







 本教程详细介绍了如何在Ubuntu 18.04上搭建Hadoop 3.1.3的伪分布式环境。内容包括Hadoop的简介、核心架构、特性、版本以及详细的安装配置步骤,如创建Hadoop用户、安装SSH、配置SSH无密码登陆、安装Java环境、配置Hadoop伪分布式。通过实例展示了单词统计和正则表达式抓取,验证了Hadoop的运行效果。
本教程详细介绍了如何在Ubuntu 18.04上搭建Hadoop 3.1.3的伪分布式环境。内容包括Hadoop的简介、核心架构、特性、版本以及详细的安装配置步骤,如创建Hadoop用户、安装SSH、配置SSH无密码登陆、安装Java环境、配置Hadoop伪分布式。通过实例展示了单词统计和正则表达式抓取,验证了Hadoop的运行效果。
大数据处理架构Hadoop
摘要: 在Linux 环境搭建Hadoop伪分布式集群,并对HDFS进行基本的操作。
文章目录
简介
(先来大概了解一下Hadoop)
总的来说,Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算.
Hadoop框架中最核心设计就是:HDFS和MapReduce.
- HDFS提供了海量数据的存储,
- MapReduce提供了对数据的计算.
• Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
•Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
•Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
•Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
•几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
核心架构
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS(对于本文)的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且
是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方
面的特性:
• 高可靠性
• 高效性
• 高可扩展性
• 高容错性
• 成本低
• 运行在Linux平台上
• 支持多种编程语言
版本
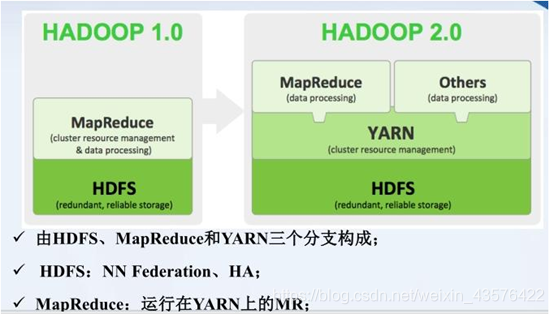
YARN:资源调度管理
MR:MapReduce
Hadoop项目结构
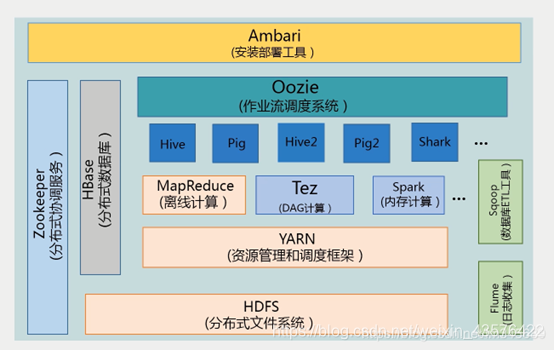
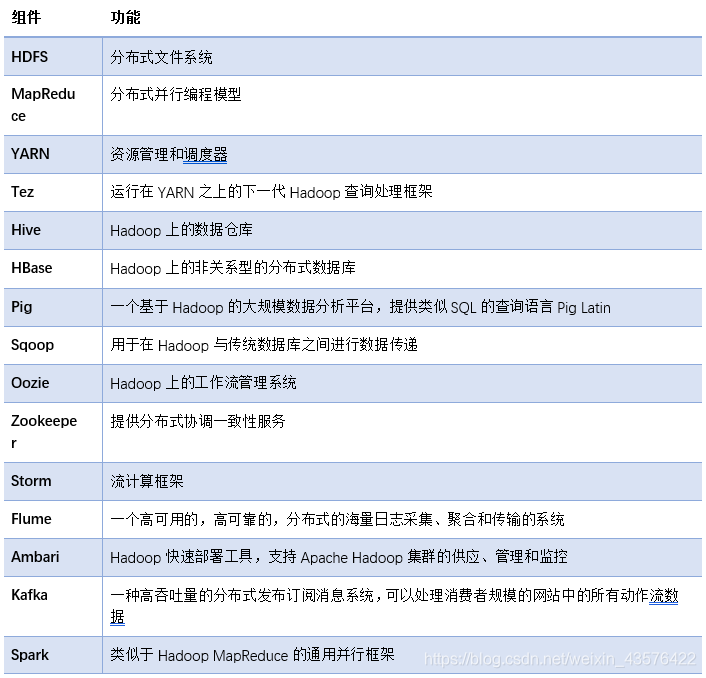
各组件功能简介
Hadoop基本安装配置:
Hadoop基本安装配置主要包括以下几个步骤:
• 创建Hadoop用户
• SSH登录权限设置
• 安装Java环境
• 单机安装配置
• 伪分布式安装配置
环境
本教程使用 Ubuntu 18.04 64位 作为系统环境

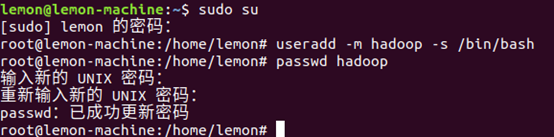
创建hadoop用户
首先按 ctrl+alt+t 打开终端窗口,建议一开始使用sudo su获取管理员权限,这样会方便很多,输入如下命令创建新用户 :
useradd -m hadoop -s /bin/bash
设置密码,可简单设置为 hadoop,按提示输入两次密码
为其增加管理员权限

注销当前用户,以Hadoop身份登录
更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt update
安装vim
这是一个强大的文本编辑工具
sudo apt install vim
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
sudo apt install openssh-server
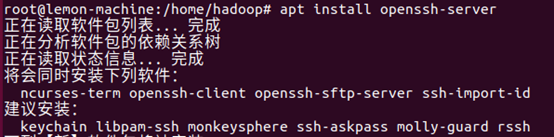
ssh localhost
此时可能会出现permission deny,不要慌。正常登录的话后按exit退出就行。
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
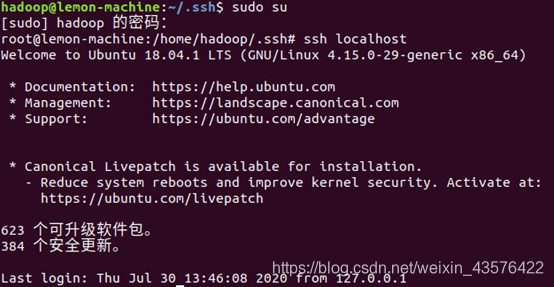
安装Java环境
Hadoop3.1.3需要JDK版本在1.8及以上。需要按照下面步骤来自己手动安装JDK1.8。
我这里把安装包放在了桌面(当然你也可以放到你想放的目录,解压的时候写对路径就行)
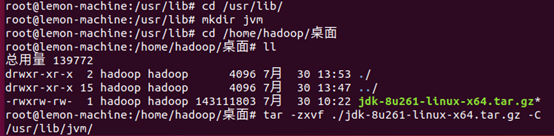
解压完成后,可以去相应目录查看一下:

可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_261目录。
下面继续执行如下命令,设置环境变量:(注意写对自己相应的jdk版本号)
cd ~
vim ~/.bashrc
上面这个命令打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容(按i进入编辑模式):
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
输入完成后,按esc,再同时按shift+:键,输入wq,回车,即可保存退出。
继续执行如下命令让.bashrc文件的配置立即生效:
source ~ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









