







前言:在Linux下,我们都清楚一段代码要变成一个可执行文件,他需要经历预处理,编译,汇编,链接这四个过程。

在这每一步都需要进行很多工作,这里我结合王老师的深入分析gcc和程序员的自我修养这两本书来笼统讲一下编译这个过程到底干了什么事情。
GCC的逻辑结构
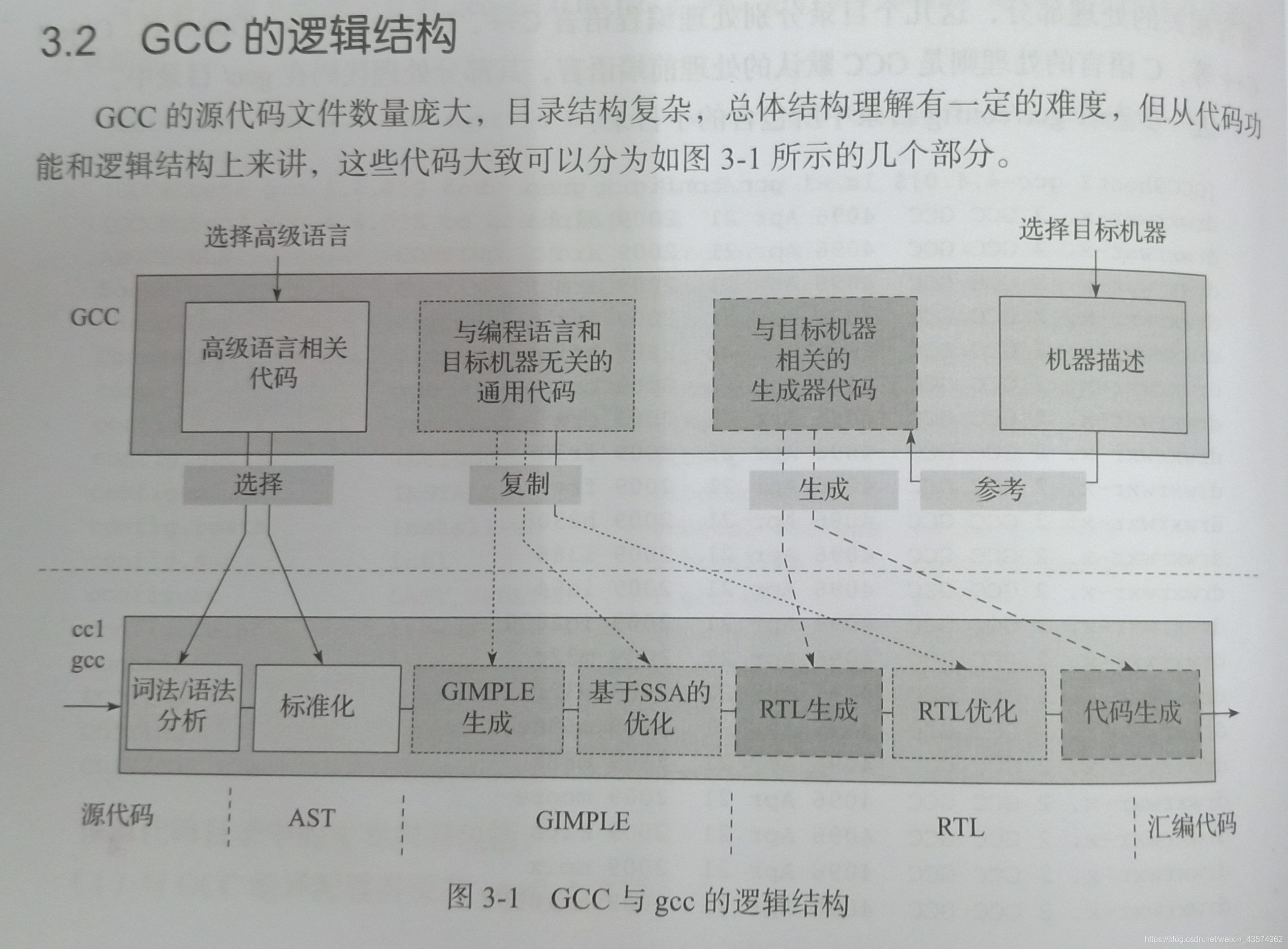
-是不是单看这张图感觉有点不知所措?
接下来我将每一个步骤来一个一个进行解释。
选择高级语言
这张图的上半部分的第一大块是选择高级语言,由于gcc编译器他支持各种很多语言,当你在进行编译的时候,他会首先来根据你的语言选择不同的语法词法语义分析,得到不同形式的抽象语法树(AST),第一阶段结束。
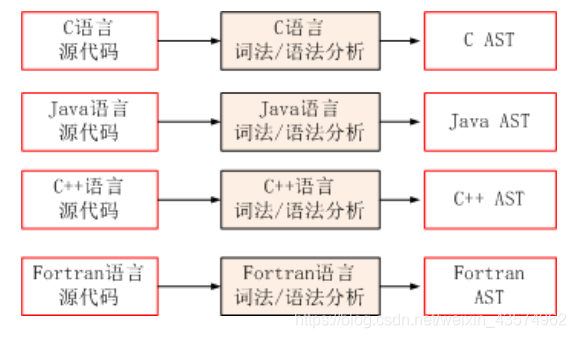
词法分析
首先将源程序输入到扫描器之中,对构成源程序的字符流进行扫描和分解,识别出单词,将代码的字符序列分割成一系列的记号。
词法分析产生的记号一般有如下几类:
关键字,标识符,字面量(数字,字符串等等),特殊符号(加号减号等)
在进行识别记号的同时,扫描器顺便也进行其他工作,比如将标识符放到符号表,将数字,字符串常量放到文字表中等工作。
语法分析
接下来,机器通过词法分析器,对刚才扫描器产生的记号进行语法分析,将单词序列分解成不同的语法短语,从而生成语法树,确定整个输入串能够构成语法上正确的程序。整个过程都采用了上下文无关语法的分析手段,由语法分析器生成的语法树就是以表达式为节点的树。
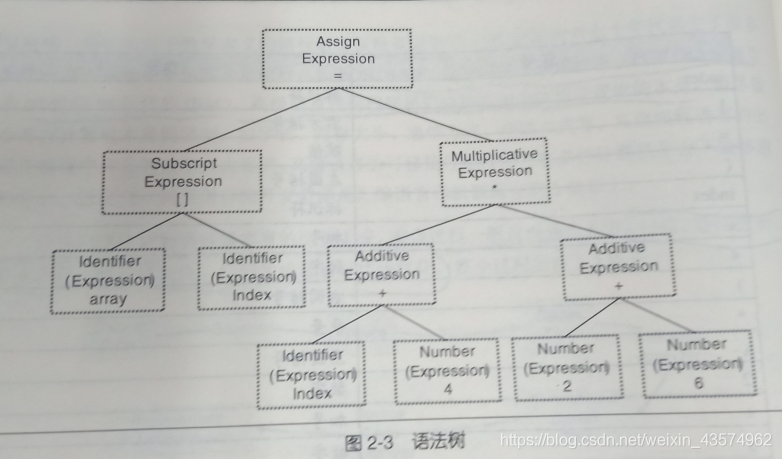
如果在此阶段出现了表达式不合法,比如各种括号不匹配,表达式缺少操作符等,此时编译器就会报告语法分析阶段的错误。
对于语法树的具体结构,在王老师的书深入分析gcc中是有详细讲解的,由于篇幅有限,而且这篇只是先入门,之后在另写总结,完成之后会贴链接过来。
语义分析
由语义分析器来完成,检查源程序上有没有语义错误,语法分析仅仅是完成了对表达式的语法层面的分析,并不了解这个语句在语法上面是否合法,比如一个指针和一个浮点数进行乘法运算等。
但是,编译器所能分析的语意是静态语义,所谓静态语义就是在编译期可以确定的语义,与之对应的是动态语义,在运行阶段才能确定的语义。
静态语义通常包括了声明和类型的匹配,类型的转换之类。
动态语义通常有函数调用进行赋值,0作为除数等运行期才能确定的错误。
经过语义分析后,整个语法树的表达式就都被标示了类型,如果类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。
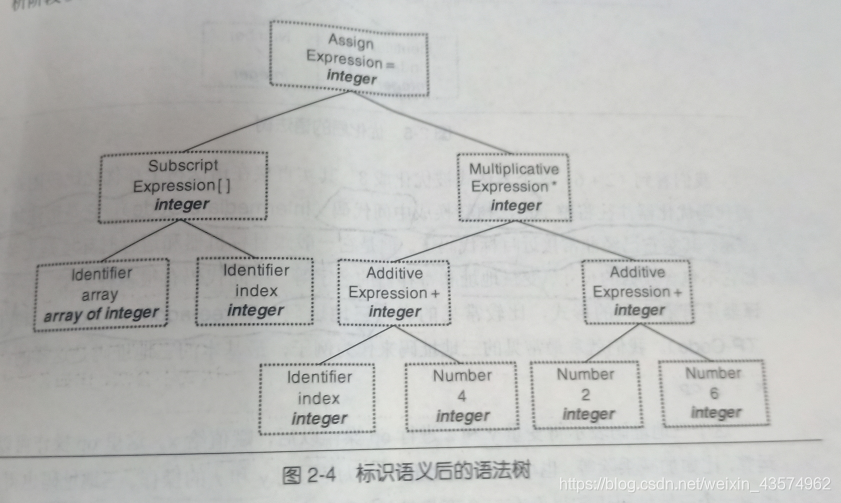
下面就进行第二个阶段的工作了
编程语言无关和目标机器无关的通用代码
现代的编译器都会有很多层次的优化,往往在源代码层面就会有一个优化过程,这里的源码级优化器会对程序在源码级别进行优化,例如一个表达式i = 2+1,既然在编译器已经知道了i的值是多少,所以编译器会在这里进行代码优化,直接写成i = 3的形式。
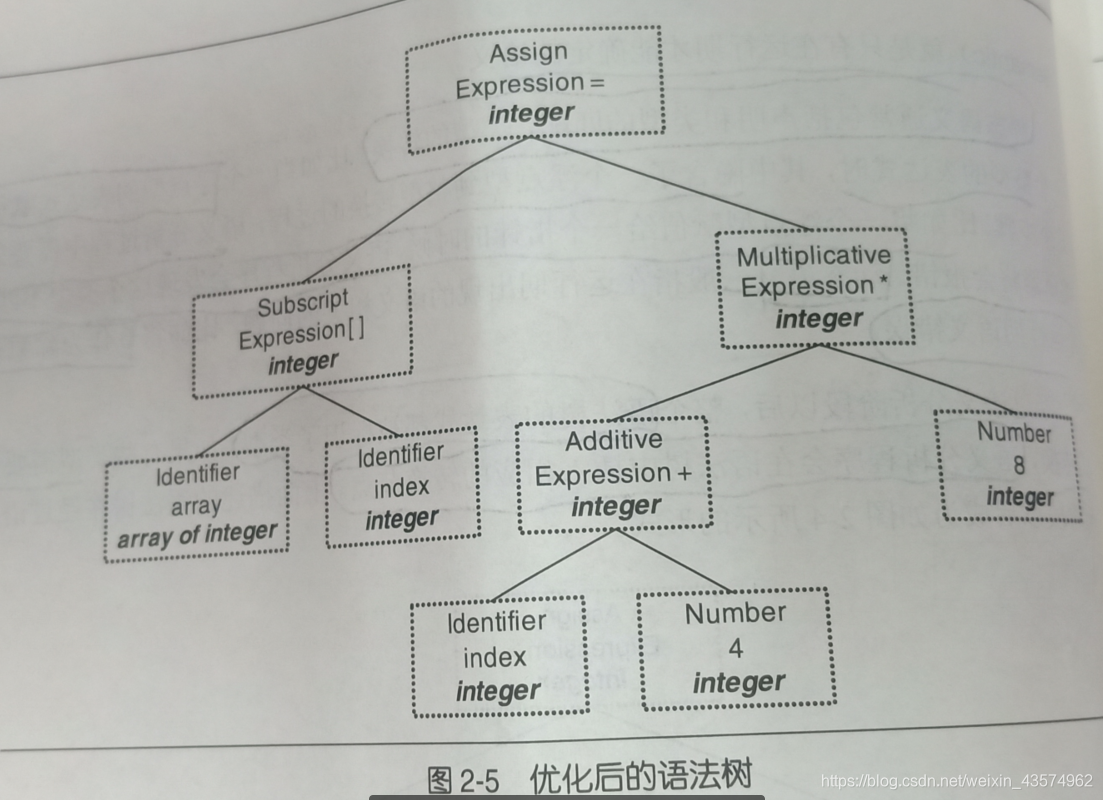
但是由于直接在语法树上进行优化是比较困难的,所以源代码优化器往往会将整个语法树转换成中间代码的格式。
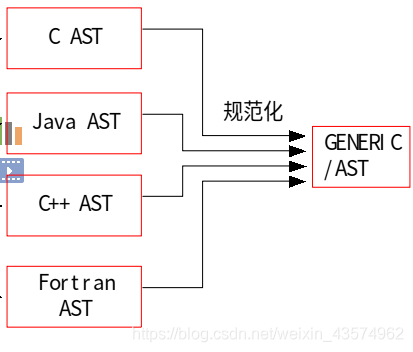
中间代码生成(GIMPLE生成)
GENERIC是指规范的抽象语法树,中间代码是语法树的顺序表示,结构已经很接近目标代码了,但是在此阶段他和目标代码的区别主要在与这个阶段的代码与目标机器和运行环境是无关的,他不包括数据的尺寸,变量地址,寄存器的名字等。
中间代码有很多种类型,在不同的编译器中都有着不同的形式,比较常见的有三地址码和P-代码,以三地址码为例,最基本的操作如下
x = y op z //op如操作运算符,比如加减乘除
上面例子中的语法树翻译为三地址码的格式为
t1 = 2 + 6
t2 = index + 4
t3 = t2 * t1
array[index] = t3
然后就该进行优化了。
基于SSA的优化
为了组织的方便,GCC使用Pass的管理策略
一个PASS进行一种特定的处理过程
一个PASS的输出结果将作为下一个PASS的输入(有些类似于Unix/Linux系统中的管道处理的概念)。
另外,在后端对于RTL的优化的处理,GCC同样也采用Pass管理。
这一阶段的任务是对前一阶段产生的中间代码进行变换或进行改造,目的是使生成的目标代码更为高效,即省时间和省空间。
经过优化后的三地址码格式
t2 = index + 4
t2 = t2 * 8
在这里优化说起来好像很容易,但是实际上,gcc中有上百个Pass,有的Pass非常复杂,很难理解,可能某些Pass需要看一个月才能看懂,所以,gcc的精华也在对与代码优化的这部分。
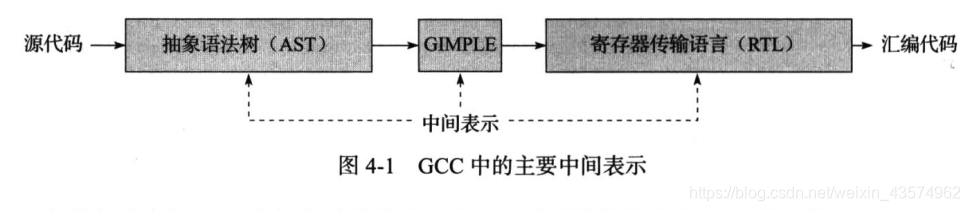
中间语言生成这一阶段在编译过程中起了一个承上启下的任务,中间代码使得编译器可以被分为前端和后端,编译器前端负责产生机器无关的中间代码(GIMPLE),编译器后端将中间代码转换成目标机器代码,这样的优点是对于一些跨平台的编译器,他们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
下面就进行第三阶段的工作了
与目标机器相关的生成器代码生成
源代码级优化器产生中间代码标志着下面的过程属于编译器后端,编译器后端主要包括代码生成器和目标代码优化器,就像那张图中画的,这一阶段的过程就十分依赖于目标机器了,因为不同的机器有着不同的字长,寄存器,整数数据类型和浮点型数据类型等。
RTL生成
这一阶段的任务是把中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码,以上述例子中的中间代码来说,代码生成器可能会生成下面的代码序列(我们用x86的汇编语言来表示,并且假设index的类型为int型,array的类型为int型数数组)。
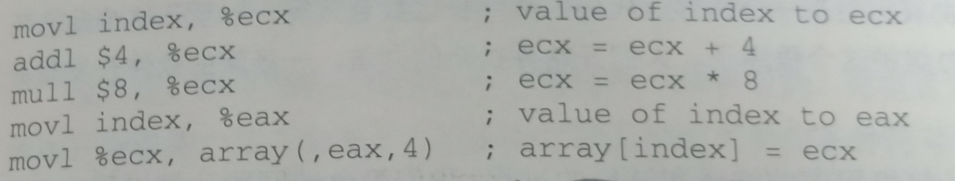
这部分在王老师的书深入分析gcc中是有详细讲解的,由于篇幅有限,而且这篇只是先入门,之后在另写总结,完成之后会贴链接过来。
RTL优化
最后目标代码优化器对上述的目标代码进行优化,就像上面所说的,对于RTL的处理,GCC同样也采用Pass管理,一个PASS进行一种特定的处理过程,比较常见的优化有,选择合适的寻址方式、用位运算对来代替乘法运算、删除多余的指令等。
上面的例子中,乘法由一条相对复杂的基址比例变址寻址的lea指令完成,随后由一条mov指令完成最后的赋值操作,这mov指令的寻址方式与lea是一样的。

这部分同样在王老师的书深入分析gcc中是有更加详细讲解的,由于篇幅有限,而且这篇只是先入门,之后在另写总结,完成之后会贴链接过来。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











