







Hadoop3.x高可用集群搭建流程
本文基于尚硅谷Hadoop3.x搭建高可用集群文档,hadoop版本为hadoop3.1.3,用于记录自己实操部署的过程和可能存在的问题。
一、搭建HDFS-HA
1.准备三台节点(物理机或虚拟机都行)
按照尚硅谷前置资料Hadoop3.x学习资料搭建好三台hadoop3.1.3版本的节点,包括:
修改好网络ip,
配置ssh免密登录、
安装jdk和hadoop3.1.3
添加相关环境变量及各节点间通信。
2.手动配置HDFS-HA
手动配置的参数配置比较复杂,可能实际应用较多的是自动配置
目标配置成的高可用集群规划如下:

修改相关的xml文件:core-site.xml, hdfs-site.xml
core-site.xml:
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>**/home/zbq/opt/module/hadoop**/data</value>
</property>
</configuration>
加粗部分更改为自己的文件所在目录
hdfs-site.xml:
<configuration>
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>hadoop103:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>hadoop103:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value>
</property>
<!-- 访问代理类:client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/**zbq**/.ssh/id_rsa</value>
</property>
</configuration>
加粗部分为自己的用户目录名,另外主机名(hadoop101等)具体需要根据自己的主机名更改
最后分发配置文件到所有节点,可以手动分发也可以编写分发脚本。
启动集群
在每个节点都启动journalNode
[zbq@hadoop102~]$ hdfs --daemon start journalnode
[zbq@hadoop103~]$ hdfs --daemon start journalnode
[zbq@hadoop104~]$ hdfs --daemon start journalnode
在nn1上格式化并启动
[zbq@hadoop102~]$ hdfs namenode -format
[zbq@hadoop102~]$ hdfs --daemon start namenode
在其余节点上同步nn1的元数据信息
[zbq@hadoop103~]$ hdfs namenode -bootstrapStandBy
[zbq@hadoop104~]$ hdfs namenode -bootstrapStandBy
启动nn2和nn3
[zbq@hadoop103~]$ hdfs --daemon start namenode
[zbq@hadoop104~]$ hdfs --daemon start namenode
这里如果节点较多的话也是需要编写启动脚本的,这里暂不做记录
在网页端查看,由于没有active节点,所有节点对外都是standBy状态
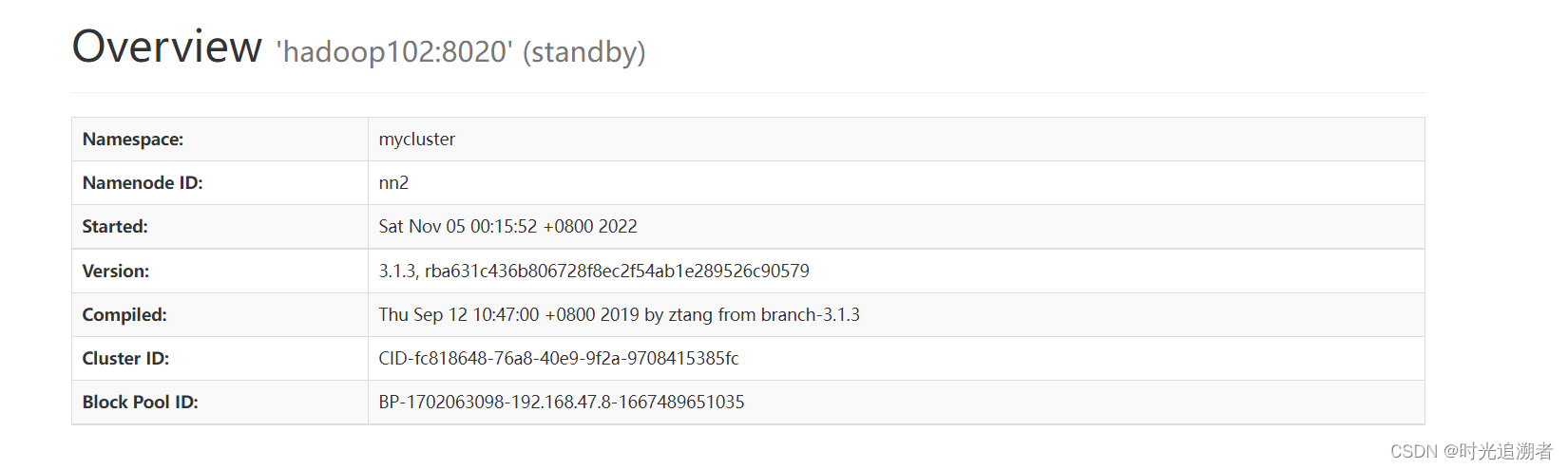
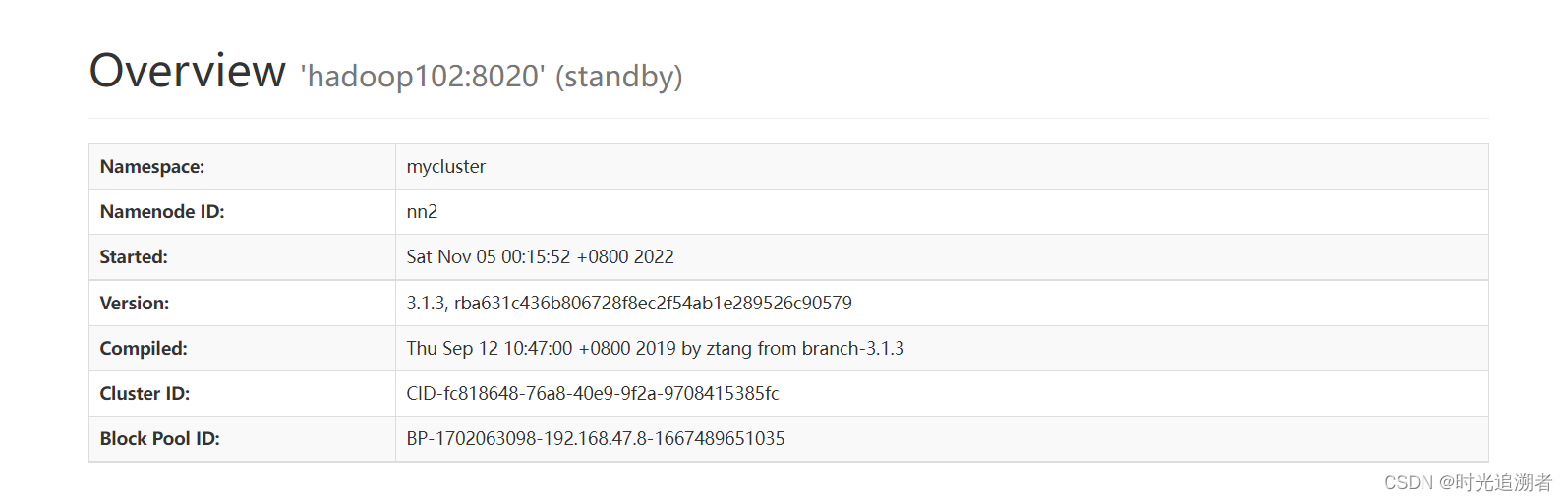
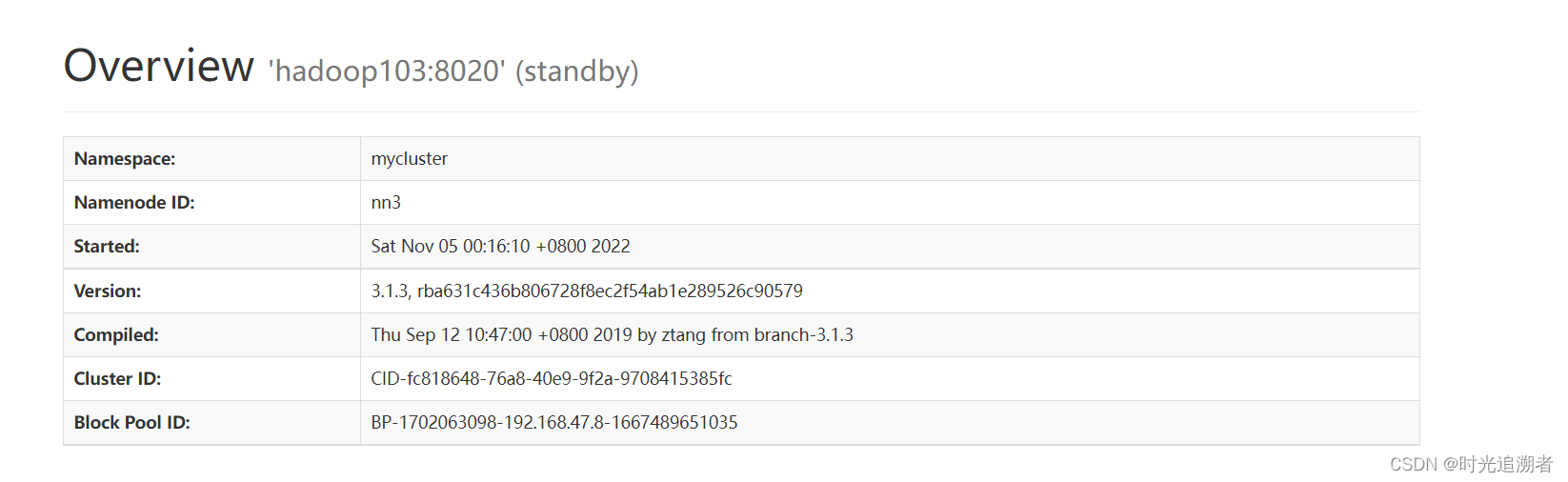
在所有节点启动datanode
[zbq@hadoop101~]$ hdfs --daemon start datanode
[zbq@hadoop102~]$ hdfs --daemon start datanode
[zbq@hadoop103~]$ hdfs --daemon start datanode
将nn1设置为active
[zbq@hadoop101~]$ hdfs haadmin -transitionToActive nn1
可以查看当前节点状态
[zbq@hadoop101~]$ hdfs haadmin -getServiceState nn1
3.HDFS-HA自动模式搭建
手动配置的问题就是如果节点挂了没法故障转移,比如我的hadoop101挂了,其他的两个节点还是傻傻的standby,那么集群就无法对外提供服务了。因此这里要进行HDFS-HA的自动模式搭建起到自动故障转移的作用。
自动故障转移规划,起始就是通过Zookeeper来进行协调处理。
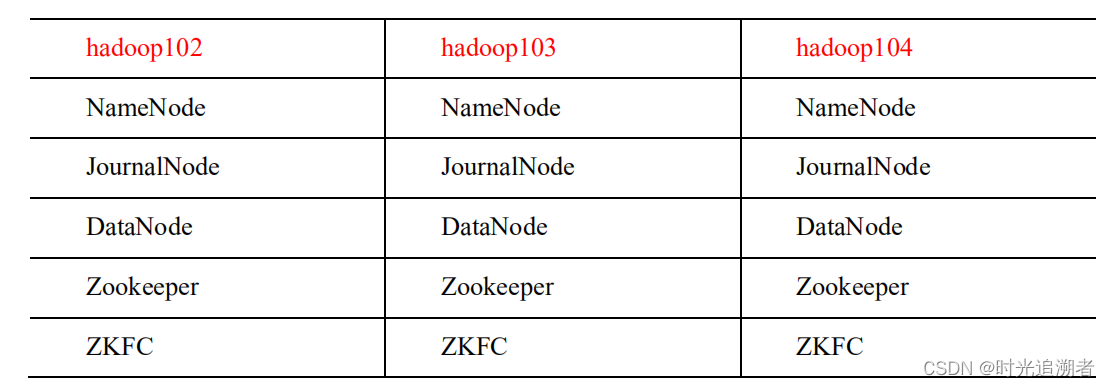
修改配置文件
分别修改core-site.xml和hdfs-site.xml
core-site.xml
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property>
hdfs-site.xml
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
分发文件给其他节点,关闭之前HDFS服务
[zbq@hadoop101~]$ stop-dfs.sh
启动集群
启动zookeeper
[zbq@hadoop101~]$ zkServer.sh start
[zbq@hadoop102~]$ zkServer.sh start
[zbq@hadoop103~]$ zkServer.sh start
启动HDFS服务
[zbq@hadoop101~]$ start-dfs.sh
此时在web-ui界面看到的和之前的一样,但是手动kill掉namenode进程模拟节点挂掉的时候会出发自动故障转移到其他的节点。
这里可能会遇到一个问题,就是默认安装的minimal-centos系统缺少一个插件,会导致节点故障时无法触发转移机制,需要在每个节点偶读安装一遍
yum install -y psmisc
二、搭建Yarn-HA集群
在搭建好的HDFS-HA基础上直接进行yarn-site.xml的修改,具体参数可以参照官网官方文档中关于yarn-default.xml的配置,这里根据文档列出需要配置的参数。

修改配置文件
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop102:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop102:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop102:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop102:8031</value>
</property>
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop103:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop103:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>hadoop104</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>hadoop104:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>hadoop104:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>hadoop104:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>hadoop104:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
和HDFS-HA一样,将节点名称更改为自己的hostname
分发文件到其他节点
编写xsync脚本或者手工rsync皆可
启动yarn
以在hadoop101上启动为例
[zbq@hadoop101~]$ start-yarn.sh
查看服务状态
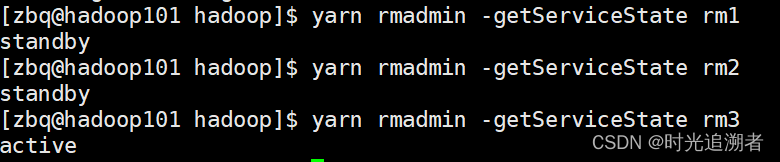
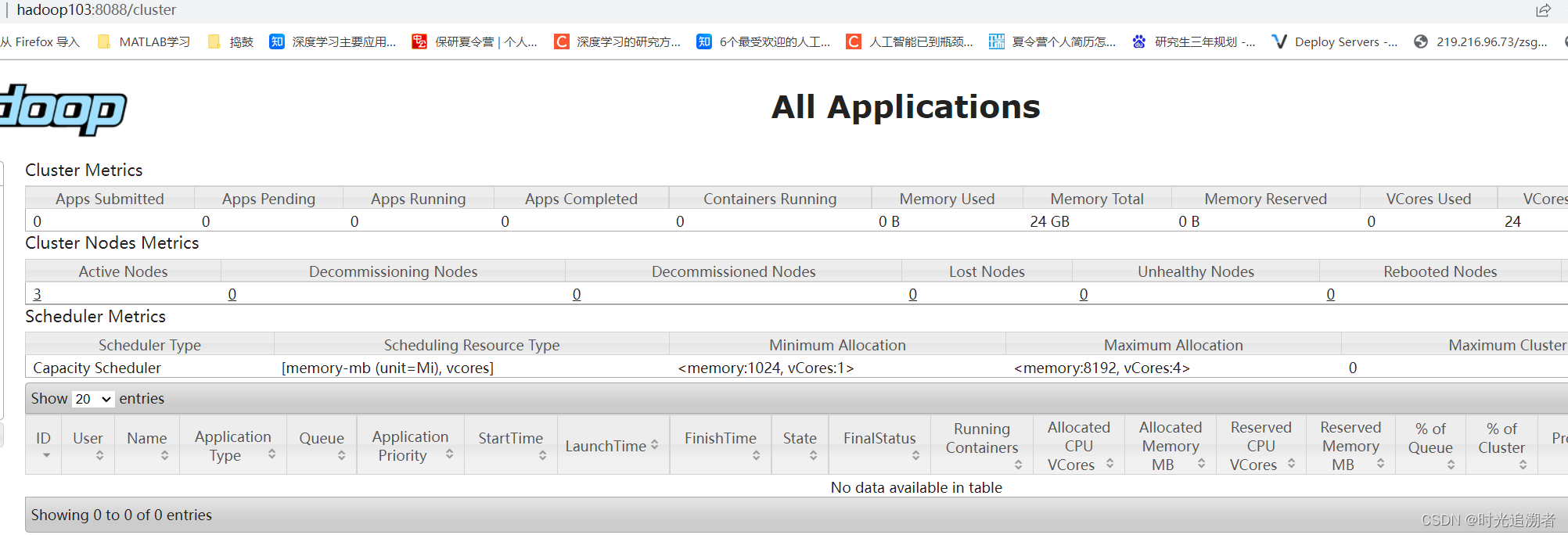
此时在web-ui界面无论ip地址输入hadoop103:8088还是其他节点,都会自动跳转到hadoop103:8088/cluster
参考:
《尚硅谷 Hadoop-HA高可用》pdf

















 2803
2803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









