







 HBase是一个开源的、分布式、面向列的NoSQL数据库,基于Hadoop的HDFS,提供高可靠性、高性能、可伸缩的数据存储。它源于Google的Bigtable,适合非结构化数据存储。HBase具有列存储、稀疏性、扩展性强和高可靠性等特点,适用于大规模数据实时处理。其数据模型由行、列族和时间戳组成,支持多版本数据。
HBase是一个开源的、分布式、面向列的NoSQL数据库,基于Hadoop的HDFS,提供高可靠性、高性能、可伸缩的数据存储。它源于Google的Bigtable,适合非结构化数据存储。HBase具有列存储、稀疏性、扩展性强和高可靠性等特点,适用于大规模数据实时处理。其数据模型由行、列族和时间戳组成,支持多版本数据。
文章目录
简介
HBase 是一个开源的、分布式、版本化、高可靠、高性能、面向列、可伸缩的NoSQL 数据库(也即非关系型数据库),它利用 Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)提供分布式数据存储。
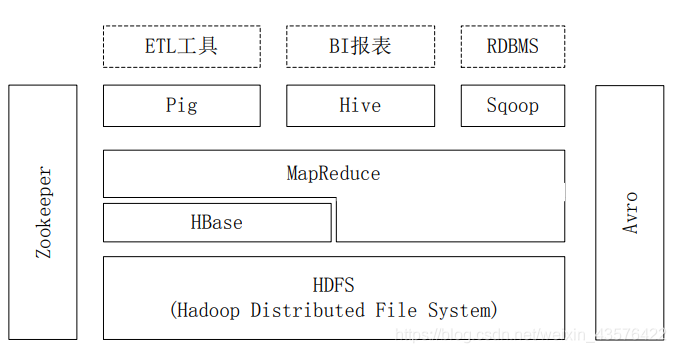
与传统的关系型数据库类似,HBase 也以表的形式组织数据,表也由行和列组成;不同的是,HBase 有列族的概念,它将一列或者多列组织在一起,HBase 的每一个列都必须属于某个列族。但HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase的运行有三种模式:单机模式、伪分布式模式、分布式模式。
- 单机模式:在一台计算机上安装和使用HBase,不涉及数据的分布式存储;
- 伪分布式模式:在一台计算机上模拟一个小的集群;
- 分布式模式:使用多台计算机实现物理意义上的分布式存储。这里出于学习目的,我们只重点讨论单机模式和伪分布式模式。
HBase 的发展历程
HBase 作为 Apache 基金会的 Hadoop 项目的一部分,使用 Java 语言实现,将 HDFS 作为底层文件存储系统,在此基础上运行 MapReduce 进行分布式的批量处理数据,为 Hadoop 提供海量数据管理的服务。
Apache HBase 最初是 Powerset 公司为了处理自然语言搜索产生的海量数据而开展的项目,由查德•沃特斯(Chad Walters)和吉姆•凯勒曼(Jim Kelleman)发起,经过两年发展成为 Apache 基金会的顶级项目。
HBase 是对 Google 的 Bigtable 的开源实现。
2006 年 11 月,Google 公司发表了论文 Bigtable: A Distributed Storage System for Structured Data,但是源码没有对外开放。
2007 年 2 月,项目发起人根据 Bigtable 的技术论文提出了作为 Hadoop 模块的 HBase 原型,该原型介绍了 HBase 的基本概念,以及数据库表、行键和底层数据存储结构的设计等。
由于 HBase 依赖 HDFS,它的版本发布都与 Hadoop 同步。
2007 年 10 月,第一个可用的 HBase 版本随同 Hadoop 0.15.0 版本发布,此版本只实现了最基本的模块和功能,因为处于初始开发阶段, HBase 功能还不够完善。
2008 年 1 月,Hadoop 升级为 Apache 的顶级项目,HBase 也作为 Hadoop 的子项目存在。其后 HBase 的发展非常活跃,两年间追随 Hadoop 的主版本发布了多个版本。
但在 2010 年 6 月发布 0.89.x 版本后不再与 Hadoop 发布关联,因为 Hadoop 的版本相对比较成熟,更新步伐减慢,而 HBase 处于活跃期,版本发布更加频繁。
同时,在 2010 年 HBase 成为 Apache 的顶级项目,此时的 HBase 已经基本实现了 Bigtable 论文中提出的功能。
从BigTable说起
- BigTable是一个分布式存储系统
- BigTable起初用于解决典型的互联网搜索问题
- 利用谷歌提出的MapReduce分布式并行计算模型来处理海量数据
- 使用谷歌分布式文件系统GFS作为底层数据存储
- 采用Chubby提供协同服务管理
- 可以扩展到PB级别的数据和上千台机器,具备广泛应用性、可扩展性、
高性能和高可用性等特点 - 谷歌的许多项目都存储在BigTable中,包括搜索、地图、财经、打印、
- 社交网站Orkut、视频共享网站YouTube和博客网站Blogger等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









