




论文:https://arxiv.org/pdf/2307.15421
源码:https://github.com/JiangWeibeta/MLIC/tree/main
首先说本人是图像压缩的小白,但是架不住互联网的强大,可以paperswithcode官网上搜到图像压缩模型的排行榜,选择最新的方案作为baseline。
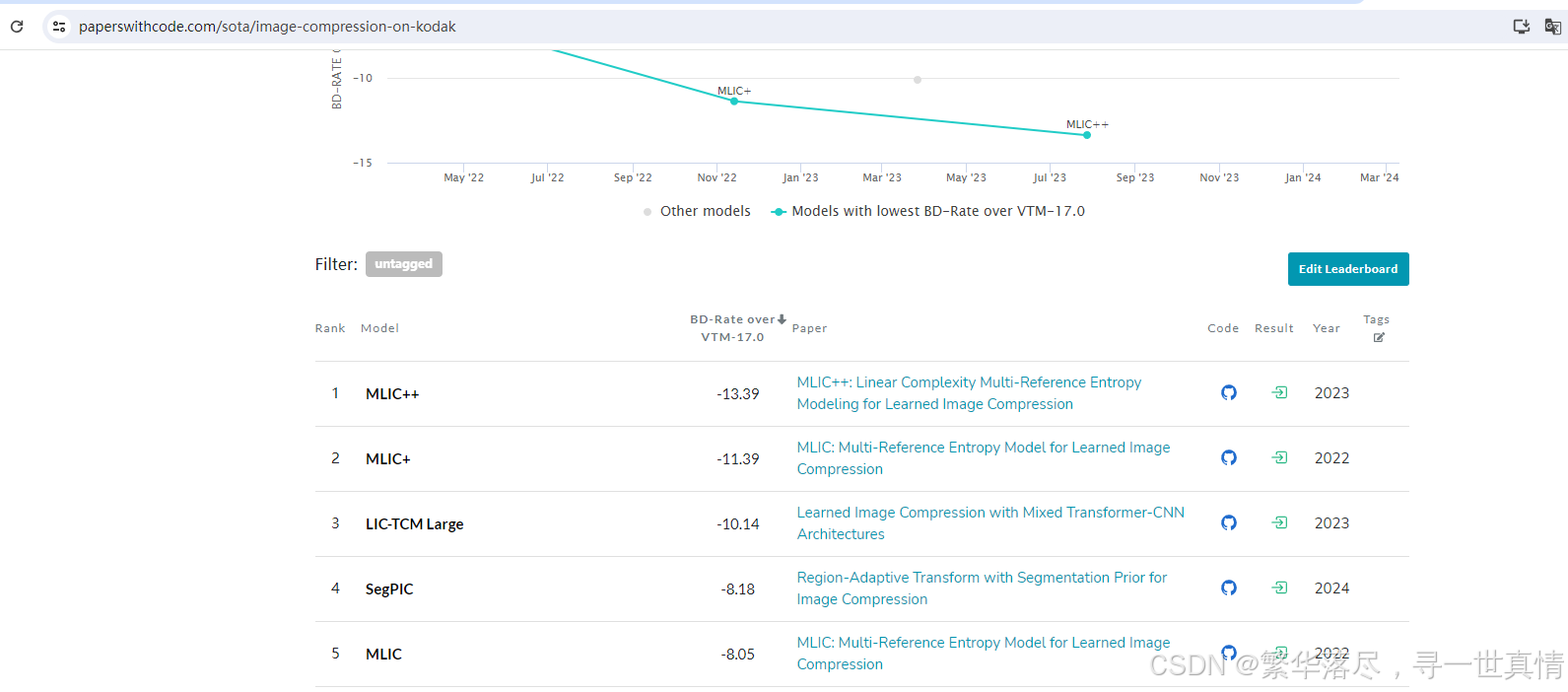
首先说一下问题,解决方法如下文所示:
1.修改后的工程在window和linux下都能正常跑通,但是上传到平台上就报工程中模块找不到的情况,很灵异。
2.自己训练的模型文件熵模型可能需要更新,但是本人不会,就直接将加载的模型的keys值进行修改,就可以正常加载了。
3.Lambda 0.0018~0.0483,也就是第二个红框中的预训练模型需要适配代码才能跑,在mlicpp.py文件中定义LatentResidualPrediction函数。
4.Lambda越小编译出来的码率文件最小。但是解码出来的码率都超过了平台提交的限制,因此还未提交成功。
5.猜想:通过给模型添加质量级别参数,大概可以将码率给降下来quality(int):质量级别(1:最低,最高:8)。
6.该工程尽可能多的集成最新的模型方案,已达到对compressAI的补充。集成
https://github.com/lumingzzz/TIC
https://github.com/wyq2021/s2lic
https://github.com/jmliu206/LIC_TCM
https://github.com/gityuxiliu/segpic-for-image-compression
1.下载源码:
git clone https://github.com/JiangWeibeta/MLIC.git
2.下载预训练模型跑测试(第一个红框可以直接跑测试)
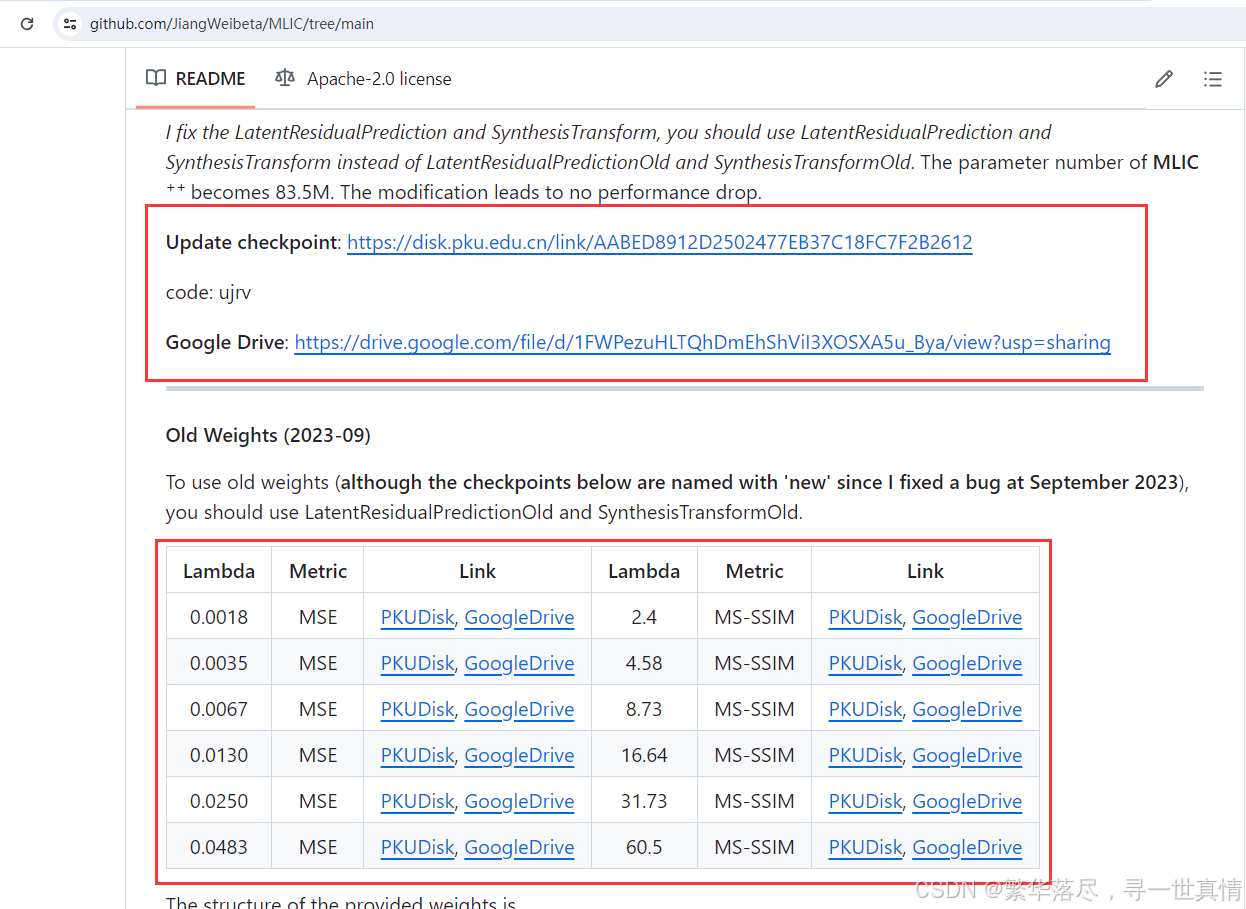
解决办法:
1.修改后的工程在window和linux下都能正常跑通,但是上传到平台上就报工程中模块找不到的情况,很灵异,一直使用sys.path.append条件当前目录到编译器中,始终不能解决,最后通过在mlicpp.py中sys.path.insert和在模块目录下添加__init__.py文件解决。
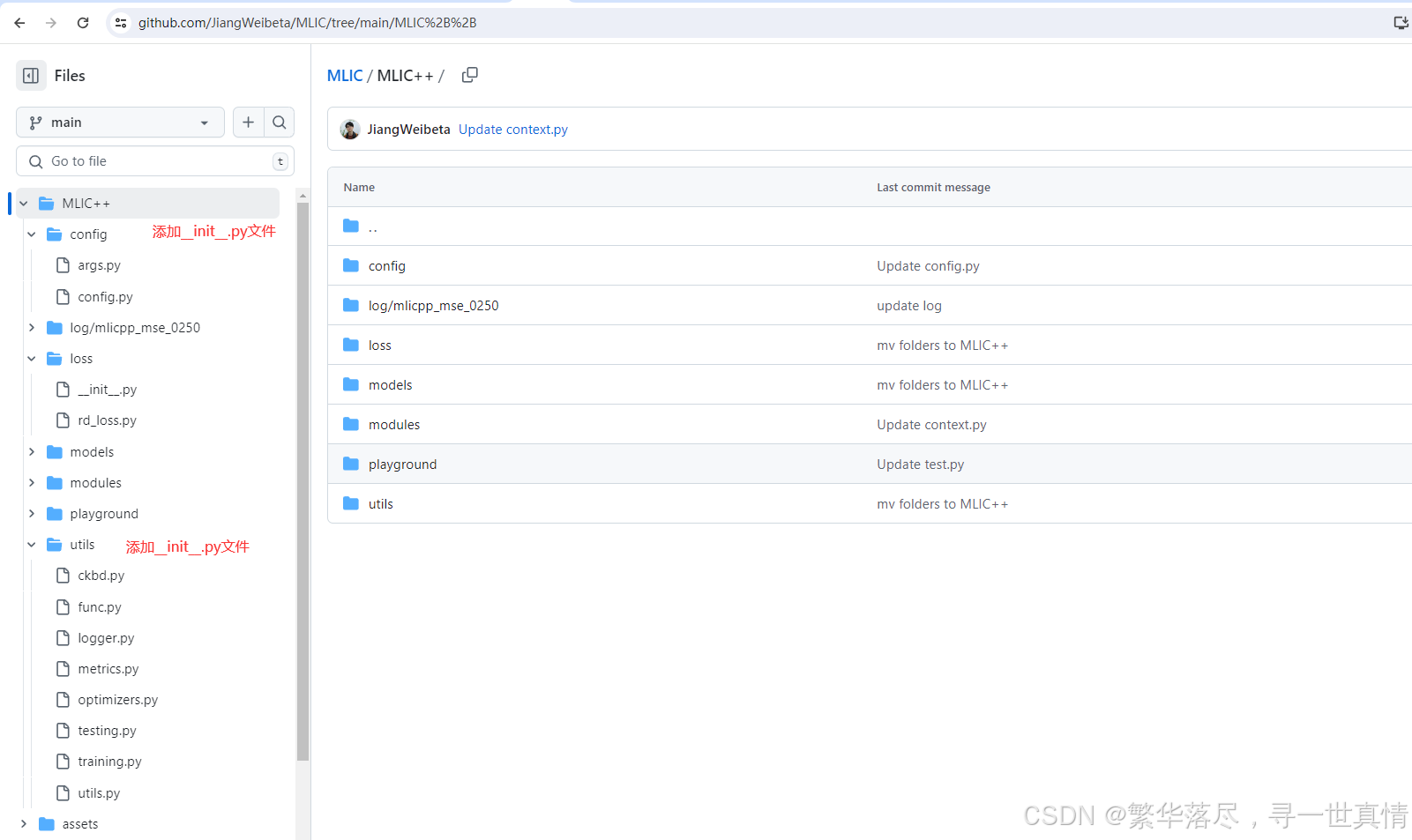
import sys,os
current_directory = os.getcwd()
sys.path.insert(0,current_directory)
2.自己训练的模型文件熵模型可能需要更新,但是本人不会,就直接将加载的模型的keys值进行修改,就可以正常加载了。
checkpoint = torch.load(args.checkpoint)
new_state_dict = OrderedDict()
k_dict = {
"entropy_bottleneck.matrices.0":"entropy_bottleneck._matrix0",
"entropy_bottleneck.biases.0":"entropy_bottleneck._bias0",
"entropy_bottleneck.factors.0":"entropy_bottleneck._factor0",
"entropy_bottleneck.matrices.1": 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









