




说明
关于正则表达式,对于开发来说,真是太重要了。这个东西主要是用来提取字符串的,所有语言都支持正则表达式,不管是python还是Java等等,还有性能测试工具Jmeter,而且在sql中也支持正则表达式。
如果我们要学习Linux,感觉正则表达式,是一个绕不过去的话题。比如像Linux中经常用到的命令,find,grep,sed,awk都支持正则表达式。
元字符
在茫茫的字符中,我们如何寻找它呢?
第一个概念,元字符,就是我们要匹配的字符串中的单个字符长的是什么样子?
所以我们实际匹配的过程中,需要去分析我们的字符串的特点,比如包含有啥字母,有啥符号,有啥数字,这些特性我们可以提取出来,就是元字符
比如[a-z]代表能够匹配26个字母中的任何一个
比如[0-9] (也可以用\d代替)代表能够匹配0-9的数字中的任何一个
比如[^0-5]除了012345,其它任何字符都行
有一点需要注意,比如要匹配的字符是那种关键字符如*?+等等,需要在前面加\让其失去关键字符的含义
当然还有其他很多元字符,可以参考文章
https://www.runoob.com/regexp/regexp-metachar.html
限定符
第二个概念,限定符,就是我们要匹配的字符串中的字符(也叫元字符)有多少个?我们需要做限定
下图的6个字符非常关键,使用高频,需要记住。
这里面需要明白贪婪匹配和非贪婪匹配,不会可以百度

定位符
第三个概念,定位符就是在茫茫的字符串中,你准备从哪开始匹配?
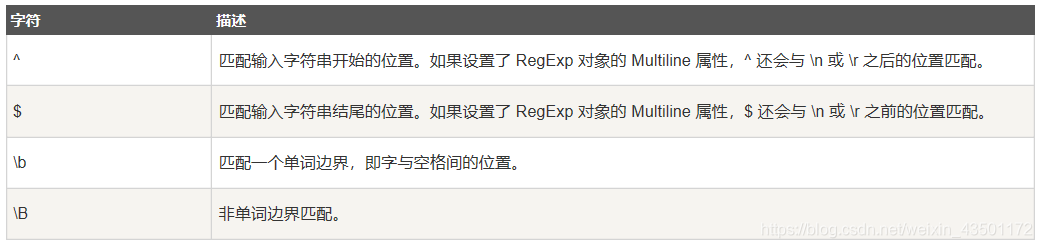
经过前面两个概念,我们提取出了,我们需要匹配的字符串的特征(比如我们想要提取字母[a-z]+),比如我们准备在行首匹配,我们需要加上^,如果在行尾匹配需要用到$,如果匹配单词需要用到\b
如下是具体概念
装饰符
第四个概念,装饰符,经过前面3个概念,我们已经能够匹配到我们需要匹配的字符串了,但是我们还有其他的需求,比如我们想忽略字母的大小写
下面是具体有哪几个装饰符

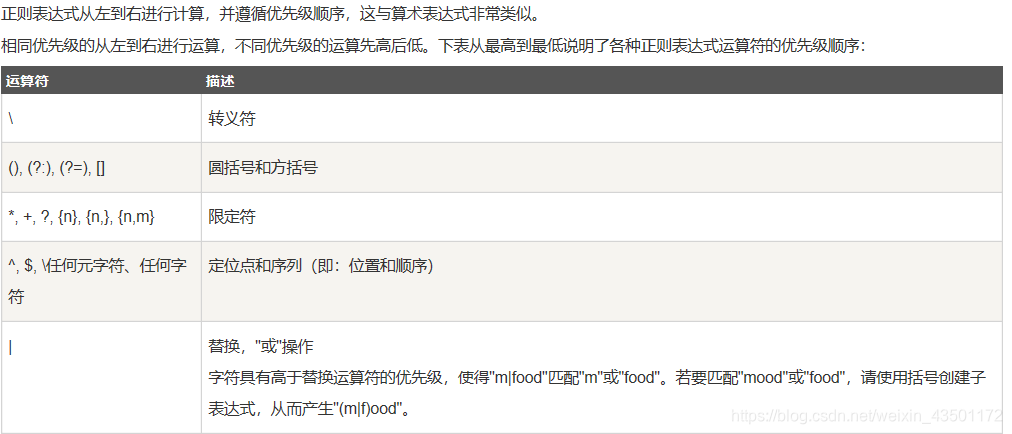
运算符的优先级
这个概念可以跳过,一般程序的运算的优先级都是这样,二来上面的有些概念已经涵盖这些内容,应该除了最后一个‘|’这个没有涉及,其他的都涉及到了。但是看这个字符‘|’,感觉也是分外眼熟,就是或啦
选择
经过这3个概念,我们应该能够在茫茫的字符串中,找到我们所需要的字符串。下面说一下,感觉可能稍微高级一点的用法(主要就是正向查询)
关于选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔,但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用
其中 ?: 是非捕获元之一,还有两个非捕获元是 ?= 和 ?!,这两个还有更多的含义,前者为正向预查,在任何开始匹配圆括号内的正则表达式模式的位置来匹配搜索字符串,后者为负向预查,在任何开始不匹配该正则表达式模式的位置来匹配搜索字符串。
这个概念说起来,比较拗口,自己尝试一下,就什么都明白了。举个列子



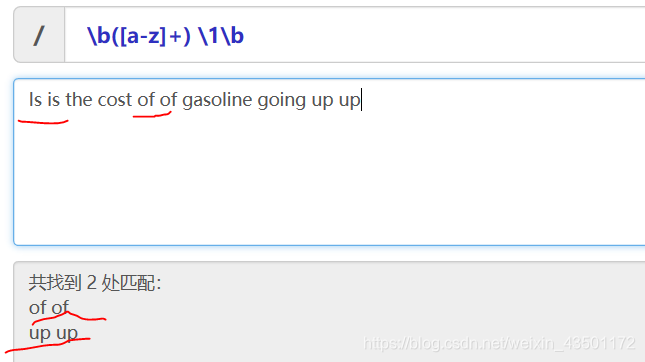
反向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n 访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
举例如下,看完之后,会秒懂反向引用
经典列子(IP,URL,邮箱匹配)
IPv4地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
InternetURL:
[a-zA-z]+://[^\s]* 或 ^http://([\w-]+.)+[\w-]+(/[\w-./?%&=]*)?$
Email地址:
^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$
关于练习正则表达式的网址
http://c.runoob.com/front-end/854
参考链接
关于正则表达式,这里面一篇文章,感觉写的挺好的。
https://www.runoob.com/regexp/regexp-syntax.html


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











