




******1.mkdir make directorys 创建目录 例子:mkdir /data 在根/下创建data目录,
-p 递归创建目录
2.ls list(列表) 列表目录文件 例子:ls / 列根/目录下目录和文件
-l (long)长格式,-d (directorys)查看目录。
3. cd change directory 改变目录路径 例子:cd /etc
4. pwd print work diectory 打印工作目录 (显示当前所在路径)
5. touch 创建文件或更新文件的时间戳,如果文件不存在,就建立新文件,如果存在,就改变文件的访问时间atime等时间戳信息。
6. vi windows记事本,简单 。 例子: vi oldboy.txt
7. vim 复杂的编辑器 功能复杂,高亮,自动缩进(写shell、python脚本用)
8. echo 打印输出内容,配合 “>或者>>" 可以为文件覆盖及追加内容,还有一个较复杂不常用的类似命令printf。
9. cat 查看文件内容 例子: cat oldboy.txt
10. xargs 从标注你输入获取内容创建和执行命令 -n 数字 ,分组
11. cp copy 拷贝文件或目录,默认不能拷贝目录, -r:递归,用于复制目录:-a:相当于 -pdr, -p:连同档案的属性一起复制过去,而非使用默认属性。
12. rm remove 删除目录和文件 -f(force)强制,-r(recursive)递归,用于删除目录。
强调:删除命令要慎用,非常危险,删除前一定要先备份。
13. mv move 移动文件或目录
14. find 查找 -type 文件类型(f(file)), d(directory),c(character),b(block),s(socket),l(link)),-name '文件名’,-mtime时间,按修改时间查找,时间数字, +7 7天以前,7 第7天, -7 最近7天
15. grep linux三剑客老三 过滤需要的内容, -v 排除内容。例子:grep -v oldboy test.txt
-v 后面接要排除的内容
#Context control:
-B 除了显示匹配的一行外,并显示该行之前的num行
-A 除了显示匹配的一行之外,并显示之后的num行
-C 除了显示匹配的一行之外,并显示该行之前后个num行
16. head 头,头部 读取文件的前n行,默认前10 行, -n 数字,习惯-5,忽略-n
17. tail 尾 ,尾巴 输出文件后n行,默认后10行,-n 数字,习惯 -5,忽略 -n。
18. alias 查看和设置别名
19. unalias 取消别名 unalias cp
20. seq sequence 序列
21. sed stream editor linux 三剑客老二,流编辑器,实现对文件的增删改替换查。
参数 -n 取消默认输出, -i 修改文件内容, -e 允许多项编辑
p打印,g与s联合使用时,表示对当前全局匹配替换。
s常说的查找并替换,用一个字符串替换成另一个
sed -i s#oldbay#g a.txt
#是分隔符,可以用/@等替换。
22. awk 过滤、输出内容,一门语言。NR 行号
23. 硬盘使用前----要分区—格式化(创建文件系统)—存放数据。
房子使用前----要隔断----装修、买家具-----主人
分区:
一块一盘:
主分区、扩展分区、逻辑分区
主分区+扩展分区的数量<=4,其中一个主分区可以用一个扩展分区替换,扩展分区最多只能分一个。
扩展分区不能直接使用,还需要在上面创建逻辑分区,逻辑分区可有多个。
主分区+扩展分区 编号只能1~4,逻辑分区的编号只能从5开始。
常规分区:数据不是特别重要的业务(集群的某个节点)
/boot 引导分区 200m 主分区
swap 交换分区 内存1.5倍,内存大于8G,就给8~16G。
/ Linux所有目录顶点 剩余所有空间
二、数据重要 (数据库、存储服务器)
/boot 引导分区 200m 主分区
swap 交换分区 内存1.5倍,内存大于8G,就给8~16G
/ Linux所有目录顶点, 100-200G
/data 所有,存放数据
三、特大网站,门户(产品线特别多)
/boot 引导分区 200m 主分区
swap 交换分区 内存1.5倍,内存大于8G,就给8~16G
/ Linux所有目录顶点, 100-200G
剩余空间不分配,哪个部门领到了服务器,根据需求再进行分区
IDE接口是hda类型的
scsi接口是sda类型的
24.touch 创建新文件 创建多个文件 touch oldboy.txt 1.txt 2.txt
更新旧文件的时间戳 stat oldboy.txt
touch -a oldboy.txt
25.当ssh不通时,先ping目标ip ,不通 网卡,ip ,网线,防火墙
在letnet 服务器防火墙阻挡 /etc/init.d/iptables stop
端口没开放,服务器没有监听你链接的端口
netstat -lnutp |grep 22
netstat -lnutp |grep sshd
/etc/init.d/sshd restart 重启ssh服务
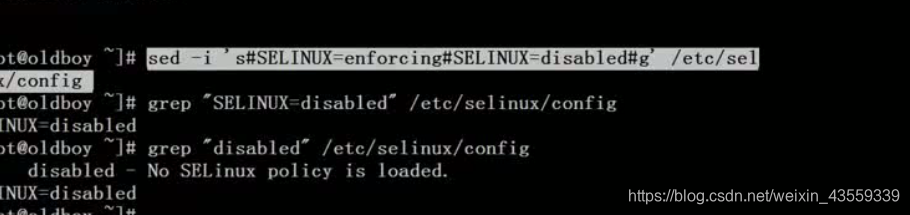
26.
27.useradd 添加用户 语法: useradd 用户名 ,例子: useradd oldbay
28.pass我的 为用户设置或修改密码 例子 : passwd oldboy 为lodbay设置修改密码,
直接passwd 是当前用户修改密码
29.uname 打印系统信息 -m 32or64 -r内核版本 -a(all) -n(显示主机名) hostname 命令 显示和设置主机名 默认是显示主机名,设置主机名可以hostname 名字(临时生效)
30.runlevel:查看当前系统运行级别
31.init:切换运行级别,后面接对应级别的数字,例如:init6 就是重启limnux服务器了。
32.shutdown(halt、init0) 关机
关机 shoutdown -h now
-r reboot after shutdown
-h halt or power off affter shoutdown
33.reboot (init6) 重启 shoutdown -r now
34.history 查看及清理历史信息 -c 清空所有 -d 删除指定历史纪录
35. ifup 和ifdown 启动和停止网卡,可以接网卡名 ifup eth0
相对路径和绝对路径
windows绝对路径
/etc/
磁盘空间满了,是由两项参数决定:
第一个是inode是否满了,第二个block是否满了,任何一项满了,都无法工作。
磁盘满了的一个特征 (on space on device left)
有关indoe的小结:学会给阶段性的只是做小结,
软硬链接的区别

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









