







 本文介绍了HDFS的设计思路、适用场景及不适宜的应用类型,深入解析了其核心架构,包括Namenode与Datanode的角色,以及高可用性(HA)和 Federation 的概念。此外,还探讨了Block、缓存、元数据管理和故障恢复策略。
本文介绍了HDFS的设计思路、适用场景及不适宜的应用类型,深入解析了其核心架构,包括Namenode与Datanode的角色,以及高可用性(HA)和 Federation 的概念。此外,还探讨了Block、缓存、元数据管理和故障恢复策略。
Hadoop的组件_HDFS核心概念_第二章
备注:
如果在阅读的过程中,碰到了不懂的概念可自行查询,或者看 4.HDFS 其他知识点拓展,进行查看是否有您需要的概念解释,希望能够帮助到您!祝学习愉快!
1.HDFS前言
HDFS是分布式文件系统 /(分布式文件管理系统),主要用来解决海量数据的存储问题
在多台机器上管理,(服务器上系统一般装的Linux)提供读取,写入,查看目录信息服务
- 设计思想: 运行于商业硬件上/普通商用机器 , 分而治之,即将大文件,大批量文件,分布式的存放于大量服务器上。以便于采取分而治之的方式对海量数据 (TB或者是PB级别的数据量) 进行运算分析。
- 在大数据系统架构中的应用: 为各类分布式运算框架(MapReduce,Spark,Tez,Flink,…)提供数据存储服务。
- 重点概念: 数据块/副本,负载均衡,心跳机制,副本存放策略,元数据/元数据管理,安全模式,机架感知…
2.HDFS的概念和特性
2.1 HDFS设计思路
HDFS 被设计成用来使用低廉的服务器来进行海量数据的存储,那是怎么做到的呢?
1.大文件被切割成小文件(小文件指副本或者可以称之为‘block’,默认切割3个),使用分而治之的思想 让很多服务器对同一个文件进行联合管理
2. 每个小文件做冗余备份,并且分散存到不同的服务器,做到高可靠不丢失
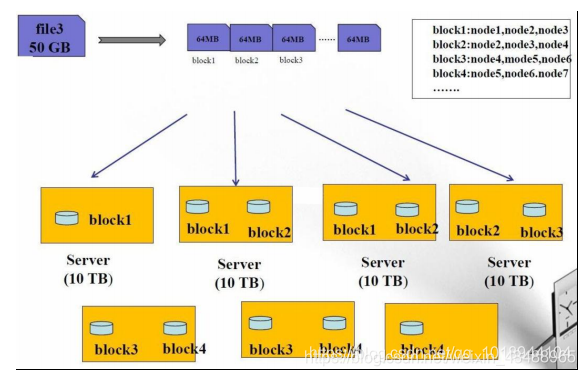
2.2 HDFS 适合的应用类型
1)可构建在廉价机器上
通过多副本提高可靠性,提供了容错和恢复机制
2) 高容错性
数据自动保存多个副本,副本丢失后,自动恢复
3) 适合批处理
移动计算而非数据,数据位置暴露给计算框架
4) 适合大数据处理
GB、TB、甚至 PB 级数据,百万规模以上的文件数量,10K+节点规模
5) 流式文件访问
一次性写入,多次读取,保证数据一致性
2.3 HDFS 不适合的应用类型
有些场景不适合使用HDFS来存储数据。下面列举几个:
1) 低延时的数据访问
对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时HBase更适合低延时的数据访问。
2)大量小文件
文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。
经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持。
3)多方读写,需要任意的文件修改
HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改。不支持多个写入器(writer)。
3. HDFS核心架构和工作机制
HDFS是一套分布式软件系统,里面有很多种服务角色:namenode , SecondaryNamenode , datanode , 客户端…
文件在HDFS中是分块存储的,一个文件会被分成多个块(Block),(默认按128M分块)
每个块(Block)都有唯一的ID
每个块(Block)在HDFS 的 datanode 中都可以存储多个副本!(默认3个副本)
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改!!
(PS:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
额外拓展知识点 : 元数据算是一种电子式目录,包括但不限于 :HDFS系统目录树,每个文件上的具体路径 ,块信息 ,物理存储位置信息 ,副本数量 ,副本ID,并为客户端提供查询服务
主节点 Namenode: 集群老大,存元数据 ,掌管文件系统目录树,处理客户端 读 请求
SecondaryNamenode: 严格说并不是 namenode 备份节点,主要给 namenode 分担压力之用
从节点 Datanode: 存储整个集群所有数据块(block),处理真正数据读写,每一个 block 都可以在多个 datanode 上存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)
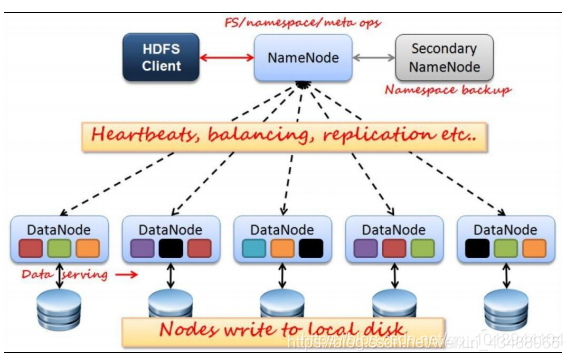
3.1 Namenode & Datanode
集群由Namenode和Datanode构成master-worker(主从)模式。Namenode负责构建命名空间,管理文件的元数据等,而Datanode负责实际存储数据,负责读写工作。
3.1_1 namenode_负责管理元数据:
Namenode存放文件系统树及所有文件、目录的元数据。
元数据持久化为2种形式:
- namespcae
- imageedit log
但是持久化数据中不包括Block所在的节点列表,及文件的Block分布在集群中的哪些节点上,这些信息是在系统重启的时候重新构建(通过Datanode汇报的Block信息)。
在HDFS中,Namenode可能成为集群的单点故障,Namenode不可用时,整个文件系统是不可用的。
HDFS针对单点故障提供了2种解决机制:
1)备份持久化元数据
将文件系统的元数据同时写到多个文件系统, 例如同时将元数据写到本地文件系统及NFS。这些备份操作都是同步的、原子的。
2)Secondary Namenode
Secondary节点定期合并主Namenode的namespace image和edit log, 避免edit log过大,通过创建检查点checkpoint来合并。它会维护一个合并后的namespace image副本, 可用于在Namenode完全崩溃时恢复数据。下图为Secondary Namenode的管理界面:
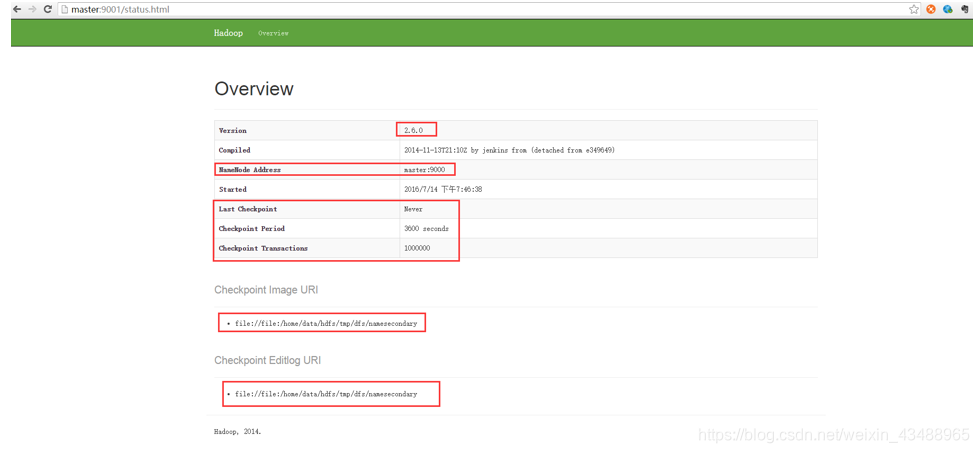
Secondary Namenode通常运行在另一台机器,因为合并操作需要耗费大量的CPU和内存。其数据落后于Namenode,因此当Namenode完全崩溃时,会出现数据丢失。 通常做法是拷贝NFS中的备份元数据到Second,将其作为新的主Namenode。
在HA(High Availability高可用性)中可以运行一个Hot Standby,作为热备份,在Active Namenode故障之后,替代原有Namenode成为Active Namenode。
3.1_2 datanode_负责管理文件块:
数据节点负责存储和提取Block,读 写 请求可能来自namenode,也可能直接来自客户端。数据节点周期性向Namenode汇报自己节点上所存储的Block相关信息。
4.HDFS 其他知识点拓展
4.1 物理磁盘/文件系统/HDFS 的 Blocks(块)概念
物理磁盘:
物理磁盘中有块的概念, Block是磁盘操作最小的单元 ,读写操作均以Block为最小单元,一般为512 Byte。
文件系统:
文件系统在物理Block之上抽象了另一层概念,文件系统的Block 是 物理磁盘Block的整数倍。通常为几KB。Hadoop提供的df、fsck这类运维工具都是在文件系统的Block级别上进行操作。
HDFS:
HDFS的Block块比一般单机文件系统大得多,默认为128M。
HDFS的文件被拆分成block-sized的chunk,chunk作为独立单元存储。
比Block小的文件不会占用整个Block,只会占据实际大小。 例如, 如果一个文件大小为1M,则在HDFS中只会占用1M的空间,而不是128M。
4.2 Block Caching(块缓存)
DataNode通常直接从磁盘读取数据,但是频繁使用的Block可以在内存中缓存。默认情况下,一个Block只有一个数据节点会缓存。但是可以针对每个文件可以个性化配置。
作业调度器可以利用缓存提升性能,例如:MapReduce可以把任务运行在有Block缓存的节点上。
用户或者应用可以向NameNode发送缓存指令(缓存哪个文件,缓存多久), 缓存池的概念用于管理一组缓存的权限和资源。
4.3 HDFS Federation
我们知道NameNode的内存会制约文件数量,HDFS Federation提供了一种横向扩展NameNode的方式。
在Federation模式中,每个NameNode管理命名空间的一部分,例如:一个NameNode管理/user目录下的文件, 另一个NameNode管理/share目录下的文件。
每个NameNode管理一个namespace volumn(命名空间),所有volumn构成文件系统的元数据。
每个NameNode同时维护一个Block Pool,保存Block的节点映射等信息。
各NameNode之间是独立的,一个节点的失败不会导致其他节点管理的文件不可用。
客户端使用mount table将文件路径映射到NameNode。mount table是在Namenode群组之上封装了一层,这一层也是一个Hadoop文件系统的实现,通过viewfs:协议访问。
4.4 HDFS HA(High Availability高可用性)
在HDFS集群中,NameNode依然是单点故障(SPOF: Single Point Of Failure)。元数据同时写到多个文件系统以及Second NameNode定期checkpoint有利于保护数据丢失,但是并不能提高可用性。
这是因为NameNode是唯一一个对文件元数据和file-block映射负责的地方, 当它挂了之后,包括MapReduce在内的作业都无法进行读写。
当NameNode故障时,常规的做法是使用元数据备份重新启动一个NameNode。
元数据备份可能来源于:
多文件系统写入中的备份Second NameNode的检查点文件
启动新的Namenode之后,需要重新配置客户端和DataNode的NameNode信息。另外重启耗时一般比较久,稍具规模的集群重启经常需要几十分钟甚至数小时。
造成重启耗时的原因大致有:
1) 元数据镜像文件载入到内存耗时较长。
2) 需要重放edit log
3) 需要收到来自DataNode的状态报告并且满足条件后才能离开安全模式提供写服务。
4.4_1 Hadoop的HA方案
采用HA的HDFS集群配置有两个NameNode, 分别处于Active和Standby状态。当Active NameNode故障之后,Standby接过责任继续提供服务,用户没有明显的中断感觉。 一般耗时在几十秒到数分钟。
HA涉及到的主要实现逻辑有:
1) 主备需共享edit log存储
主NameNode和待命的NameNode共享一份edit log,当主备切换时,Standby通过回放edit log同步数据。
共享存储通常有2种选择:
- NFS:传统的网络文件系统
- QJM:quorum journal manager
QJM是专门为HDFS的HA实现而设计的,用来提供高可用的edit log。 QJM运行一组journal node,edit log必须写到大部分的journal nodes。通常使用3个节点,因此允许一个节点失败,类似ZooKeeper。注意QJM没有使用ZK,虽然HDFS HA的确使用了ZK来选举主Namenode。一般推荐使用QJM。
2)DataNode需要同时往主/备发送Block Report
因为Block映射数据存储在内存中(不是在磁盘上), 为了在Active NameNode挂掉之后,新的NameNode能够快速启动,不需要等待来自Datanode的Block Report,DataNode需要同时向 主/备 两个NameNode发送Block Report。
3)客户端需要配置failover模式(失效备援模式,对用户透明)
Namenode的切换对客户端来说是无感知的,通过客户端库来实现。客户端在配置文件中使用的HDFS URI是逻辑路径,映射到一对Namenode地址。客户端会不断尝试每一个Namenode地址直到成功。
4)Standby替代Secondary NameNode
如果没有启用HA,HDFS独立运行一个守护进程作为Secondary Namenode。定期checkpoint,合并镜像文件和edit日志。
如果当主Namenode失败时,备份Namenode正在关机(停止 Standby),运维人员依然可以从头启动备份Namenode,这样比没有HA的时候更省事,算是一种改进,因为重启整个过程已经标准化到Hadoop内部,无需运维进行复杂的切换操作。
NameNode的切换通过代failover controller来实现。failover controller有多种实现,默认实现使用ZooKeeper来保证只有一个Namenode处于active状态。
每个Namenode运行一个轻量级的failover controller进程,该进程使用简单的心跳机制来监控Namenode的存活状态并在Namenode失败时触发failover。Failover可以由运维手动触发,
例如:日常维护中需要切换主Namenode,
- 这种手动的情况为 :graceful(优雅的) failover,
- 非手动触发的failover称为:ungraceful
failover。
在ungraceful failover的情况下, 没有办法确定失败(被判定为失败)的节点是否停止运行,也就是说触发failover后,之前的主Namenode可能还在运行。
QJM一次只允许一个Namenode写edit log,但是之前的主Namenode仍然可以接受读请求。Hadoop使用fencing来杀掉之前的Namenode。Fencing通过收回之前Namenode对共享的edit log的访问权限、关闭其网络端口使得原有的Namenode不能再继续接受服务请求。使用STONITH技术也可以将之前的主Namenode关机。
最后,HA方案中Namenode的切换对客户端来说是不可见的,前面已经介绍过,主要通过客户端库来完成。
感觉这篇文章有帮助到您的话,请点个赞!谢谢支持!
以上资料来源,有自己学习理解的,也有整合两位大佬的思路的,有对大佬原文感兴趣的小可爱,可以点击以下连接查看
参考文献1(特点 该大佬的文章讲解的比较简单易懂,容易看的进去)详情请点击连接:
参考文献2 (特点 该大佬的文章讲解的很专业且详细,需要耐心慢慢看)详情请点击连接:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









