




 本文详细介绍了Hive的基本架构,包括元数据、客户端、Driver及Hadoop组件。强调了Hive对大小写不敏感,适合读多写少的数据仓库应用,并指出其不支持索引,但可通过分区表提高查询效率。讨论了数据类型、数据格式转换、内外部表的区别,以及建表和数据导入的方法。此外,还分享了Hive的优化技巧,如开启并行运算、压缩存储、分区表策略、GROUP BY语句优化和使用Tez引擎提升性能。最后提到了窗口函数的应用。
本文详细介绍了Hive的基本架构,包括元数据、客户端、Driver及Hadoop组件。强调了Hive对大小写不敏感,适合读多写少的数据仓库应用,并指出其不支持索引,但可通过分区表提高查询效率。讨论了数据类型、数据格式转换、内外部表的区别,以及建表和数据导入的方法。此外,还分享了Hive的优化技巧,如开启并行运算、压缩存储、分区表策略、GROUP BY语句优化和使用Tez引擎提升性能。最后提到了窗口函数的应用。
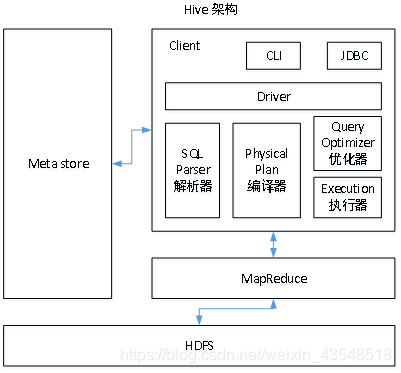
hive的基本架构
包括元数据metastore 、client 、driver 、hadoop(hdfs存储+mr运算)
其中driver包括四部分:解析器 、编译器 、优化器、 执行器
如下图
hive中注意事项
(1)hive 中对大小写不敏感
(2)Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的,
要修改也是直接覆盖★★
(3)hive中没有索引,查询的时候需要全表扫描,引入了分区表加快查询速度
(4)hive底层也是mr,运算也有延迟 不能做实时计算
hive中数据类型
和java 数据类型很相似,但是新增了timestamp 时间戳格式
字符串是string 不是varchar
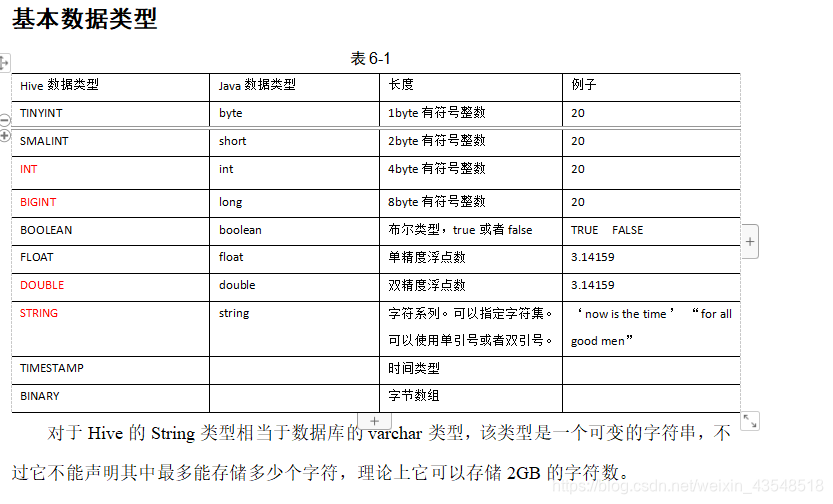
hive的数据类型和mysql数据类型基本一致(除了字符串类型)★★
hive中数据格式转换
类似于Java的类型转换,自动向上推断
即任何整数类型都可以隐式地转换为一个范围更广的类型
也可以使用cast 进行转换,转换失败返回true
CAST(‘1’ AS INT)将把字符串’1’ 转换成整数1;如果强制类型转换失败,如执行CAST(‘X’ AS INT),表达式返回空值 NULL。
外部表和内部表区别
外部表表数据不由hive管理
内部表数据有hive管理
删除外部表,数据不会删除
删除
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8186
8186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









