







2021selenium+chrome爬取BOSS直聘指定字段热门城市岗位信息
心得
登录之后可以抓取更多数据
浏览器打开BOSS之后让程序sleep()一会 然后趁这个时间登录一次
不做其他操作的话,每个城市每个关键字大致会显示10页数据
用requests和 scrapy爬, cookie 操作要很熟练,真是难为人
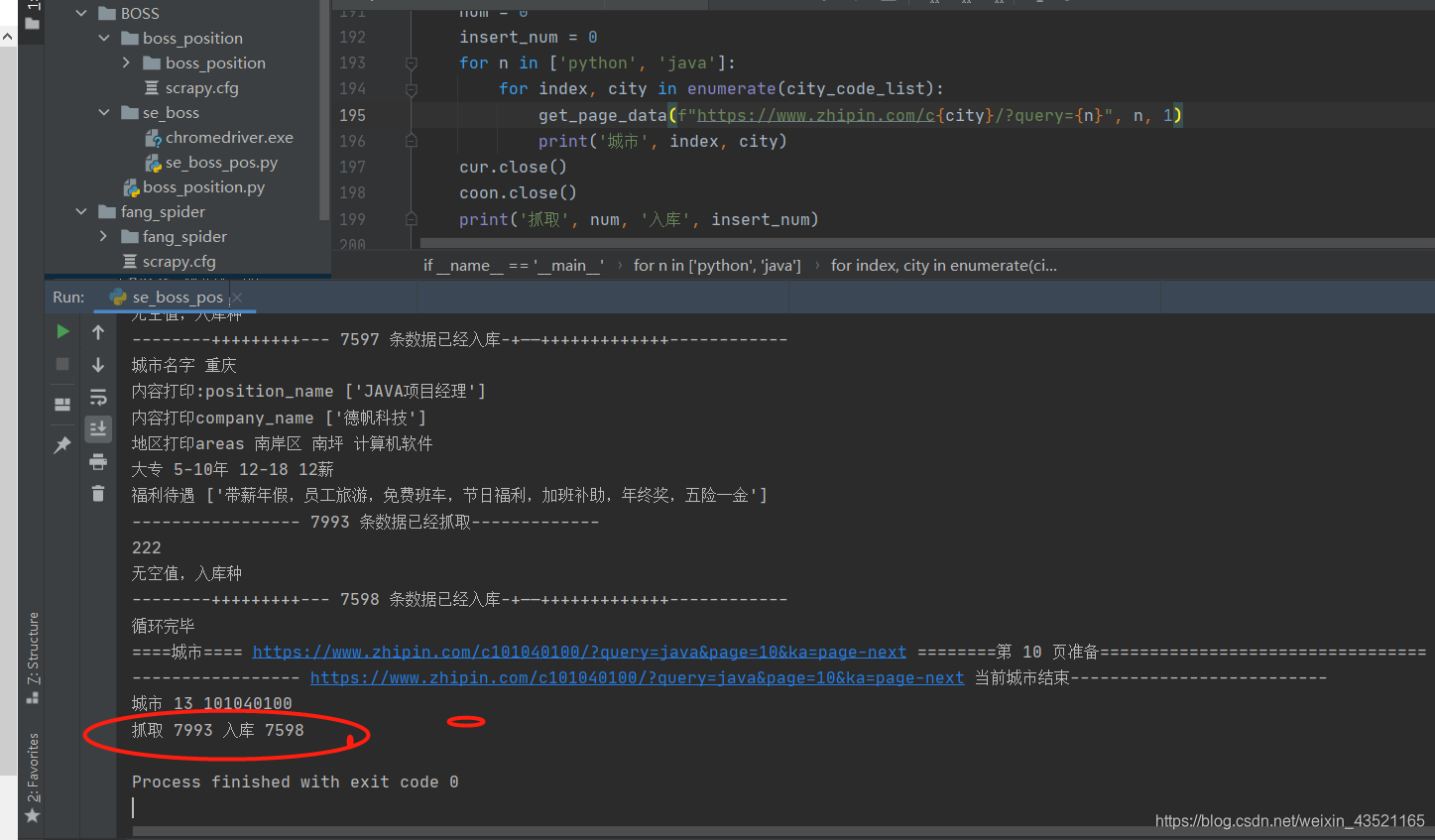
最终效果
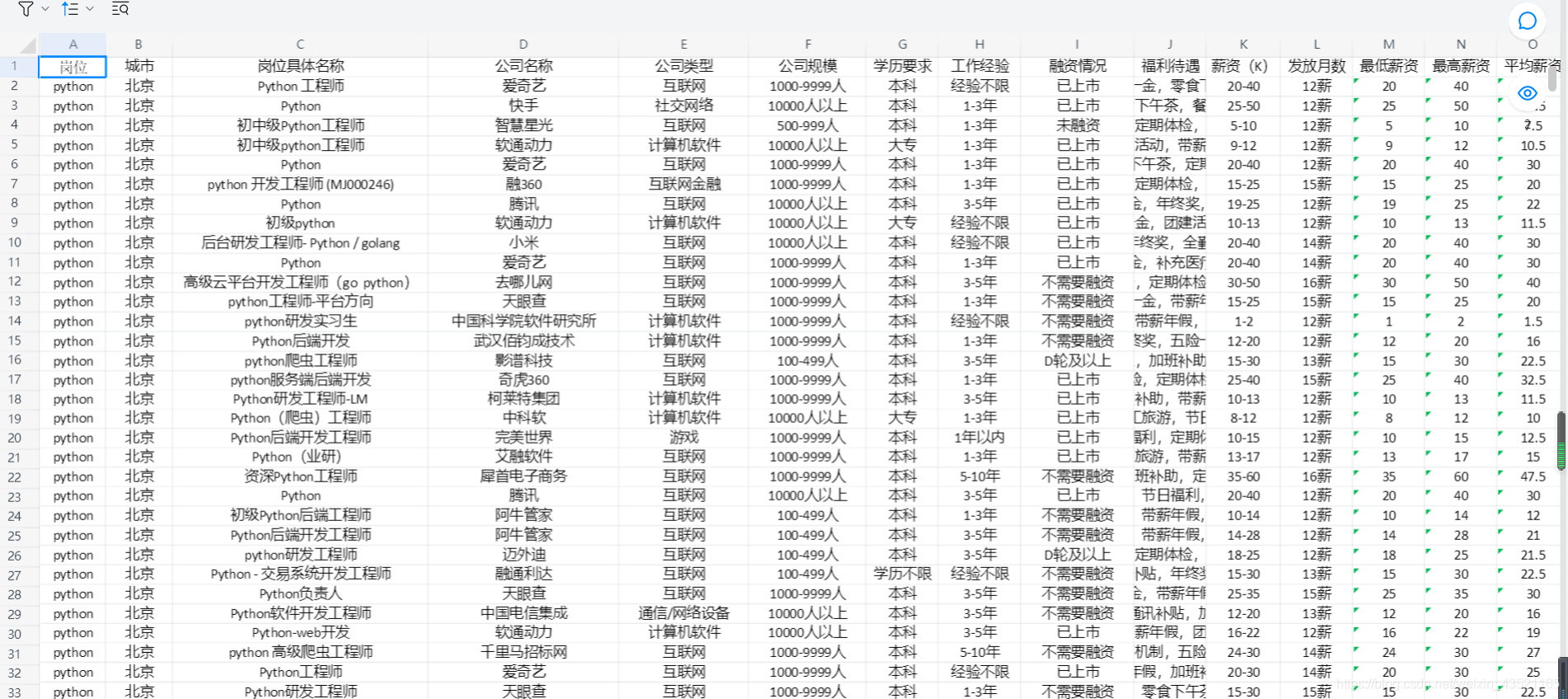
文件概览
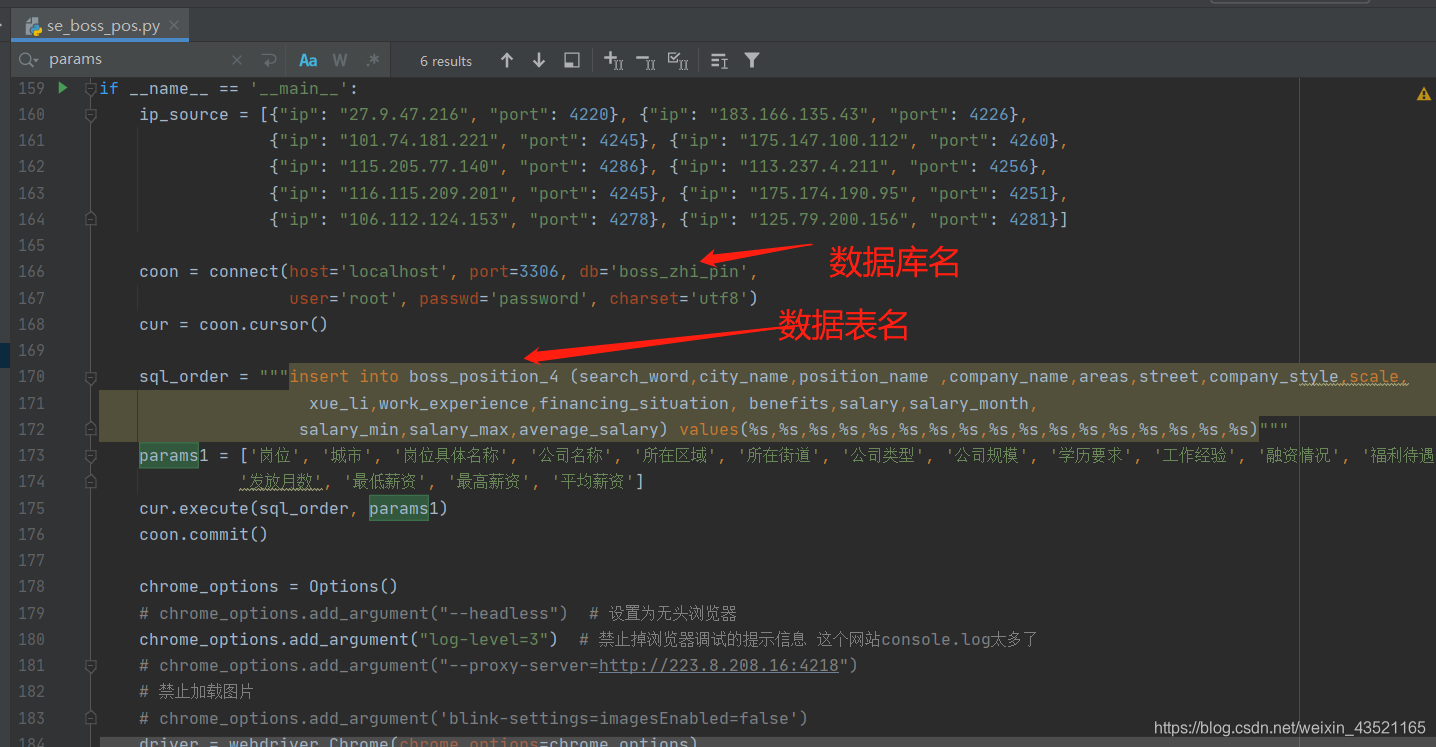
要先创建好数据库 和 数据表 这里时mysql数据库
定义搜索关键字
直接上代码 随时用 随时拿
# 运行此文件需要先下载安装谷歌的浏览器驱动exe 然后把代码文件和驱动放在一起即可
from selenium import webdriver # 导入 webdriver
# 要想调用键盘按键操作需要引入keys包 比如 回车和ctrl键
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
import time
from lxml import etree
from pymysql import *
# 每个城市首次访问时 进来这里拿页面全部关键li数据
def get_page_data(city_url, search_word, t):
# # 访问目标网址
# driver.get(city_url)
if t == 0:
print('9秒时间,快去扫码登录,每访问新的城市,我也暂停8秒')
time.sleep(9) # 第一此访问时可以手动点击扫描登录 这样能拿到的数据更多
driver.get(city_url)
WebDriverWait(driver, 8).until(
EC.presence_of_element_located(
(By.XPATH, "//div[@class='job-list']//ul//li")) # 通过XPATH查找
)
con = etree.HTML(driver.page_source)
page_parse(con, search_word)
def page_parse(con, search_word2):
print(type(con))
global num
global insert_num
content_now_page = con.xpath("//div[@class='job-list']//ul//li")
# content_now_page[1].xpath("(.//div[@class='company-text'])/h3/a/text()") # 公司名称
# areas_all = content_now_page[1].xpath("(.//span[@class='job-area'])/text()") # 所在区域 海淀区 朝阳区。。
for i in content_now_page:
# city_name = con.xpath("//dd[@class='city-wrapper']/a/text()")[0].strip()
# print('城市名字2', city_name)
try:
city_name = con.xpath("//dd[@class='city-wrapper']/a/text()")[0].strip()
search_word = search_word2
print('城市名字', city_name)
position_name = i.xpath("(.//span[@class='job-name'])/a/text()") # 职位名称
company_name = i.xpath("(.//div[@class='company-text'])/h3/a/text()") # 公司名称
areas_all = i.xpath("(.//span[@class='job-area'])/text()") # 所在区域 海淀区 朝阳区。。
# print(areas_all)
areas_detail = areas_all[0].split('·')
if len(areas_detail) == 3:
areas = areas_detail[1] # 海淀区
street = areas_detail[-1] # 所在具体街区 东北旺
elif len(areas_detail) == 2:
areas = areas_detail[1] # 海淀区
street = ''
else:
areas = ''
street = ''
company_info = i.xpath("(.//div[@class='company-text'])/p//text()")
company_style = company_info[0] # 公司类别
print('内容打印:position_name', position_name)
print('内容打印company_name', company_name)
print('地区打印areas', areas, street, company_style)
financing_situation = company_info[1] # 融资情况
scale = company_info[2] # 公司规模
yao_qiu = i.xpath("(.//div[contains(@class,'job-limit')])//text()") # 要求
w = []
for i2 in yao_qiu:
if len(i2.strip()) >= 2:
w.append(i2)
# print(w)
xue_li = w[2] # 学历要求
work_experience = w[1] # 工作经验要求
if 'K' in w[0].split('·')[0] and '天' not in w[0].split('·')[0]:
salary = w[0].split('·')[0].replace('K', '') # 薪资范围
salary_min = salary.split('-')[0] # 薪资范围最小值
salary_max = salary.split('-')[1] # 薪资范围最大值
average_salary = round((float(salary_min) + float(salary_max)) / 2, 2) # 薪资中位值 保留一位小数
try:
salary_month = w[0].split('·')[1] # 薪资月数 13薪 15薪
except:
salary_month = '12薪'
print(xue_li, work_experience, salary, salary_month)
benefits = i.xpath("(.//div[@class='info-desc'])/text()") # 福利待遇
print('福利待遇', benefits)
num += 1
print('-----------------', num, '条数据已经抓取-------------')
else:
continue
# city_code = city_code_list[0] # 城市代码
# rl_detail_page = driver.current_url # 当前网页地址
print(222)
params_kong = [search_word, city_name, position_name, company_name, company_style, scale,
xue_li, work_experience, financing_situation, benefits, salary, salary_month,
salary_min, salary_max, average_salary]
params = [search_word, city_name, position_name,company_name,areas,street, company_style, scale,
xue_li, work_experience, financing_situation, benefits, salary, salary_month,
salary_min, salary_max, average_salary]
none_data = 1
for zi_duan in params_kong:
if len(str(zi_duan)) == 0:
none_data = 0
print(num - insert_num, '有空值')
break
else:
none_data = 1
if none_data == 1:
print('无空值,入库种')
cur.execute(sql_order, params)
coon.commit()
insert_num += 1
print('--------+++++++++---', insert_num, '条数据已经入库-+——+++++++++++++------------')
else:
print(none_data, '无法入库')
except:
continue
print('循环完毕')
time.sleep(1)
next_page(search_word2)
def next_page(search_word2):
global page
page += 1
print('====城市====', driver.current_url, '========第', page, '页准备=================================')
# for i in range(1,9):
# print('循环到第',i,'页')
try:
element_next = WebDriverWait(driver, 8).until(
EC.presence_of_element_located(
(By.XPATH, "//div[@class='page']//a[@class='next']")) # 通过XPATH查找
)
element_next.click()
WebDriverWait(driver, 8).until(
EC.presence_of_element_located(
(By.XPATH, "//div[@class='job-list']//ul//li")) # 通过XPATH查找
)
con = etree.HTML(driver.page_source)
page_parse(con, search_word2)
except:
print('-----------------', driver.current_url, '当前城市结束--------------------------')
page = 0
if __name__ == '__main__':
ip_source = [{"ip": "27.9.47.216", "port": 4220}, {"ip": "183.166.135.43", "port": 4226},
{"ip": "101.74.181.221", "port": 4245}, {"ip": "175.147.100.112", "port": 4260},
{"ip": "115.205.77.140", "port": 4286}, {"ip": "113.237.4.211", "port": 4256},
{"ip": "116.115.209.201", "port": 4245}, {"ip": "175.174.190.95", "port": 4251},
{"ip": "106.112.124.153", "port": 4278}, {"ip": "125.79.200.156", "port": 4281}]
coon = connect(host='localhost', port=3306, db='boss_zhi_pin',
user='root', passwd='password', charset='utf8')
cur = coon.cursor()
sql_order = """insert into boss_position_4 (search_word,city_name,position_name ,company_name,areas,street,company_style,scale,
xue_li,work_experience,financing_situation, benefits,salary,salary_month,
salary_min,salary_max,average_salary) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
params1 = ['岗位', '城市', '岗位具体名称', '公司名称', '所在区域', '所在街道', '公司类型', '公司规模', '学历要求', '工作经验', '融资情况', '福利待遇', '薪资(K)',
'发放月数', '最低薪资', '最高薪资', '平均薪资']
cur.execute(sql_order, params1)
coon.commit()
chrome_options = Options()
# chrome_options.add_argument("--headless") # 设置为无头浏览器
chrome_options.add_argument("log-level=3") # 禁止掉浏览器调试的提示信息 这个网站console.log太多了
# chrome_options.add_argument("--proxy-server=http://223.8.208.16:4218")
# 禁止加载图片
# chrome_options.add_argument('blink-settings=imagesEnabled=false')
driver = webdriver.Chrome(chrome_options=chrome_options)
print('抓紧登录,不登陆也可以,数据相对较少')
driver.get('https://www.zhipin.com/beijing/')
# 城市的url代号
city_code_list = ['101010100', '101020100', '101280100', '101280600', '101210100', '101030100', '101110100',
'101190400', '101200100', '101230200', '101250100', '101270100', '101180100', '101040100']
page = 0
num = 0
insert_num = 0
for n in ['python', 'java']:
for index, city in enumerate(city_code_list):
get_page_data(f"https://www.zhipin.com/c{city}/?query={n}", n, index)
print('城市', index, city)
cur.close()
coon.close()
print('抓取', num, '入库', insert_num)

















 1499
1499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









