







 本文是一个python3爬虫入门教程,介绍如何下载网页、设置用户代理、ID遍历爬虫以及链接爬虫。通过示例解释了如何处理网页下载中的重试和设置用户代理,以及如何利用ID遍历网站内容。同时提到了requests库在爬虫中的重要性。
本文是一个python3爬虫入门教程,介绍如何下载网页、设置用户代理、ID遍历爬虫以及链接爬虫。通过示例解释了如何处理网页下载中的重试和设置用户代理,以及如何利用ID遍历网站内容。同时提到了requests库在爬虫中的重要性。
本文是一个python3爬虫入门教程,需要注意的是你需要有python基础,不过也仅需要掌握简单的用法即可。
前言
网络爬虫被用于许多领域,收集不太容以其他格式获取的信息。
需要注意的是,网络爬虫当你抓取的是现实生活中真实的公共的公共数据,在合理的使用规则下是允许转载的。
相反,如果是原创数据或是隐私数据,通常受到版权显示,而不能转载。 请记住,自己应当是网络的访客,应当约束自己的抓取行为,否则会造成不良后果。
我们将从零开始,逐步完善一个高级网络爬虫。.
下载网页
下面的示例脚本使用urllib模块下载url
import urllib.request
def download(url):
return urllib.request.urlopen(url).read()
当传入url时,该函数将会下载网页并返回其HTML。不过这样不够稳健,因为我们访问网页的时候可能会遇到问题,比如页面不存在。
因此下面给出一个更稳健的版本:
import urllib.request
from urllib.error import URLError,HTTPError,ContentTooShortError
def download(url):
print('Downloading:')
try:
html = urllib.request.urlopen(url).read()
except (URLError,HTTPError,ContentTooShortError) as e:
print('download:',e.reason)
html = None
return html
当网址不正确的时候你就可能看到:

1. 重试下载
下载时遇到的错误很多时候是临时性的,比如服务器过载时返回的503错误。对于这类错误我们可以等待一下再尝试访问。不过不是所有的错误都需要重试,比如404,这说明网页页面不存在。
下面给出新版本代码,当download遇到5xx错误码时,将会递归调用函数自身进行重试,当然我们还增加了重试的次数:
def download(url,num_retries=2):
print('Downloading:',url)
try:
html = urllib.request.urlopen(url).read()
except (URLError,HTTPError,ContentTooShortError) as e:
print('download:',e.reason)
html = None
if num_retries>0:
#hasattr() 函数用于判断对象是否包含对应的属性。
if hasattr(e,'code') and 500<=e.code<600:
return download(url,num_retries-1)
return html
测试代码:

2. 设置用户代理
默认情况下,urllib使用python-urllib/3.x 作为用户代理下载网页,3.x是python版本号,但是有些网站会封禁这个默认代理。下面我们来控制用户代理的设定:('wswp’是web scraping with python的缩写)
def download(url,user_agent='wswp',num_retries=2):
print('Downloading:',url)
request = urllib.request.Request(url)
request.add_header('user_agent',user_agent)
try:
html = urllib.request.urlopen(url).read()
except (URLError,HTTPError,ContentTooShortError) as e:
print('download:',e.reason)
html = None
if num_retries>0:
#hasattr() 函数用于判断对象是否包含对应的属性。
if hasattr(e,'code') and 500<=e.code<600:
return download(url,num_retries-1)
return html
ID遍历爬虫
在这里我们利用网站结构的特点,更加轻松的访问所有内容
下面是一个地图示例网站的url
- http://example.python-scraping.com/places/default/view/Afghanistan-1
- http://example.python-scraping.com/places/default/view/Aland-Islands-2
- http://example.python-scraping.com/places/default/view/Albania-3
显而易见的是,这些url只在最后的一部分有区别,包含 页面别名 和 ID 。在url中包含页面别名是非常常见普遍的做法,可以对搜索引擎优化起到帮助作用。一般情况下,Web服务器会忽略这个字符串,只使用ID来匹配数据库中的相关记录。我们将他移除再访问看看:
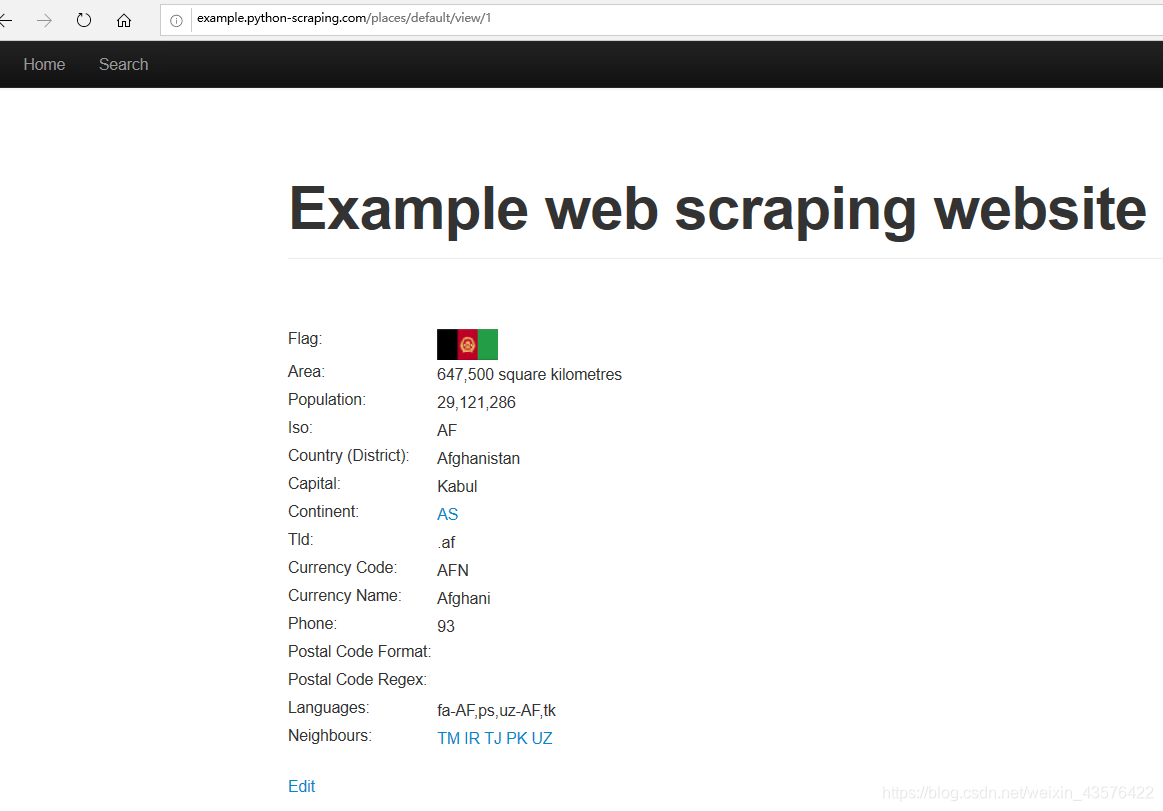
可以看出,网页依旧可以访问。现在我们就可以忽略别名,只使用ID下载所有国家或地区的页面:
itertools.count([n]):创建一个迭代器,生成从n开始的连续整数,如果忽略n,则从0开始计算
import itertools
def crawl_site(url):
for page in itertools.count(1):
pg_url = '{}{}'.format(url,page)
html = download(pg_url)
if html is None:
break
接下来使用该函数传入基础url:
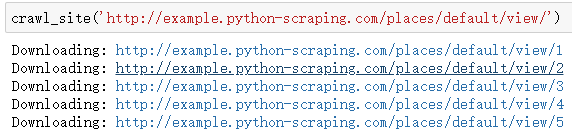
在这段代码中,我们对ID进行遍历,直到出现错误停止。不过有时候页面的有些记录可能已经被删除,数据库ID之间并不是连续的,在这种情况下只要访问到某个间隔点显然爬虫就会退出。下面是改进版本,在该版本下连续多次下载错误才会退出程序。
def crawl_site(url,max_errors=5):
for page in itertools.count(1):
pg_url = '{}{}'.format(url,page)
html = download(pg_url)
if html is None:
num_errors += 1
if num_errors == max_errors:
break
else:
num_errors =0
上面代码中爬虫需要连续5次下载错误才会停止遍历,在爬取网站中,遍历ID是一个很便捷的方法。
在爬取wall.alphacoders.com下的英雄联盟壁纸这篇文章中,就典型的利用了遍历ID获取一个页面下的所有图片。
但是这种方法也无法保证一直可用,比如有一些网站会检查页面别名是否在URL,如果不是则会返回404.
你可能在爬取过程中已经遇到 TOO MANY REQUESTS 下载错误信息,我们将在后面解决它。
链接爬虫
到目前为止,我们已经使用地图示例网站的结构特点实现了两个简单爬虫。不过对于另一些网站,我们需要让爬虫表现得更像普通用户,跟踪链接,访问敏感内容。
例如在爬取英雄联盟壁纸的文章中,查看壁纸网页源码时:
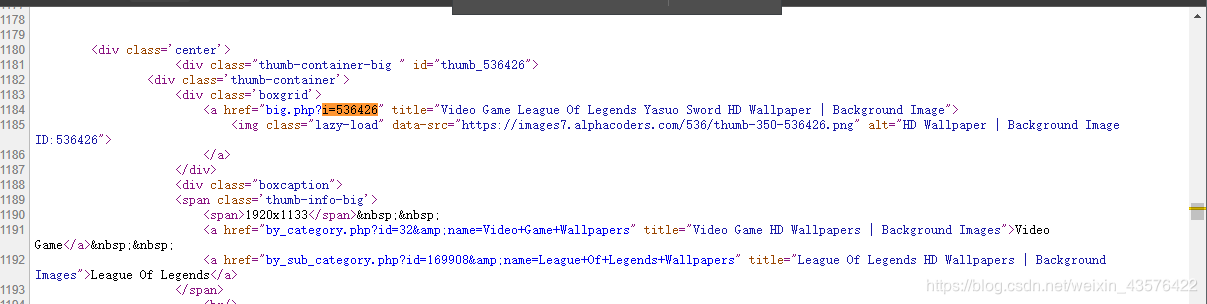
<div class='boxgrid'>
<a href="big.php?i=536426"
其中big.php?i=536426,该链接只有网页的路径部分,而没有协议和服务器部分,也就是说这是一个相对链接,由于浏览器知道你在浏览哪个网页,并且能采取相应措施处理这些链接,因此用浏览器浏览时,相对链接是可以正常工作的。但是urllib没有上下文,为了让爬虫正常工作,我们需要将链接转为绝对链接的形式,以包含定位网页的所有细节。
如 https://wall.alphacoders.com/big.php?i=536426
使用requests库
尽管我们使用urllib也能实现爬虫,但是主流的爬虫一般用requests库来管理复杂的HTTP请求。
后面我们大部分时候将使用它,因为它足够强大且简单。
安装:
pip install requests


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









