







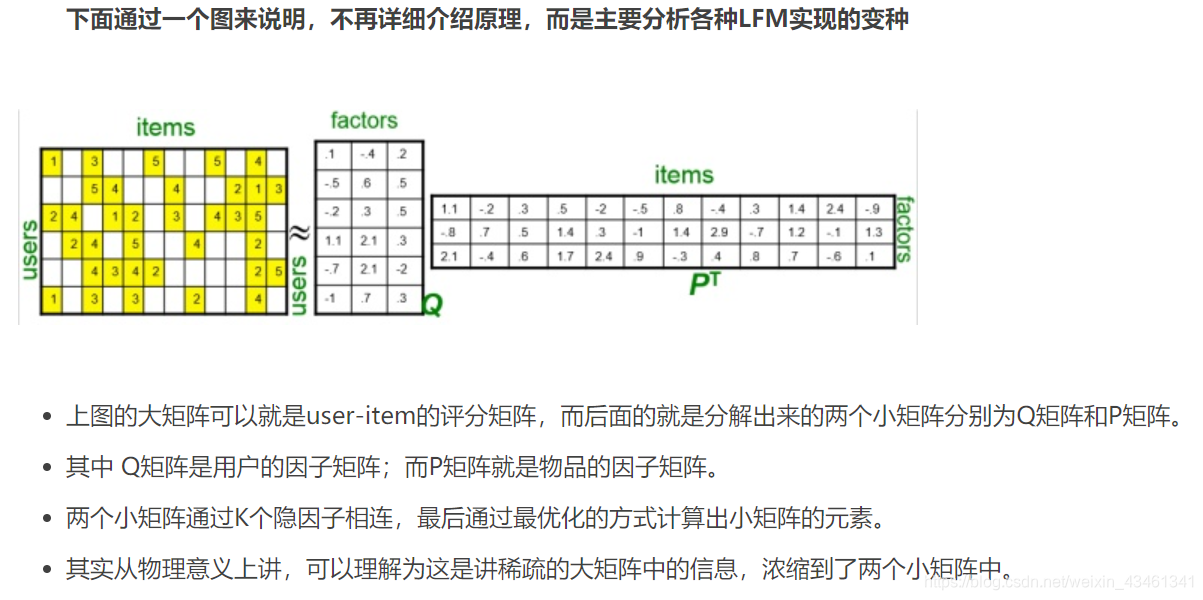
1.说明
在推荐系统中有两种协同过滤的方式。
一种是基于邻域的方式,这种方式又包含了基于用户的和基于物品的,这种方式实现简单,而且效果也是非常的不错,唯一的缺点是对待稀疏矩阵的时候表现乏力。因此诞生了下面的方式。
方式二是基于模型的方式,也就是矩阵分解的方式,这种方式将推荐问题转化为了机器学习问题。

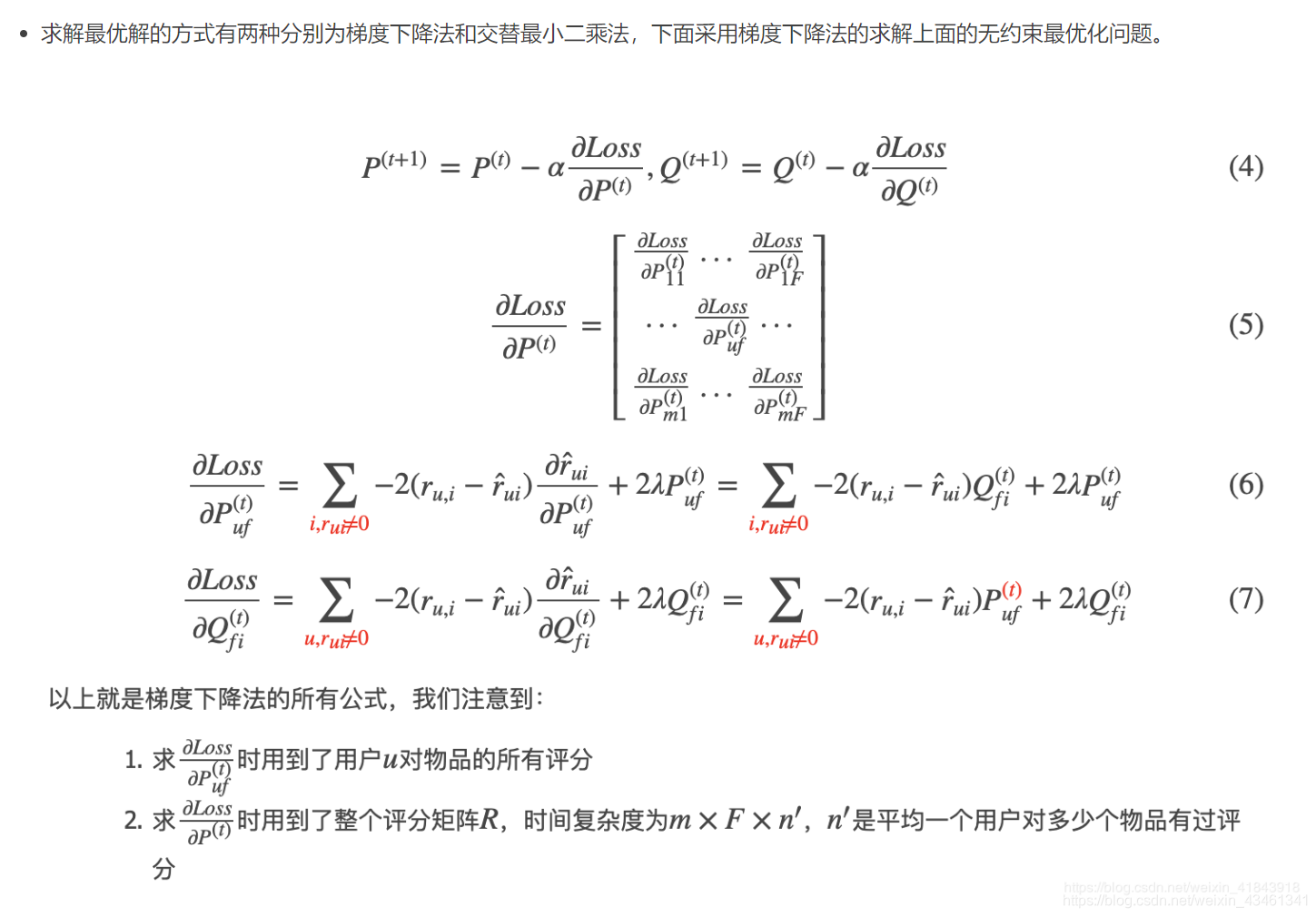
为了防止overfitting,添加正则项控制过拟合。
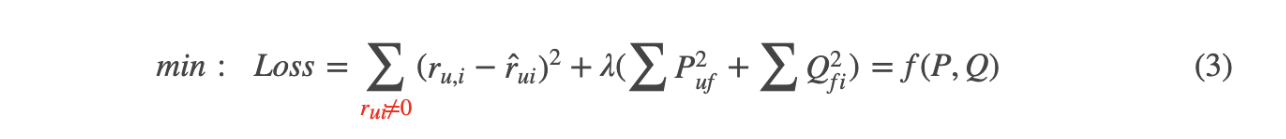


_coding:utf-8 _
author = “ricky”
import random
import math
class LFM(object):
def __init__(self, rating_data, F, alpha=0.1, lmbd=0.1, max_iter=500):
"""
:param rating_data: rating_data是[(user,[(item,rate)]]类型
:param F: 隐因子个数
:param alpha: 学习率
:param lmbd: 正则化
:param max_iter:最大迭代次数
"""
self.F = F
self.P = dict() # R=PQ^T,代码中的Q相当于博客中Q的转置
self.Q = dict()
self.alpha = alpha
self.lmbd = lmbd
self.max_iter = max_iter
self.rating_data = rating_data
'''随机初始化矩阵P和Q'''
for user, rates in self.rating_data:
self.P[user] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
for item, _ in rates:
if item not in self.Q:
self.Q[item] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
def train(self):
"""
随机梯度下降法训练参数P和Q
:return:
"""
for step in range(self.max_iter):
for user, rates in self.rating_data:
for item, rui in rates:
hat_rui = self.predict(user, item)
err_ui = rui - hat_rui
for f in range(self.F):
self.P[user][f] += self.alpha * (err_ui * self.Q[item][f] - self.lmbd * self.P[user][f])
self.Q[item][f] += self.alpha * (err_ui * self.P[user][f] - self.lmbd * self.Q[item][f])
self.alpha *= 0.9 # 每次迭代步长要逐步缩小
def predict(self, user, item):
"""
:param user:
:param item:
:return:
预测用户user对物品item的评分
"""
return sum(self.P[user][f] * self.Q[item][f] for f in range(self.F))
if name == ‘main’:
‘’‘用户有A B C,物品有a b c d’’’
rating_data = list()
rate_A = [(‘a’, 1.0), (‘b’, 1.0)]
rating_data.append((‘A’, rate_A))
rate_B = [(‘b’, 1.0), (‘c’, 1.0)]
rating_data.append((‘B’, rate_B))
rate_C = [(‘c’, 1.0), (‘d’, 1.0)]
rating_data.append((‘C’, rate_C))
lfm = LFM(rating_data, 2)
lfm.train()
for item in ['a', 'b', 'c', 'd']:
print(item, lfm.predict('A', item)) # 计算用户A对各个物品的喜好程度


* coding:utf-8 *
author = “Ricky”
import random
import math
class BiasLFM(object):
def __init__(self, rating_data, F, alpha=0.1, lmbd=0.1, max_iter=500):
'''rating_data是list<(user,list<(position,rate)>)>类型
'''
self.F = F
self.P = dict()
self.Q = dict() # 相当于博客中Q的转置
self.bu = dict()
self.bi = dict()
self.alpha = alpha
self.lmbd = lmbd
self.max_iter = max_iter
self.rating_data = rating_data
self.mu = 0.0
'''随机初始化矩阵P和Q'''
cnt = 0
for user, rates in self.rating_data:
self.P[user] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
self.bu[user] = 0
cnt += len(rates)
for item, rate in rates:
self.mu += rate
if item not in self.Q:
self.Q[item] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
self.bi[item] = 0
self.mu /= cnt
def train(self):
'''随机梯度下降法训练参数P和Q
'''
for step in range(self.max_iter):
for user, rates in self.rating_data:
for item, rui in rates:
hat_rui = self.predict(user, item)
err_ui = rui - hat_rui
# 更新偏置
self.bu[user] += self.alpha * (err_ui - self.lmbd * self.bu[user])
self.bi[item] += self.alpha * (err_ui - self.lmbd * self.bi[item])
for f in range(self.F):
# 更新P、Q
self.P[user][f] += self.alpha * (err_ui * self.Q[item][f] - self.lmbd * self.P[user][f])
self.Q[item][f] += self.alpha * (err_ui * self.P[user][f] - self.lmbd * self.Q[item][f])
self.alpha *= 0.9 # 每次迭代步长要逐步缩小
def predict(self, user, item):
'''预测用户user对物品item的评分
'''
return sum(self.P[user][f] * self.Q[item][f] for f in range(self.F)) + self.bu[user] + self.bi[item] + self.mu
if name == ‘main’:
‘’‘用户有A B C,物品有a b c d’’’
rating_data = list()
rate_A = [(‘a’, 1.0), (‘b’, 1.0)]
rating_data.append((‘A’, rate_A))
rate_B = [(‘b’, 1.0), (‘c’, 1.0)]
rating_data.append((‘B’, rate_B))
rate_C = [(‘c’, 1.0), (‘d’, 1.0)]
rating_data.append((‘C’, rate_C))
lfm = BiasLFM(rating_data, 2)
lfm.train()
for item in ['a', 'b', 'c', 'd']:
print(item, lfm.predict('A', item)) # 计算用户A对各个物品的喜好程度


coding:utf-8
author = “ricky”
import random
import math
class SVDPP(object):
def __init__(self, rating_data, F, alpha=0.1, lmbd=0.1, max_iter=500):
'''rating_data是list<(user,list<(position,rate)>)>类型
'''
self.F = F
self.P = dict()
self.Q = dict() # 相当于博客中Q的转置
self.Y = dict()
self.bu = dict()
self.bi = dict()
self.alpha = alpha
self.lmbd = lmbd
self.max_iter = max_iter
self.rating_data = rating_data
self.mu = 0.0
'''随机初始化矩阵P、Q、Y'''
cnt = 0
for user, rates in self.rating_data:
self.P[user] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
self.bu[user] = 0
cnt += len(rates)
for item, rate in rates:
self.mu += rate
if item not in self.Q:
self.Q[item] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
if item not in self.Y:
self.Y[item] = [random.random() / math.sqrt(self.F)
for x in range(self.F)]
self.bi[item] = 0
self.mu /= cnt
def train(self):
'''随机梯度下降法训练参数P和Q
'''
for step in range(self.max_iter):
for user, rates in self.rating_data:
z = [0.0 for f in range(self.F)]
for item, _ in rates:
for f in range(self.F):
z[f] += self.Y[item][f]
ru = 1.0 / math.sqrt(1.0 * len(rates))
s = [0.0 for f in range(self.F)]
for item, rui in rates:
hat_rui = self.predict(user, item, rates)
err_ui = rui - hat_rui
self.bu[user] += self.alpha * (err_ui - self.lmbd * self.bu[user])
self.bi[item] += self.alpha * (err_ui - self.lmbd * self.bi[item])
for f in range(self.F):
s[f] += self.Q[item][f] * err_ui
self.P[user][f] += self.alpha * (err_ui * self.Q[item][f] - self.lmbd * self.P[user][f])
self.Q[item][f] += self.alpha * (
err_ui * (self.P[user][f] + z[f] * ru) - self.lmbd * self.Q[item][f])
for item, _ in rates:
for f in range(self.F):
self.Y[item][f] += self.alpha * (s[f] * ru - self.lmbd * self.Y[item][f])
self.alpha *= 0.9 # 每次迭代步长要逐步缩小
def predict(self, user, item, ratedItems):
'''预测用户user对物品item的评分
'''
z = [0.0 for f in range(self.F)]
for ri, _ in ratedItems:
for f in range(self.F):
z[f] += self.Y[ri][f]
return sum(
(self.P[user][f] + z[f] / math.sqrt(1.0 * len(ratedItems))) * self.Q[item][f] for f in range(self.F)) + \
self.bu[user] + self.bi[item] + self.mu
if name == ‘main’:
‘’‘用户有A B C,物品有a b c d’’’
rating_data = list()
rate_A = [(‘a’, 1.0), (‘b’, 1.0)]
rating_data.append((‘A’, rate_A))
rate_B = [(‘b’, 1.0), (‘c’, 1.0)]
rating_data.append((‘B’, rate_B))
rate_C = [(‘c’, 1.0), (‘d’, 1.0)]
rating_data.append((‘C’, rate_C))
lfm = SVDPP(rating_data, 2)
lfm.train()
for item in ['a', 'b', 'c', 'd']:
print(item, lfm.predict('A', item, rate_A) ) # 计算用户A对各个物品的喜好程度

//显性反馈模型
val model1 = ALS.train(ratings, rank, numIterations, lambda)
//隐性反馈模型
val model2 = ALS.trainImplicit(ratings, rank, numIterations, lambda, alpha)


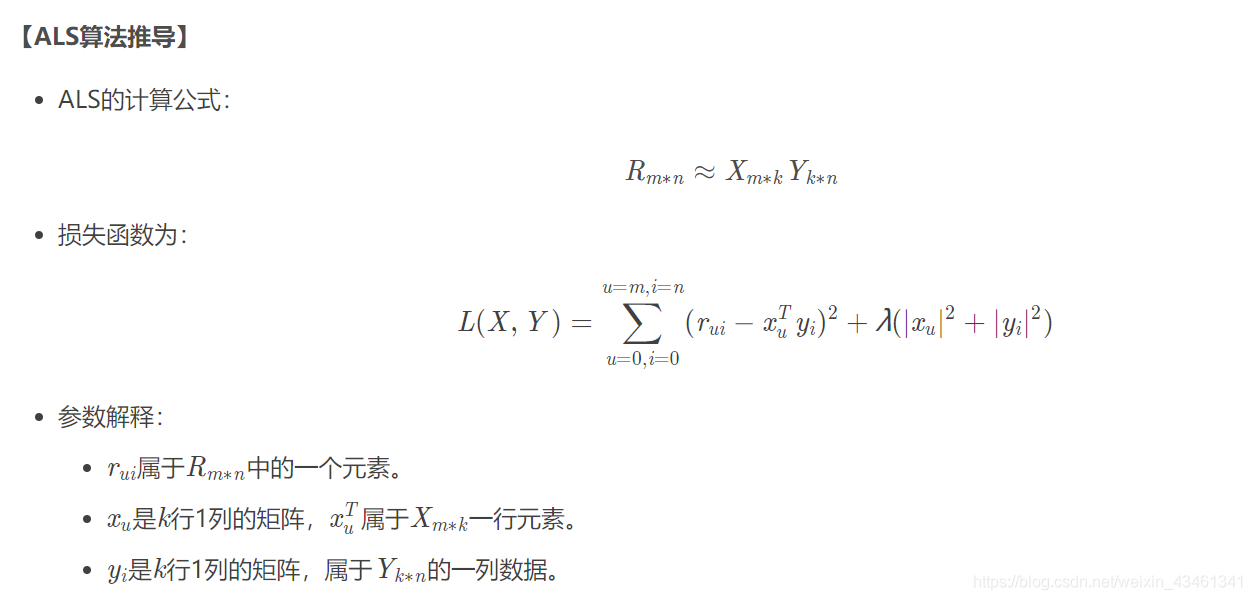



















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









