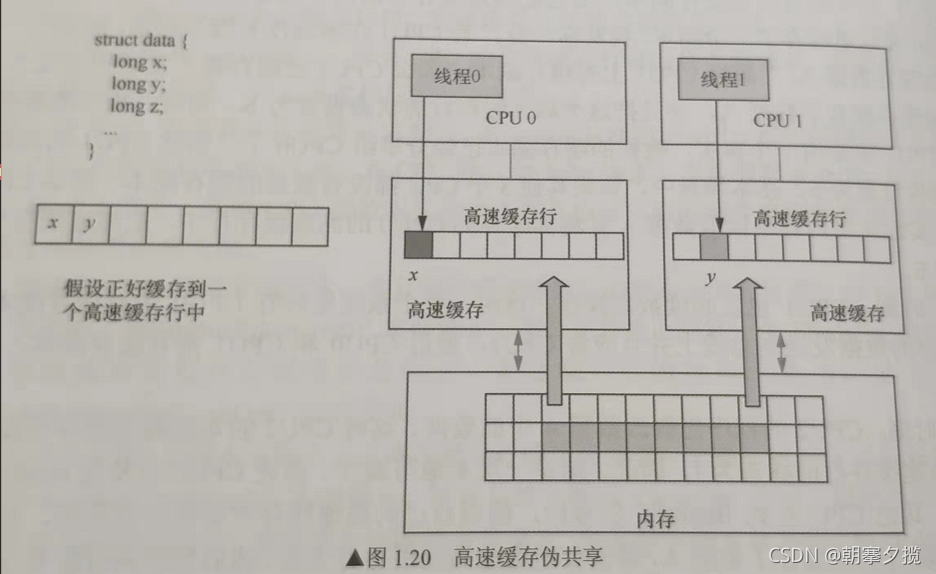
高速缓存伪共享 当多个cpu 访问同一个高速缓存行中的不同数据时,两个cpu 会不断争夺对该高速缓存行的控制权,不断将对方的高速缓存行invalid,导致不断写内存,进而导致性能下降。 解决方法就是让多线程操作的数据处在不同的高速缓存行。如 struct data { long x; long y; long z; } __attribute__(__aligned__((64)))








 本文探讨了高速缓存伪共享问题,当多个CPU核心访问同一缓存行的不同数据时,导致频繁的缓存行失效和内存写入,严重影响性能。为了解决这个问题,文章建议通过数据对齐确保多线程操作的数据位于不同的缓存行,例如使用`__attribute__((__aligned__(64)))`来保证结构体成员对齐。
本文探讨了高速缓存伪共享问题,当多个CPU核心访问同一缓存行的不同数据时,导致频繁的缓存行失效和内存写入,严重影响性能。为了解决这个问题,文章建议通过数据对齐确保多线程操作的数据位于不同的缓存行,例如使用`__attribute__((__aligned__(64)))`来保证结构体成员对齐。

















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






