




示例1:
反推提示词,并生成图片。
实际图和生成图片

操作方式:
1.采用部署的Qwen/Qwen2-VL-2B-Instruct进行生成图片描述
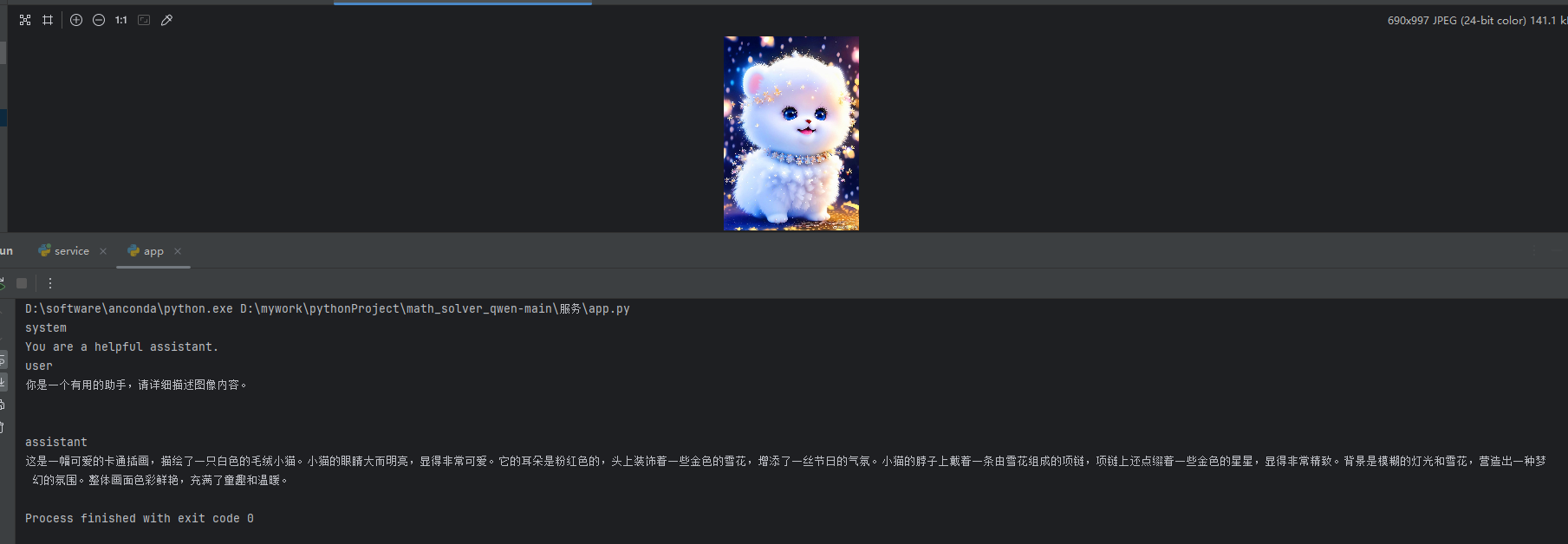
2.在chat.qwen.ai进行绘图
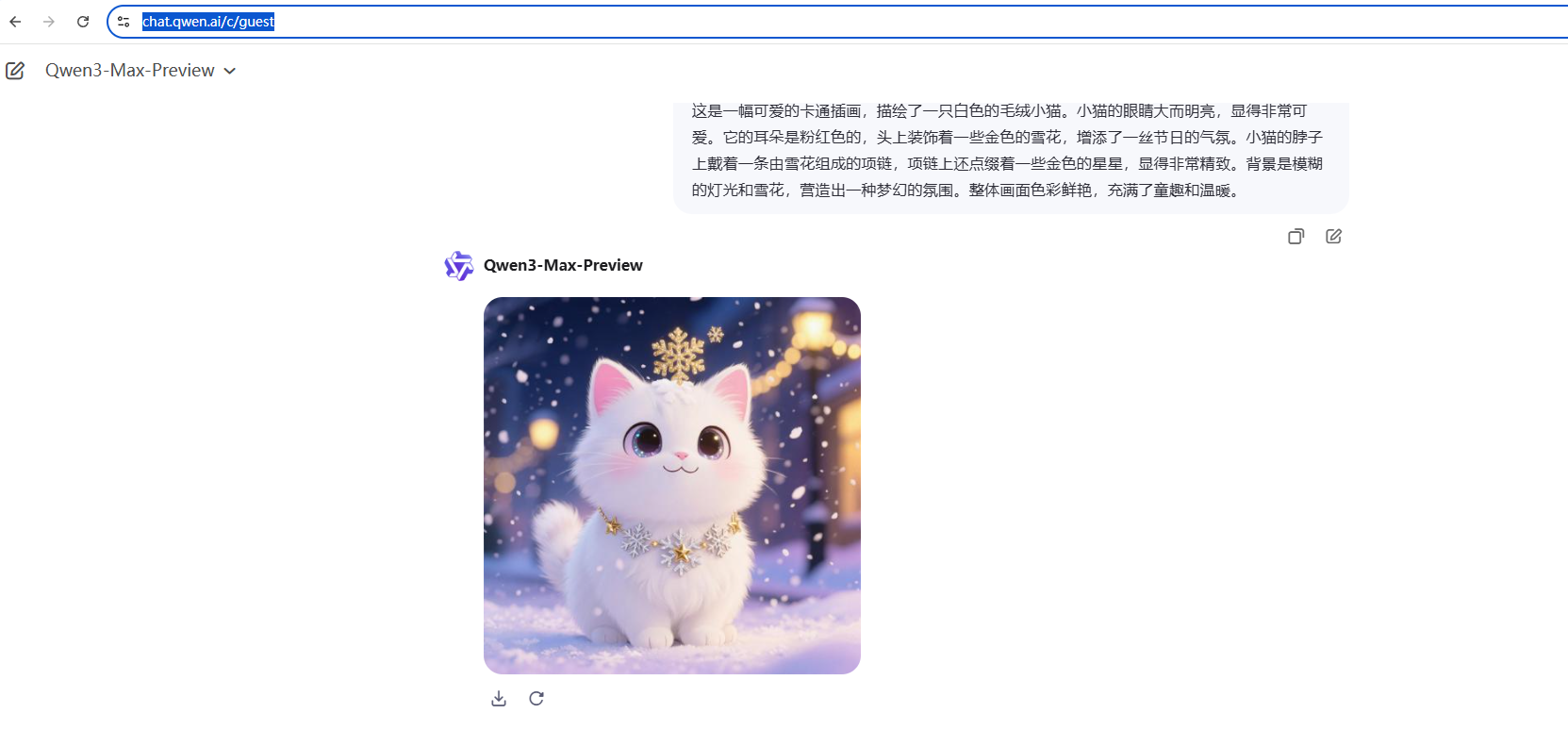
示例2
拍照解题,输入题目图片进行进行解题
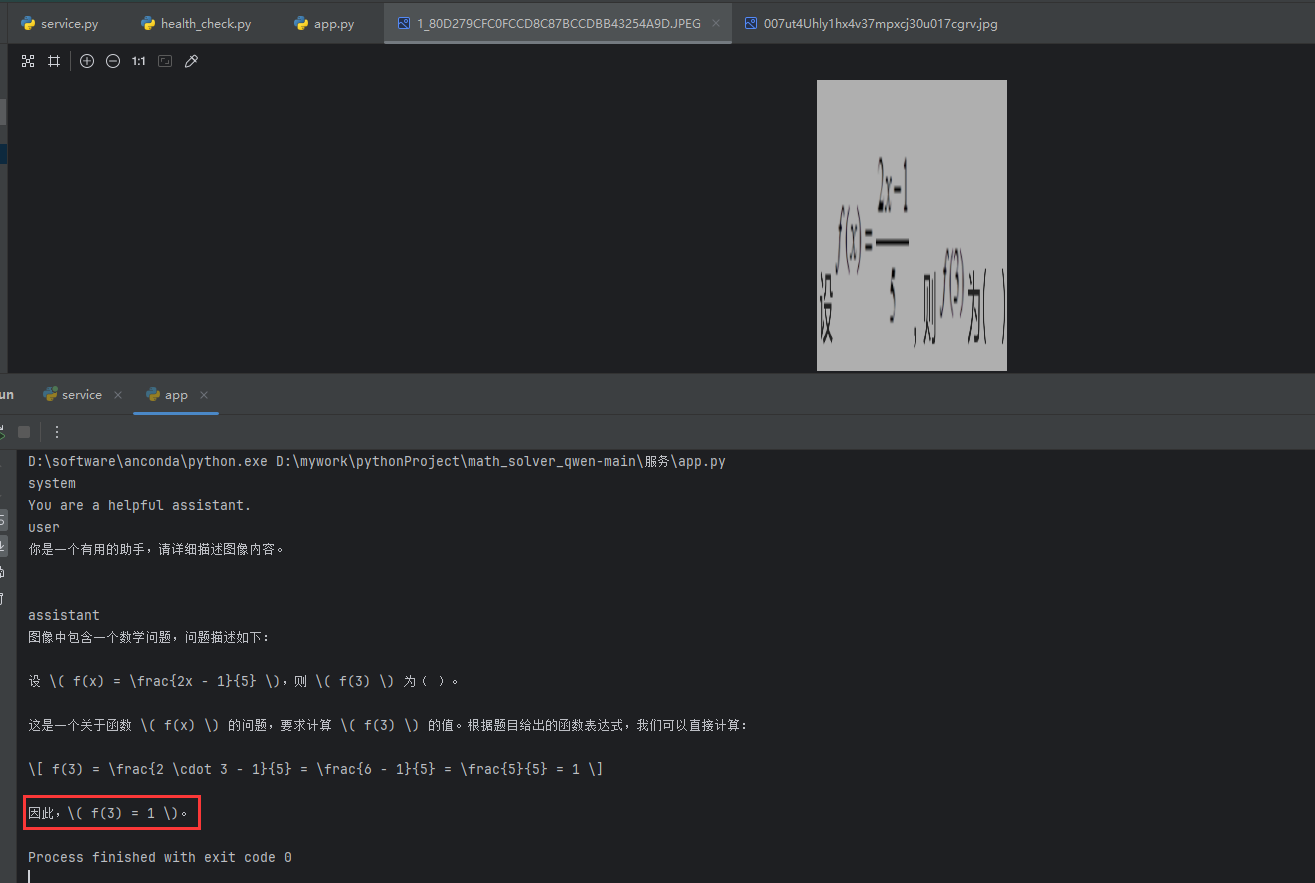
服务端:service.py
import time
import sys
import os
import re
import json
import torch
from PIL import Image
import base64
from io import BytesIO
from flask import Flask, request, jsonify
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
AutoProcessor,
AutoModelForVision2Seq
)
import threading
# 创建Flask应用
app = Flask(__name__)
# 全局变量存储模型实例
vision_model = None
vision_processor = None
device = None
# 初始化锁,防止多线程同时使用模型
model_lock = threading.Lock()
def log(msg, *args, **kwargs):
timestamp = time.strftime("[%Y-%m-%d %H:%M:%S]", time.localtime())
print(f"{
timestamp} {
msg}", flush=True, *args, **kwargs)
def resize_if_needed(image, max_size=1024):
"""如果图像大于指定尺寸,则按比例缩小"""
width, height = image.size
if width > max_size or height > max_size:
# 计算新的尺寸,保持宽高比
ratio = min(max_size / width, max_size / height)
new_width = int(width * ratio)
new_height = int(height * ratio)
resized_img = image.resize((new_width, new_height), Image.LANCZOS)
return resized_img
return image
def initialize_models():
"""初始化模型"""
global vision_model, vision_processor, device
log("Initializing models...")
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
log(f"Using device: {
device}")
# 初始化视觉模型
try:
vision_model_name = "Qwen/Qwen2-VL-2B-Instruct" # 使用更大的模型以获得更好的通用理解能力
vision_processor = AutoProcessor.from_pretrained(vision_model_name)
vision_model = model = AutoModelForVision2Seq.from_pretrained(vision_model_name, torch_dtype=torch.float16)
# 将模型移动到GPU(如果可用)
model.to(device)
log("Vision model loaded successfully")
except Exception as e:
log(f"Error loading vision model: {
e}")
vision_model = None
log("Model initialization completed")
def process_image_and_text(image, text_prompt, max_new_tokens=1024, temperature 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









