




 本文探讨了Java HashMap在JDK1.7和1.8中的resize()方法,主要区别在于1.8中优化了扩容策略。当HashMap达到阈值时,1.7会新建长度为原数组2倍的新数组,并重新计算每个元素的索引,而1.8则通过原位置+原数组长度快速确定新位置,避免了重新计算hash值,提高了效率。扩容过程保证了元素分布更均匀,减少了冲突。
本文探讨了Java HashMap在JDK1.7和1.8中的resize()方法,主要区别在于1.8中优化了扩容策略。当HashMap达到阈值时,1.7会新建长度为原数组2倍的新数组,并重新计算每个元素的索引,而1.8则通过原位置+原数组长度快速确定新位置,避免了重新计算hash值,提高了效率。扩容过程保证了元素分布更均匀,减少了冲突。
前言
对于HashMap的扩容问题,jdk1.7以及jdk1.8中是有区别的, jdk8中的HashMap相对于jdk7有比较大的更新。
resize()方法的作用
resize()方法会在HashMap的键值对达到“阈值”后进行数组扩容,而扩容时会调用resize()方法,此外,在jdk1.7中数组的容量是在HashMap初始化的时候就已经赋予,而在jdk1.8中是在put第一个元素的时候才会赋予数组容量,而put第一个元素的时候也会调用resize()方法。
resize()方法jdk1.8和1.7中实现有什么不同
JDK1.7
resize()源码


解释
在jdk1.7中,resize()方法的原理为:
1.先新建一个数组,数组长度为原数组的2倍。
2.循环遍历原数组的每一个键值对,得到键的hash值然后与新数组的长度进行&运算,这个方式是相对耗性能的,而在1.8中对这一步进行了优化。
JDK1.8
(此处本应该有完整的源码,但是太多,看得头晕,所以省去,直接讲关键代码和思路……)
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead; //这里很重要,新的位置为原老所处的位置+原数组的长度。下面解释
}
!!!重点:
newTab[j + oldCap] = hiHead;
解释
经过观测可以发现,我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,经过rehash之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
po两张找到的图解:


因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
为什么刚好原位置+原数组长度就会等于新的数组中的位置?
首先:
1.HashMap的数组长度恒定为2的n次方,也就是只会为2 4 8 16……这种数。
所以,即使创建时这样创建:
Map<String,String> hashMap = new HashMap<>(13);
最后数组长度也会变成16,而不是13。会取与传入的数最近的一个2次方的数。
由于:
0 & 1 = 0
0 & 0 = 0
所以源码中:
if ((e.hash & oldCap) == 0)
这一步是否为0只需要看元素的二进制数对应数组长度的二进制数1那个位置是否为0.
假设某个元素的hashcode为52:

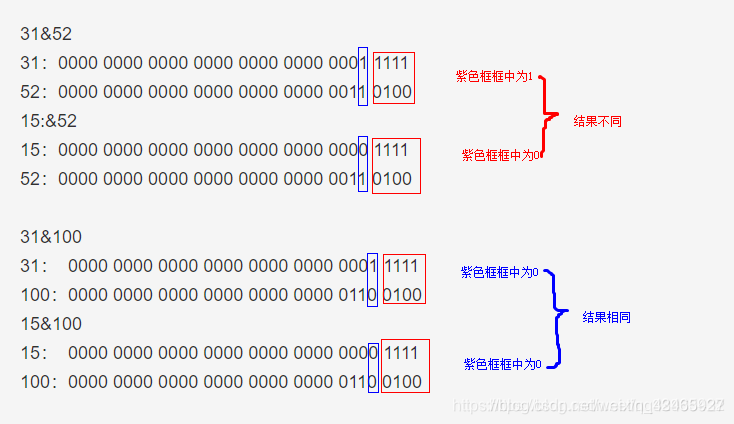
可以看到,扩容前和扩容后的位置是否一样完全取决于多出来的那一位是与新数组计算后值是为0还是1.为0则新位置与原位置相同,不需要换位置,不为零则需要换位置。而为什么新的位置是原位置+原数组长度,是因为每次换的位置只是前面多了一个1而已。为什么是前面多1,因为数组扩容为原来的两倍也是高位进1,比如15是0000 1111,而31就是0001 1111. 那么新位置的变化的高位进1位。而每一次高位进1都是在加上原数组长度的过程。
总结
jdk1.8中在计算新位置的时候并没有像1.7中那样重新进行hash运算,而是用了原位置+原数组长度这样巧妙的方式。这个结果与hash运算得到的结果是一致的,只是会更快。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









