title="Python3全新升级!超20万读者认可的彩色书,从基本概念到完整项目开发,助您快速掌握Python编程。全程视频+完整源码+215道课后题+实物魔卡+海量资源" href="//item.jd.com/12353915.html" onclick="searchlog(1, '12353915','1','1','','flagsClk=2097626');">
<em>零基础学<font class="skcolor_ljg">Python</font>(全彩版)京东专享 实物魔卡</em>
<i class="promo-words" id="J_AD_12353915">Python3全新升级!超20万读者认可的彩色书,从基本概念到完整项目开发,助您快速掌握Python编程。全程视频+完整源码+215道课后题+实物魔卡+海量资源</i>
</a>
</div>
<div class="p-bookdetails">
<span class="p-bi-name" onclick="searchlog(1,0,0,63)">
<a title="明日科技(MingRi Soft)" href="/search?author=%E6%98%8E%E6%97%A5%E7%A7%91%E6%8A%80%EF%BC%88MingRi%20Soft%EF%BC%89" target="_blank">明日科技(MingRi Soft)</a>
著 |
</span>
<span class="p-bi-store" onclick="searchlog(1,0,0,64)">
<a title="吉林大学出版社" href="/search?publisher=%E5%90%89%E6%9E%97%E5%A4%A7%E5%AD%A6%E5%87%BA%E7%89%88%E7%A4%BE" target="_blank">吉林大学出版社</a>
|
</span>
<span class="p-bi-date">2018-04</span>
</div>
<div class="p-commit" data-done="1">
<strong><a id="J_comment_12353915" target="_blank" href="//item.jd.com/12353915.html#comment" onclick="searchlog(1, '12353915','1','3','','flagsClk=2097626');">8.1万+</a>条评价</strong>
</div>
<div class="p-shopnum" data-dongdong="" data-selfware="1" data-score="5" data-reputation="99" data-done="1">
<a class="curr-shop hd-shopname" target="_blank" onclick="searchlog(1,'1000117165',0,58)" href="//mall.jd.com/index-1000117165.html?from=pc" title="明日科技京东自营旗舰店">明日科技京东自营旗舰店<b class="im-02" style="background:url(//img14.360buyimg.com/uba/jfs/t26764/156/1205787445/713/9f715eaa/5bc4255bN0776eea6.png) no-repeat;" title="联系客服" onclick="searchlog(1,1000117165,0,61)"></b></a>
</div>
<div class="p-icons" id="J_pro_12353915" data-done="1">
<i class="goods-icons J-picon-tips J-picon-fix" data-idx="1" data-tips="京东自营,品质保障">自营</i>
<i class="goods-icons4 J-picon-tips" style="border-color:#4d88ff;color:#4d88ff;" data-idx="1" data-tips="品质服务,放心购物">放心购</i>
<i class="goods-icons4 J-picon-tips" data-tips="本商品可领用优惠券">券148-5</i>
</div>
<div class="p-operate">
<a class="p-o-btn focus J_focus" data-sku="12353915" href="javascript:;" onclick="searchlog(1, '12353915','1','5','','flagsClk=2097626')"><i></i>关注</a>
<a class="p-o-btn addcart" href="//cart.jd.com/gate.action?pid=12353915&pcount=1&ptype=1" target="_blank" onclick="searchlog(1, '12353915','1','4','','flagsClk=2097626')" data-limit="0"><i></i>加入购物车</a>
</div>
</div>
<div class="tab-content-item">
查找节点
本例使用selenium通过id属性、name属性、class属性获取表弟中的特定的input节点,并自动输入表单内容。
为了演示这个例子,编写了一个静态的表单页面:
然后将这个demo.html放在任何一台HTTP服务器上(如nginx、apache、IIS)。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>表单</title>
</head>
<body>
<script>
function onclick_form(){
alert(document.getElementById('name').value +
document.getElementById('age').value +
document.getElementsByName('country')[0].value +
document.getElementsByClassName('myclass')[0].value)
}
</script>
姓名:<input id="name"><p></p>
年龄:<input id="age"><p></p>
国家:<input name="country"><p></p>
收入:<input class="myclass"><p></p>
<button onclick="onclick_form()">提交</button>
</body>
</html>

以find_element开头的方法用于查找符合条件的第一个节点
以find_elements开头的方法用于查找多个节点,返回一个列表,包含所有符合条件的节点
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome("C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
try:
#这里改成你的相应的链接
browser.get('http://honigribs.top/resume/demo.html')
#通过id属性查找姓名iput节点
input = browser.find_element_by_id('name')
#自动输入 张三
input.send_keys('张三')
input =browser.find_element_by_id('age')
input.send_keys('30')
#通过name属性查找年龄inpout节点
input = browser.find_element_by_name('country')
input.send_keys('中国')
#通过class属性查找input节点
input = browser.find_element_by_class_name('myclass')
input.send_keys('5000')
#使用find_element方法和class属性再次找收入input节点
input = browser.find_element(By.CLASS_NAME,'myclass')
#先清空原来的输入,再覆盖写
input.clear()
input.send_keys('10000')
time.sleep(3)
browser.close()
except Exception as e:
print(e)
browser.close()

不管查找单个还是多个节点,都有两类方法
一类以 find_element 或find_elements 开头的方法
另一类是 find_element()或者find_elements方法



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









