




将通过 NLP 中最常见的文本分类任务来学习如何在自己的数据集上利用迁移学习(transfer learning)微调一个预训练的 Transformer 模型—— DistilBERT。DistilBERT 是 BERT 的一个衍生版本,它的优点在它的性能与 BERT 相当,但是体积更小、更高效。所以我们可以在几分钟内训练一个文本分类器。
如果你想尝试一下 BERT,那么只需改一下模型的 checkpoint 就可以了。通常,checkpoint 指的是要加载到给定 Transformer 架构中的一系列模型权重。
数据集
这里我们将使用英文推文情感数据集,这个数据集中包含了:anger,disgust,fear,joy,sadness 和 surprise 六种情感类别。
http://dx.doi.org/10.18653/v1/D18-1404
所以我们的任务是给定一段推文,训练一个可以将其分类成这六种基本情感的其中之一的模型。
现在我们来下载数据集。

为了更好地分析数据,我们可以将 Dataset 对象转成 Pandas DataFrame,然后就可以利用各种高级 API 可视化数据集了。但是这种转换不会改变数据集的底层存储方式(这里是 Apache Arrow)。
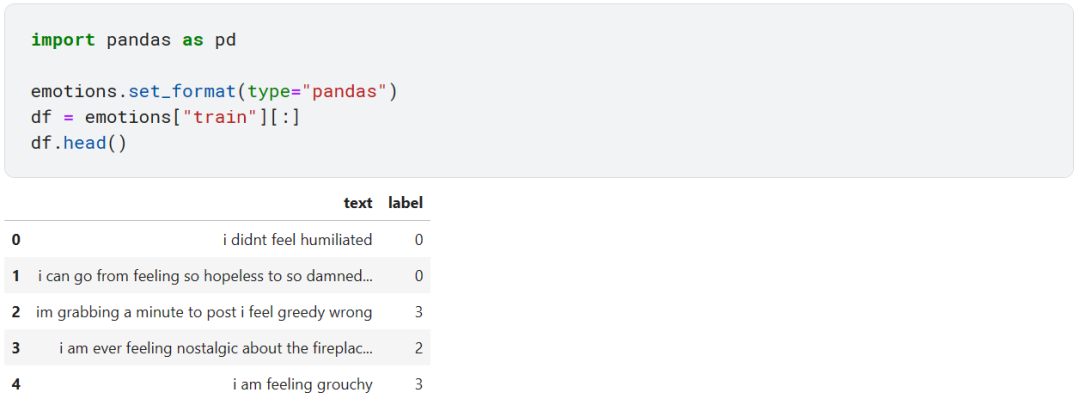
从上面可以看到 text 列中的推文在 label 列都有一个整数对应,显然这个整数和六种情绪是一一对应的。那么怎么去将整数映射成文本标签呢?
如果我们观察一下原始数据集中的每列的数据类型。

我们发现 text 列就是普通的 string 类型,label 列是 ClassLabel 类型。ClassLabel 中包含了 names 属性,我们可以利用 ClassLabel 附带的 int2str 方法来将整数映射到文本标签。
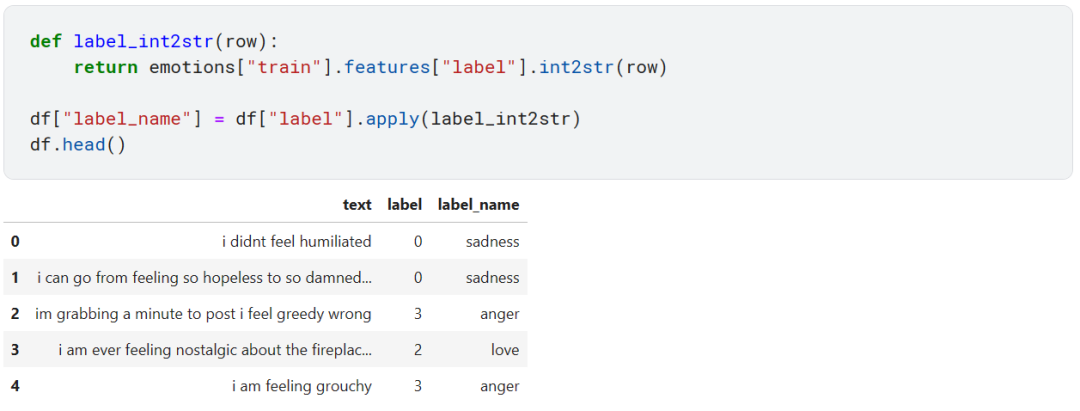
现在看起来就清楚多了。
处理任何分类任务之前,都要看一下样本的类别分布是否均衡,不均衡类别分布的数据集在训练损失和评估指标方面可能需要与平衡数据集做不同的处理。
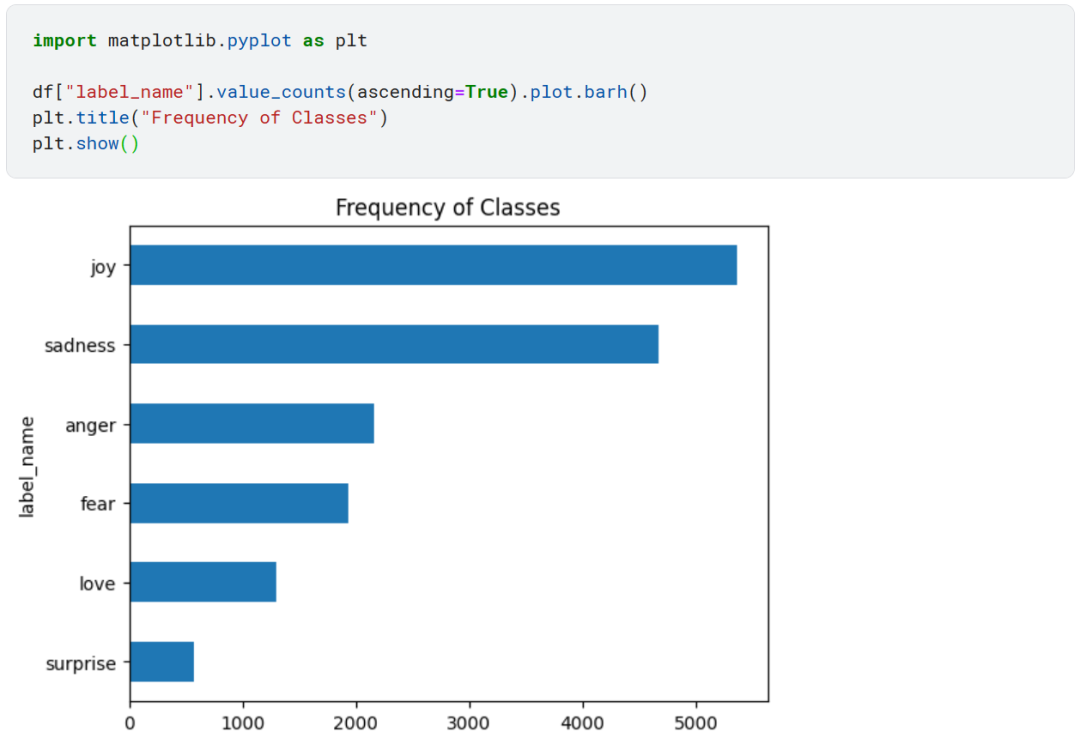
类别分布严重不均衡!joy 和 sadness 类样本数量最多,而 love 和 surprise 类的样本数量几乎要少 5-10 倍。
有好几种方法可以处理类别不均衡问题:
-
对样本数量少的类别进行随机
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1969
1969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











