









标注:写的很好的论文, IF:9+, Year:2024
摘要
从结肠镜图像中分割息肉在临床实践中非常重要,因为它为结直肠癌提供了有价值的信息。然而,息肉分割仍然是一个具有挑战性的任务,因为息肉具有伪装特性且大小差异很大。尽管最近提出了许多息肉分割方法并取得了显著的成果,但由于缺乏具有区分性特征和高级语义细节的特征,大多数方法无法产生稳定的结果。因此,我们提出了一个名为对比变换器网络(CTNet)的新息肉分割框架,它包含三个关键组件:对比变换器主干、自多尺度交互模块(SMIM)和集合信息模块(CIM),具有出色的学习和泛化能力。CTNet通过对比变换器获得的长距离依赖和高度结构化的特征图空间,可以有效地定位具有伪装特性的息肉。CTNet受益于SMIM和CIM分别获得的多尺度信息和具有高级语义的高分辨率特征图,因此可以获得不同大小息肉的准确分割结果。在没有任何花哨功能的情况下,CTNet在Kvasir-SEG、CVC-ClinicDB、Endoscene、ETIS-LaribPolypDB和CVC-ColonDB上分别比经典方法PraNet获得了2.3%、3.7%、3.7%、18.2%和10.1%的显著提升。此外,CTNet在伪装目标检测和缺陷检测方面具有优势。代码可在GitHub - Fhujinwu/CTNet获取。
写作鉴赏:论文首先提出息肉分割的难点和目前的缺陷,然后引出自己的方法,方法的各个模块分别对应前面提到的不足。这里需要注意,通过对比不同论文的写作方式,可以发现:对于方法常规的论文(比如常规的特征融合、边界细化操作),论文摘要和引言只提及息肉分割任务的难点,然后后续方法和难点一一对应。但是当论文方法比较新颖时(比如这篇论文是在息肉分割任务上第一个使用对比学习的、MSRFormer中使用transformer),会在引言和摘要中会提及先前常规方法的不足,以验证新方法的优势。
引言
结直肠癌(CRC)是全球第三大常见癌症,也是第二大常见癌症死因,2020年估计有约190万新癌症病例和超过90万例死亡。CRC通常始于结肠内壁组织中的非癌性突起(称为息肉)。CRC在早期阶段的生存率可达90%,一旦进入晚期,生存率会急剧下降。因此,早期诊断并进行有效治疗有可能挽救更多生命。结肠镜检查是用于视觉检查结肠的标准技术,被认为是检测和切除结直肠病变的金标准。然而,实际中的结肠镜检查高度依赖于医生的经验水平,并且存在漏检息肉的高风险。因此,应用自动息肉分割技术对于提高诊断系统的效率以及帮助临床医生对恶性程度做出可行的决策从而决定进一步治疗具有极高的价值。
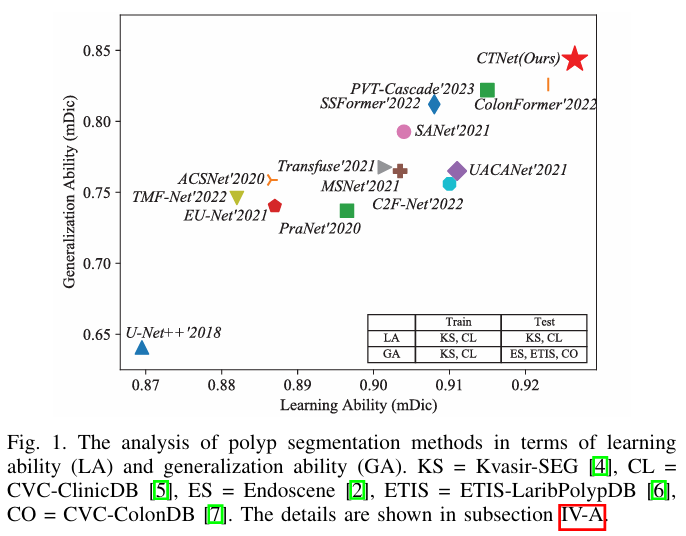
在计算机技术的帮助下,许多自动息肉分割方法已经取得了显著成果,如图1所示。然而,息肉分割仍然是一个具有挑战性的任务,因为与通用分割任务相比,息肉分割任务具有自身的特点,如图2所示。首先,息肉与周围组织在颜色和纹理上具有高度相似性,因此它们的伪装特性导致难以准确定位。其次,息肉在形状和大小上差异很大,使得模型难以产生稳定的分割结果。第三,与背景区域相比,息肉区域通常较小,导致小息肉在重复下采样过程中容易丢失且难以恢复。此外,由于不同的图像采集设备,获得的图像特征差异很大,使得当前模型难以推广到不同领域/分布中的多中心(或未见)数据。
写作鉴赏:这篇真的写的很棒,是我看过的息肉分割论文里,idea和写作逻辑都名列前茅的。我认为在自己写论文时,可以先看列出自己的创新点和优势,然后再根据这些重点描写息肉分割的难点和先前研究的不足。
首先,我们看这篇论文的创新点是:①使用对比框架②使用SIMM框架,得到多尺度信息③使用CIMM框架,得到高级语义信息。再看这些创新点分别是针对什么特点的?①针对的是模型泛化性,即在不同源测试集上的性能。②针对的是息肉大小、形状差异度高,③针对的是大多息肉尺寸较小,易在下采样过程中被忽视。可能新学息肉分割的友友觉得这些对应关系不明显,自己写的时候没法想到,其实只要uu多看论文就会发现,息肉特点和难点其实就5~6个,然后常见的解决方案也就4~5个,每篇论文都是大概提3个新模块来解决4个左右的难点,看多了就熟练了。
然后我们得到创新点和对应的难点后,开始写论文。首先为了突出泛化性,论文列出了不同model的学习能力和泛化能力对比,以凸显本篇论文的泛化性。其次为了凸显息肉尺寸、形状差异大和大多数息肉较小,因此做了图2,图2左边展示了不同形状大小的息肉,右边展示了小尺寸息肉占大多数。这里还提到了息肉边界不明显,其实根据前面的分析可以发现,论文并没有针对这一点提出方法。但是息肉边界不明显是所有论文都无法避免的,它是息肉分割中最大的特点和难点,因此论文也必须提,顺笔带过。
至此,论文的写作逻辑就很清晰了,希望给写论文的uu提供帮助,有其他见解的也可以在下面评论。
针对息肉分割任务中存在的上述特点,许多计算方法已被提出用于在结肠镜息肉图像中定位和分割息肉。当前的解决方案可以分为三种类型:基于传统图像处理的方法(TIP-based method)、基于机器学习的方法(ML-based method)和基于深度学习的方法(DL-based method)-。与基于ML和基于TIP的方法相比,基于DL的方法适应于复杂场景中的息肉分割,因为它们不需要手动提取特征。因此,已经提出了大量的基于DL的方法。如图1所示,尽管大多数当前基于DL的方法在学习能力方面表现良好,但它们在泛化能力方面表现不佳。

由于泛化能力在很大程度上决定了自动息肉分割方法在实际临床应用中的前景,因此我们提出了一个名为CTNet的自动息肉分割新框架。我们提出的CTNet由三个组件组成:对比变换器主干、自多尺度交互模块(SMIM)和集合信息模块(CIM),具有良好的学习和泛化能力。CTNet通过对比变换器获得长距离依赖和高度结构化的特征空间,从而推动模型更准确地定位息肉。SMIM可以高效地获取多尺度信息,而CIM可以获得具有高级语义信息的高分辨率特征图,使模型能够在不同尺度上很好地分割息肉。我们总结我们的主要贡献如下:
-
一种新的息肉分割方法。所提出的CTNet是首次尝试使用监督对比学习策略训练变换器主干,以提取更稳健且高度结构化的特征分割空间用于息肉分割任务。
-
为了使不同大小的息肉保持稳定的分割结果,我们首次提出了自多尺度交互模块和集合信息模块,以获取多尺度信息和具有高级语义的高分辨率特征图。
-
实验证明CTNet在息肉分割任务上具有出色的学习和泛化能力,并且在伪装目标检测和缺陷检测任务上也表现出色。
本文的其余部分安排如下。第II节介绍相关工作。第III节描述所提出的CTNet。第IV节提供实验和讨论。本文的结论在第V节。
相关工作
在相关工作中,论文首先根据引言中提到的划分方式来概述先前的工作,再然后根据本篇论文中的使用的方法:transformer和对比方法,来写相关方法。
在本节中,我们重点关注与我们的工作密切相关的部分,包括图像级别的息肉分割、视觉Transformer和对比学习。
A. 息肉分割
传统图像处理方法:基于TIP的方法主要依赖于颜色和纹理等低级特征,并使用区域生长、活动轮廓分析和分水岭等传统图像处理技术。Sasmal等人提出了一种基于主成分追踪和活动轮廓模型的方法。Gross等人结合非线性扩散滤波、Canny算子等方法实现了息肉分割。然而,由于息肉与周围组织的高度相似性,基于TIP的方法存在漏检或误检的可能性较高。
机器学习方法:基于ML的方法通过提取人工特征并使用分类器(如SVM和ANN)来准确分割息肉区域。Tajbakhsh等人通过构建和细化边缘图,然后提取基于形状和上下文的特征来进行边缘分类。Bernal等人提出了一种基于ML的息肉分割方法,通过计算DOVA能量图来提取息肉边界。然而,由于基于ML的方法高度依赖于手动提取的特征,因此在处理复杂的息肉分割任务时表现不佳。
深度学习方法:基于DL的方法在息肉分割领域取得了显著进展,出现了许多高性能的息肉分割方法。Fan等人提出了PraNet,通过逆向注意力获取全局注意力特征图,然后挖掘特征图的边界信息。Wu等人提出了PolypSeg+,这是一个轻量级的上下文感知网络,包含自适应尺度上下文模块、高效全局上下文模块和特征金字塔融合模块。Ji等人提出了PNSNet,这是一个基于自注意力的视频息肉分割框架,充分利用时间和空间线索。Wu等人提出了时空特征变换,通过聚合相邻帧的特征来实现良好的视频息肉分割。Liu等人提出了傅里叶变换多尺度特征融合网络(FTM-Net),用于小息肉对象的分割。
B. 视觉Transformer
视觉Transformer在计算机视觉任务中的特征提取潜力受到了极大的关注。Liu等人提出了层次化Transformer,可以应用于分类和定位等任务。Xie等人设计了MixTransformer,结合了CNN和Transformer,用于语义分割任务并取得了最先进的结果。Zhang等人首次尝试将CNN和Transformer结合用于医学图像分割的并行双分支架构。Li等人通过全局Transformer和双局部注意力网络的深度-浅层层次特征融合,在视网膜血管分割中取得了良好的结果。Yang等人提出了结合CNN和Transformer的双编码器单元,用于通过学习局部和全局语义信息进行息肉分割。
C. 对比学习
最近,对比学习在计算机视觉领域受到了更多的关注。对比学习的关键是使用相似样本作为正样本,不相似样本作为负样本,并比较正负样本来学习区分性表示。经典的对比学习框架SimCLR由Chen等人提出,使用同一图像的两个随机增强视图生成正对,使用不同图像获得负对,形成图像级别的判别任务。然而,大多数使用对比学习的工作主要集中在无监督图像级别任务上。另一方面,无监督对比学习由于缺乏标签指导,可能会存在一些严重问题。为了将对比学习应用于监督语义分割任务,Wang等人和Zhao等人使用了像素对比损失进行语义分割任务。Pissas等人提出将对比学习应用于增强语义分割网络的区分能力,以提取多尺度特征。其核心思想是使用对比学习在相同类别中创建高相似性的特征图,并在不同类别中创建不同的特征。
视觉Transformer结构在定位感兴趣区域方面比ResNet结构更准确,通过像素级对比学习,图像中高度相似像素的特征可以被空间近似,不同类别像素的特征可以被尽可能地空间分离。因此,我们使用对比学习策略训练初始主干,以获得高度结构化的分割特征空间,从而进一步提高分割网络的性能。据我们所知,这是首次使用监督对比学习策略训练Transformer主干,以提取更稳健且高度结构化的特征分割空间用于息肉分割任务。
方法
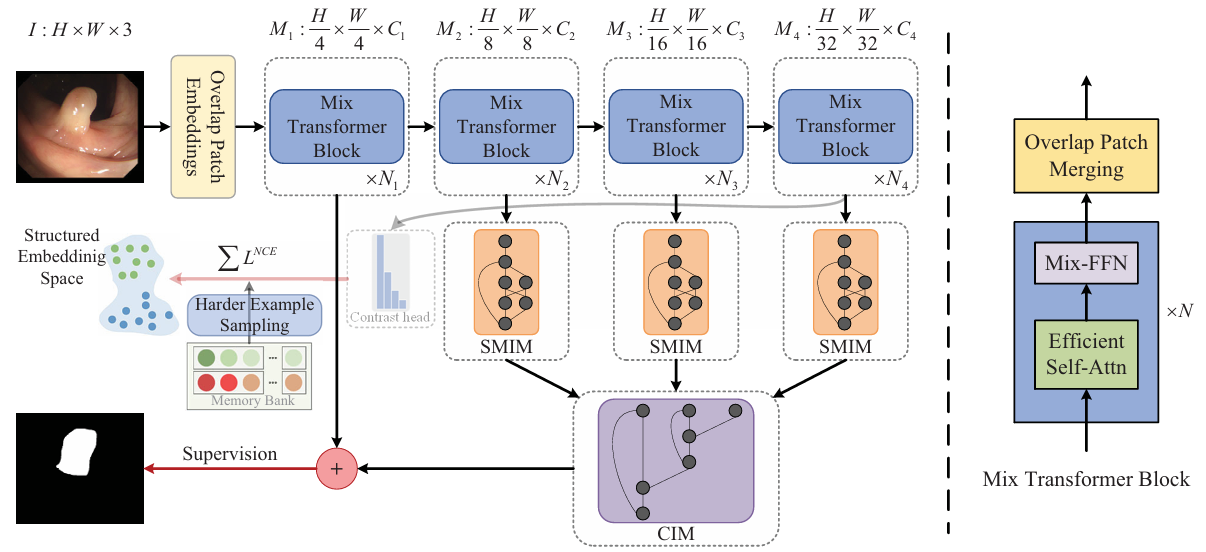
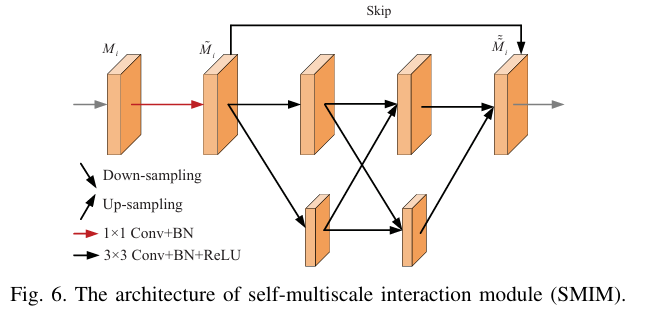
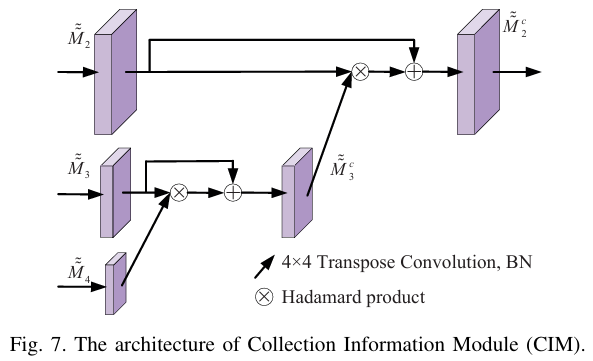
我们提出的CTNet的概述如图3所示,它由以下关键组件组成:对比变换器主干(基于MiT)、自多尺度交互模块(SMIM)和集合信息模块(CIM)。具体来说,对比变换器主干可以通过获得的长距离依赖和高度结构化的特征图空间有效地定位具有伪装特性的息肉。SMIM从主干网络生成的特征图中获取多尺度特征,以应对息肉大小变化的情况。CIM通过逐渐增加语义信息来指导低级特征图的生成,从而生成具有高语义分辨率的特征图。与以往的息肉分割方法不同,CTNet不仅具有良好的学习能力和泛化能力,还可以广泛应用于伪装目标检测等任务。























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









