







流式计算模型比较分析
一、Spark Streaming
1.1 Spark概述
Spark是UC Berkeley AMP Lab开源的类似于MapReduce的通用的并行计算框架,同时兼顾分布式的并行计算模型和基于内存计算的特点。
Spark优于MapReduce的最大的好处是作业计算的中间结果不需要再像MapReduce一样刷写到hdfs等外部存储,而是保存在内存中,因此不需要与外部存储来回读写,能极大提升性能。
下面为Spark的部署图:
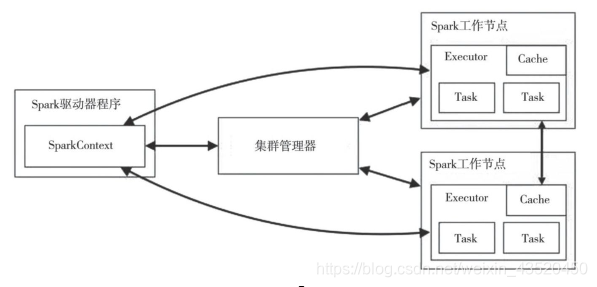
Spark的部署采用Master-Slave模型,运行时会在集群中启动Driver节点和多个Worker节点。Driver在接受客户端提交上来的作业后,建立RDD的血缘关系,记录血缘状态,分发任务到Worker节点上进行计算,并接受所有Worker节点的计算结果。
1.2 Spark Streaming 概述
Spark Streaming是建立在Spark之上的流式计算框架,通过Spark提供的API和基于内存的高速计算引擎,用户可以使用批处理进行micro-batch流式计算,做到代码逻辑上的重复使用。和Spark中的RDD非常相似,Spark Streaming中使用离散化流(Discretized Stream)作为抽象的表示,叫做DStream。
它是随时间推移而收集数据的序列,每个时间段收集到的数据在DStream内以一个RDD的形式存在。
Sp
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6546
6546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









