







第一章 数据挖掘与大数据简介

大数据:大数据(Big data)是一个流行词或短语,用来描述大量的结构化和非结构化数据,这些数据大到难以使用传统数据库和软件技术处理。特征:海量性,多样性,实时性,不确定性
-
什么是数据挖掘
从大量的数据中挖掘那些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式和知识 -
知识发现过程
数据清理,数据集成,数据选择,数据变换,数据挖掘,模式评估,知识表示、
数据挖掘是知识发现的核心
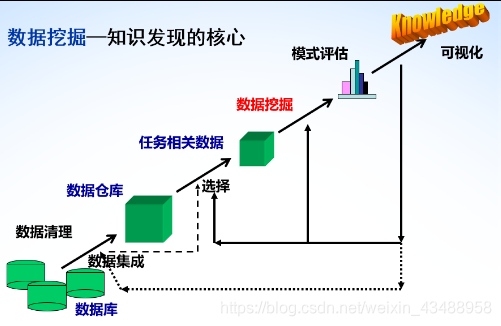
-
数据挖掘功能/任务
关联规则挖掘,聚类,分类/回归,噪声检测,孤立点分析等 -
数据挖掘的常识性知识

第二章 认识数据与数据预处理

2.1 认识数据
2.1.1 属性类型
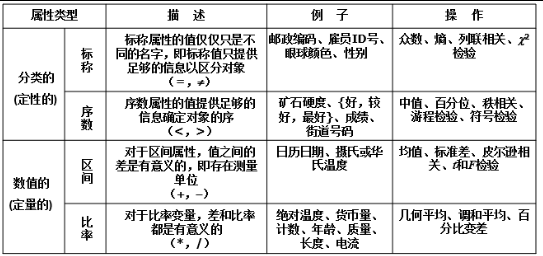
离散属性与连续属性:
取值是否连续(int, float等)
对称属性与非对称属性:
对称:0,1;男/女;非对称: 一个比另一个重要
2.1.2 数据集类型
- 记录数据
数据矩阵、文档数据、购物篮数据 - 图数据
万维网、分子结构 - 有序数据
时序数据、序列数据、基因序列数据、空间数据
2.1.3 数据的统计描述

- 数据的散步
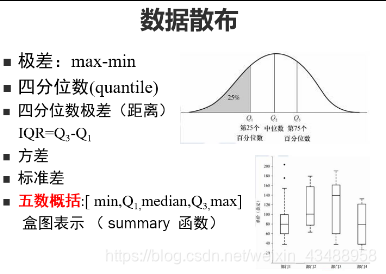
- 可视化
包括分位数图、分位数-分位数图(横向对比)、直方图、散点图等
2.1.4 数据的相似性度量
-
标称属性数据

-
二元变量属性数据
 example
example

-
序数型变量数据

-
数值属性数据

数据标准化

-
混合型数据

-
相似性度量方式

数据集成–相关分析
- 数值型数据—相关分析


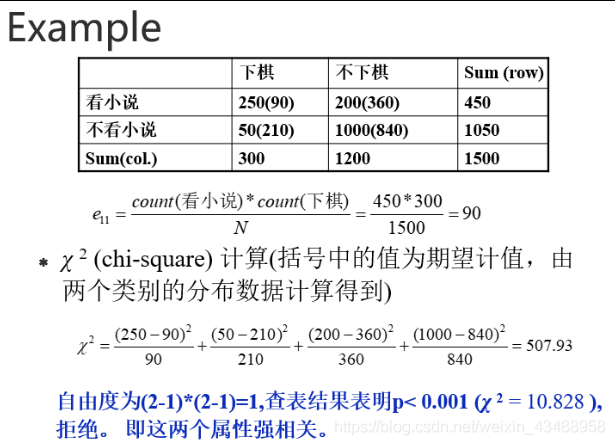
- 标称数据----卡方检验

2.2 数据预处理
- 主要任务

2.2.1 缺失值处理

2.2.2 特征筛选

信息熵—条件信息熵—信息增益

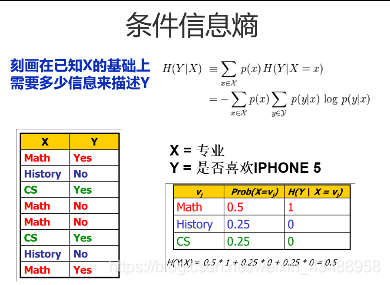


2.2.3 归一化

第三章 关联规则挖掘

3.1 几个重要概念
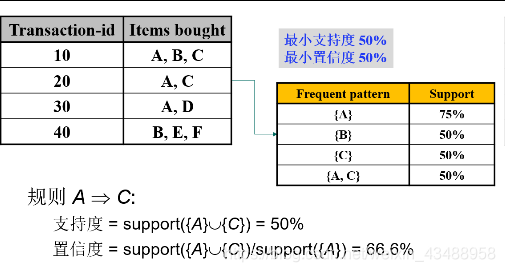
支持度、置信度、频繁项集、关联规则(掌握)
-
支持度
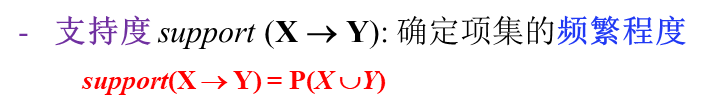
-
置信度


-
频繁项集(Frequent itemset)

-
关联规则

example
3.2 关联规则挖掘算法
- 关联规则挖掘

- 挖掘关联规则的一般步骤

3.2.1 Apriori(掌握)

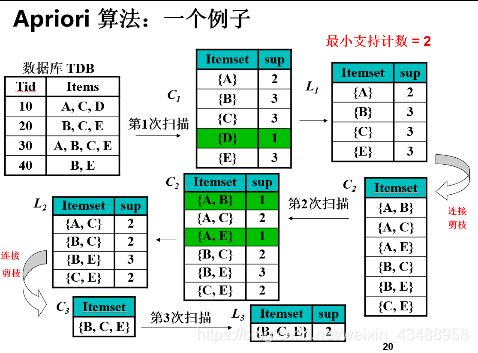
-计算复杂性

- 提高Apriori算法效率的方法
- 基于散列的技术
散列项集到对应的桶中,一个其hash桶的计数小于阈值k-itemset不可能是频繁的- 事务压缩
删除不可能对寻找频繁项集有用的事务(DB原始事务/记录)
不包含任何频繁k项集的事务不可能包含任何频繁k+1项集,可标记或删除- 划分
- 抽样


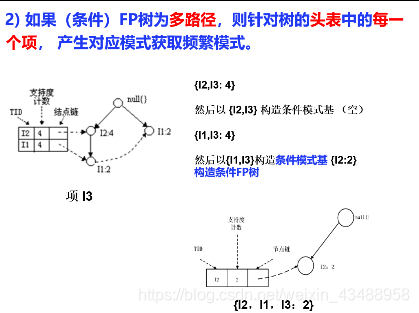
3.2.2 FP-Growth(理解)
-
构造

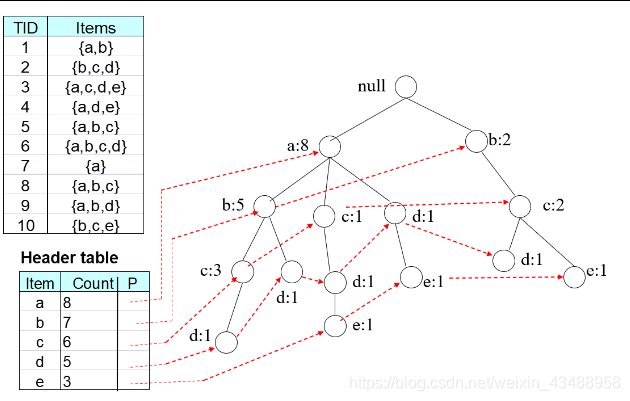
-
优缺点

-
频繁模式挖掘核心
(详细见黑皮书P168页)
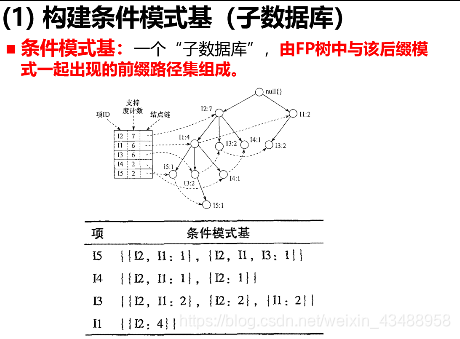
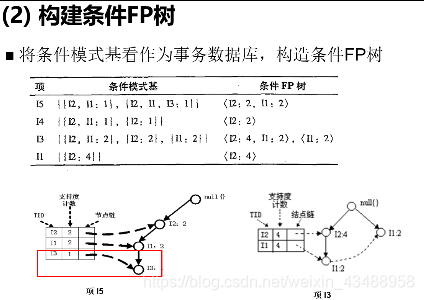
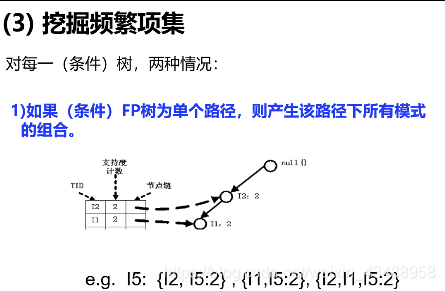
3.3 关联规则评估(理解)




第四章 分类/回归

- 分类 vs 预测
 - 监督学习和非监督学习
- 监督学习和非监督学习

-
模型分类

-
经典分类方法
(1)Decision Tree
(2)KNN
(3)Naive Bayes
(4)SVM
(5)ANN
4.1 Decision Tree
- 构造流程

- 属性选择度量

-
信息增益(ID3)

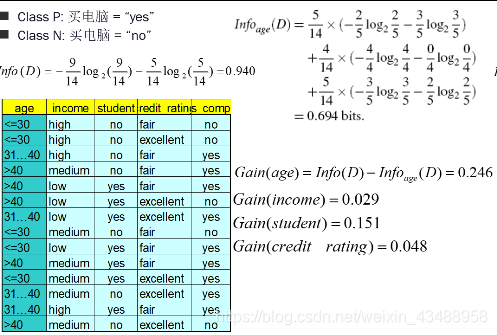
-
增益率(C4.5)

-
Gini指标(CART)

- 过拟合和剪枝

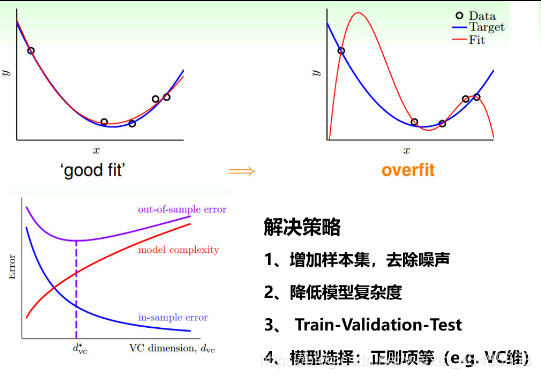


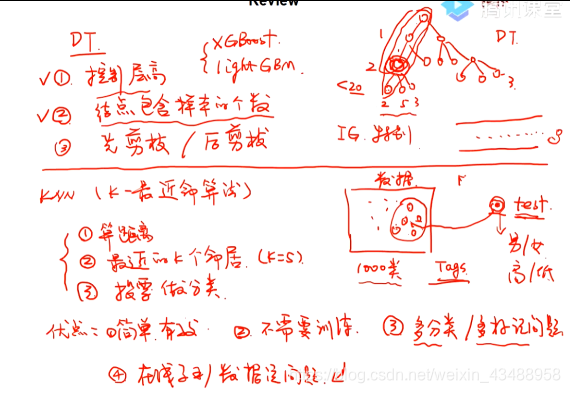
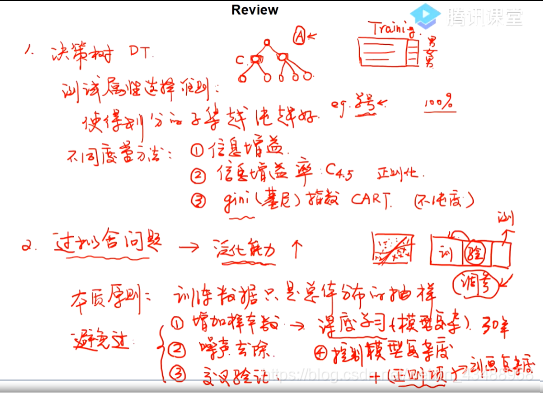
4.2 KNN
- 基本思想

- 常见问题



4.3 Naive Bayes

例题:黑皮书 P229


4.4 SVM
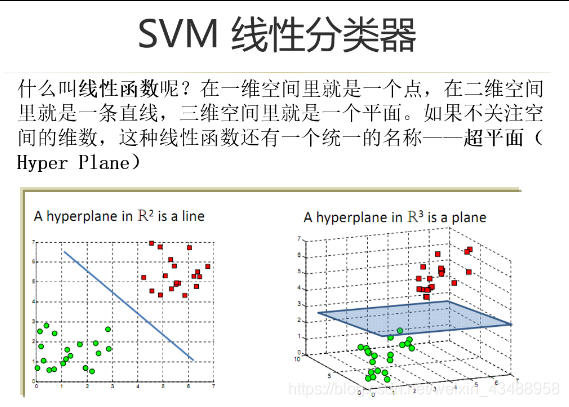
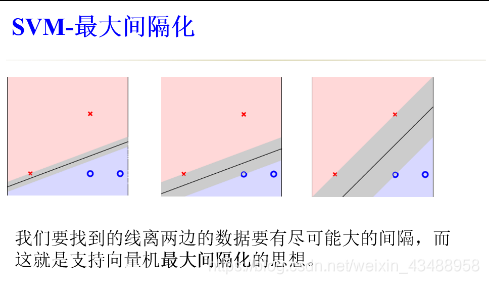

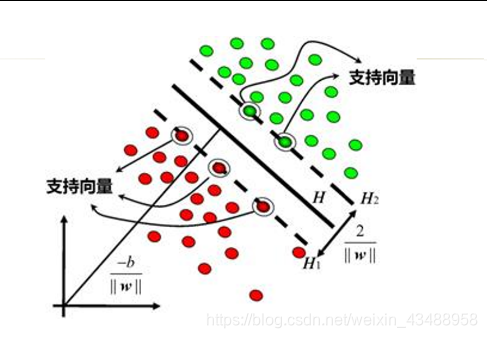




- 结构风险–经验风险


4.5 ANN
4.5.1 多层前馈神经网路
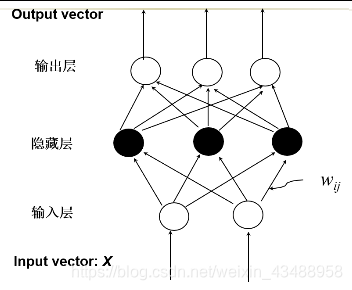

- 误差修正



4.5.2 感知机模型

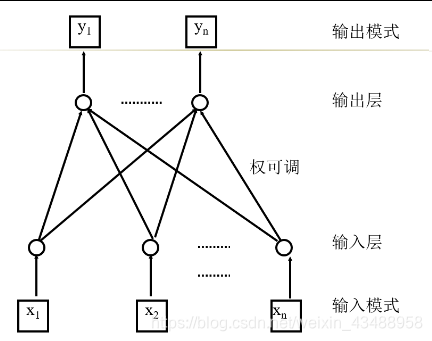

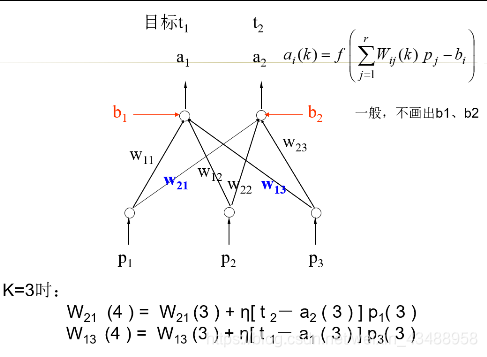
4.5.3 后向传播网络(BP)



- ANN优缺点

4.6 分类算法对比
| 分类算法 | 应用场景 | 优点 | 缺点 |
|---|---|---|---|
| 决策树 | 搜索排序,期权定价 | 超强的学习能力和泛化能力(对新样本的适应能力),训练速度快 | 易过拟合,改进为随机森林(Random Forest, RF) |
| KNN | 图像压缩 | 易于理解和实现,适合多分类问题 | 计算量大,复杂度高,不适合实时场景 |
| 朴素贝叶斯 | 文本分类(如:垃圾邮件识别) | 生成式模型,通过计算概率来进行分类,可以用来处理多分类问题,对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。 | 需要一个很强的条件独立性假设前提 |
| SVM | 高维文本分类,小样本分类 | 可以解决小样本情况下的机器学习问题,可以解决高维问题 可以避免神经网络结构选择和局部极小点问题 | 核函数敏感,不加修改的情况下只能做二分类 |
| ANN | 图像处理,模式识别 | 具有实现任何复杂非线性映射的功能 | 收敛速度慢、计算量大、训练时间长,易收敛到局部最优 |
4.7 集成学习

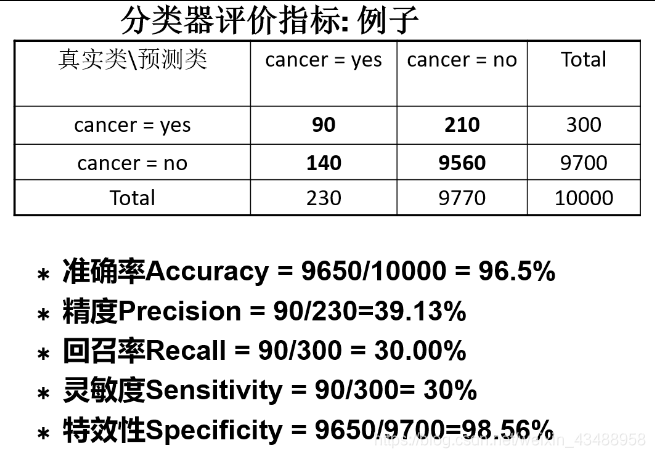
4.8 分类评价

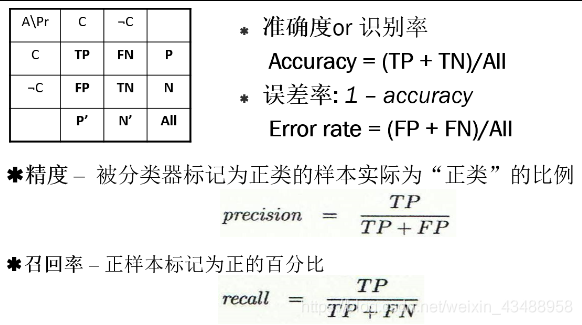


4.9 集成学习




第五章 聚类分析和噪声检测

5.1 聚类的概念及其算法(掌握)
什么是聚类?聚类算法的4大类型,分别的算法有哪些
-
聚类
就是将数据分为多个簇(Clusters),使得在同一个簇内对象之间具有较高的相似度,而不同簇之间的对象差别较大。 -
聚类算法分类

-
划分的方法代表算法:K-Means, K-Medoids

-
层次的方法代表算法:AGNES凝聚,DIANA分裂

-
基于密度的方法代表算法:DBSCAN

-
基于网格的方法代表算法: STING
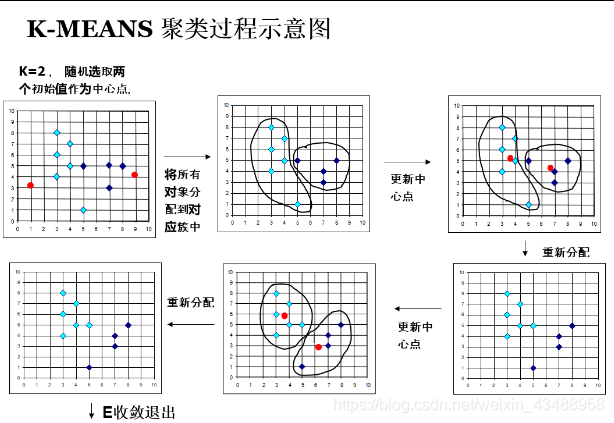
5.2 Kmeans聚类(掌握)


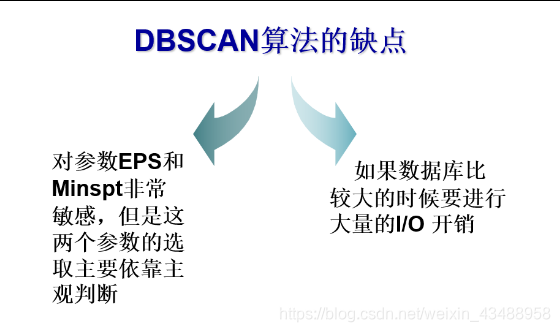
5.3 DBSCAN(理解)




5.4 聚类算法对比
| 聚类算法 | 应用场景 | 优点 | 缺点 |
|---|---|---|---|
| K-Means | 简单快速,对于大数据集,算法是相对可伸缩和高效率的 | 必须给定k值;对初值敏感,可能导致不同结果;不适合发现非球形状的簇或者大小差别很大的簇;对于噪声和孤立点数据是敏感的 | |
| DBSCAN | 可发现任意形状的簇,对噪声数据不敏感 | 算法复杂,如果数据库比较大的时候I/O开销大,对参数EPS和Minst非常敏感 |
5.5 离群点类型
全局离群点、情景离群点、集体离群点







第六章 大数据分析

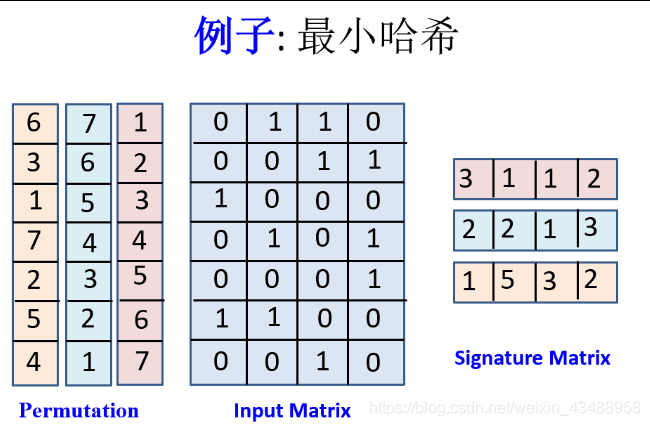
6.1 哈希技术
MinHash
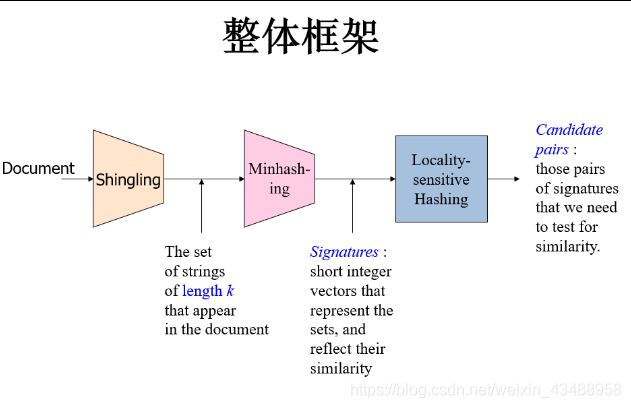



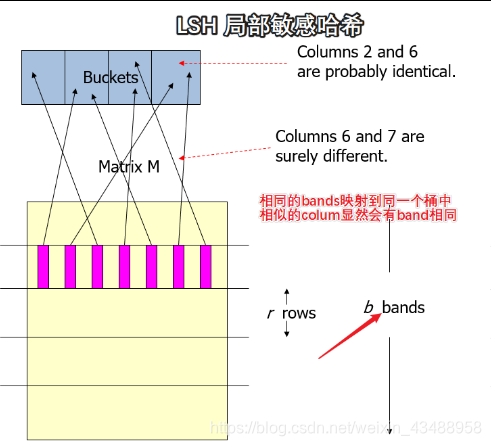
LSH
可行性理论证明

6.2 数据流挖掘
- 数据流

- 挑战

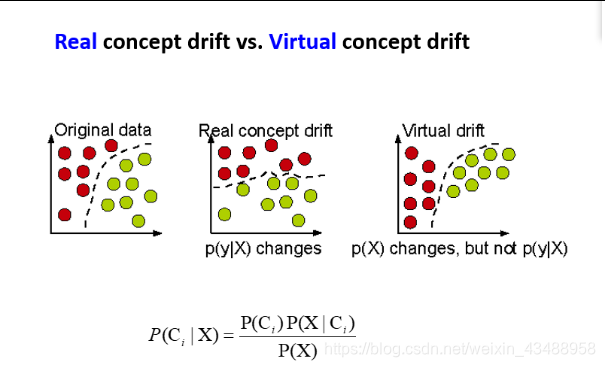
- 概念漂移
在预测分析和机器学习中,漂移的概念意味着目标变量的统计属性,也就是模型试图预测的,会随着时间以不可预见的方式发生变化。
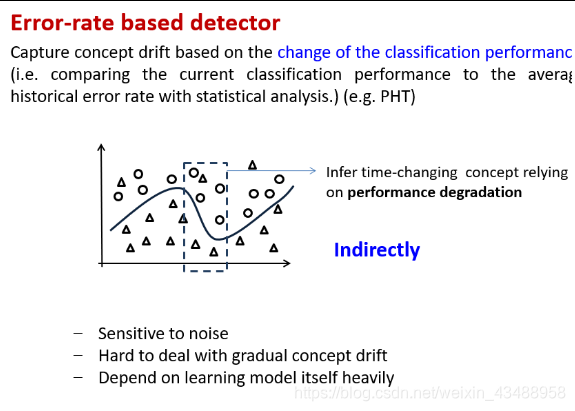
检测方法

- 分类

VFDT

6.3 Hadoop/Spark
-
什么是Hadoop/Spark


-
Hadoop设计准则


-
HDFS
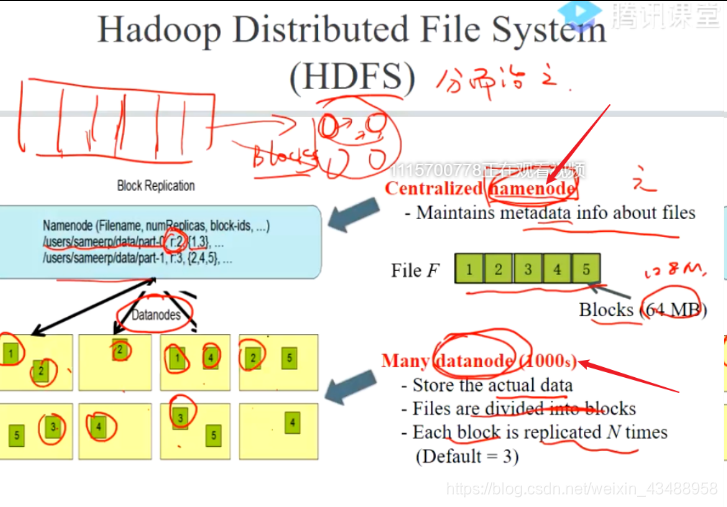
-
MapReduce
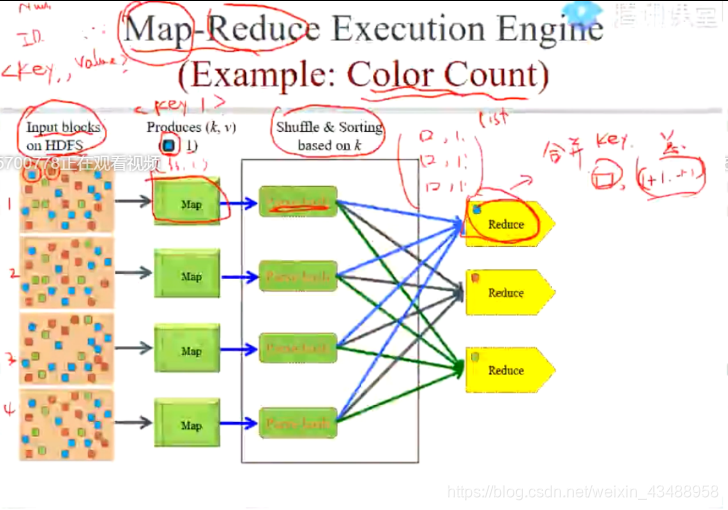

- MapReduce vs Spark


MapReduce 整个算法的瓶颈是不必要的数据读写,而Spark 主要改进的就是这一点。具体地,Spark 延续了MapReduce 的设计思路:对数据的计算也分为Map 和Reduce 两类。但不同的是,一个Spark 任务并不止包含一个Map 和一个Reduce,而是由一系列的Map、Reduce构成。这样,计算的中间结果可以高效地转给下一个计算步骤,提高算法性能。虽然Spark 的改进看似很小,但实验结果显示,它的算法性能相比MapReduce 提高了10~100 倍。
Spark将数据也存在HDFS,但读成RDD(弹性式分布数据集)格式,基于内存计算

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









